前言
2000年,伊利诺伊大学厄巴纳-香槟分校(University of Illinois at Urbana-Champaign 简称UIUC)这所享有世界声望的一流公立研究型大学的 Chris Lattner(他的 twitter @clattner_llvm ) 开发了一个叫作 Low Level Virtual Machine 的编译器开发工具套件,后来涉及范围越来越大,可以用于常规编译器,JIT编译器,汇编器,调试器,静态分析工具等一系列跟编程语言相关的工作,于是就把简称 LLVM 这个简称作为了正式的名字。Chris Lattner 后来又开发了 Clang,使得 LLVM 直接挑战 GCC 的地位。2012年,LLVM 获得美国计算机学会 ACM 的软件系统大奖,和 UNIX,WWW,TCP/IP,Tex,JAVA 等齐名。
Chris Lattner 生于 1978 年,2005年加入苹果,将苹果使用的 GCC 全面转为 LLVM。2010年开始主导开发 Swift 语言。
iOS 开发中 Objective-C 是 Clang / LLVM 来编译的。
swift 是 Swift / LLVM,其中 Swift 前端会多出 SIL optimizer,它会把 .swift 生成的中间代码 .sil 属于 High-Level IR, 因为 swift 在编译时就完成了方法绑定直接通过地址调用属于强类型语言,方法调用不再是像OC那样的消息发送,这样编译就可以获得更多的信息用在后面的后端优化上。
LLVM是一个模块化和可重用的编译器和工具链技术的集合,Clang 是 LLVM 的子项目,是 C,C++ 和 Objective-C 编译器,目的是提供惊人的快速编译,比 GCC 快3倍,其中的 clang static analyzer 主要是进行语法分析,语义分析和生成中间代码,当然这个过程会对代码进行检查,出错的和需要警告的会标注出来。LLVM 核心库提供一个优化器,对流行的 CPU 做代码生成支持。lld 是 Clang / LLVM 的内置链接器,clang 必须调用链接器来产生可执行文件。
LLVM 比较有特色的一点是它能提供一种代码编写良好的中间表示 IR,这意味着它可以作为多种语言的后端,这样就能够提供语言无关的优化同时还能够方便的针对多种 CPU 的代码生成。
LLVM 还用在 Gallium3D 中进行 JIT 优化,Xorg 中的 pixman 也有考虑使用 LLVM 优化执行速度, LLVM-Lua 用LLVM 来编译 lua 代码, gpuocelot 使用 LLVM 可以让 CUDA 程序无需重新编译就能够在多种 CPU 机器上跑。
这里是 Clang 官方详细文档: Welcome to Clang’s documentation! — Clang 4.0 documentation
这篇是对 LLVM 架构的一个概述: The Architecture of Open Source Applications
将编译器之前对于编译的前世今生也是需要了解的,比如回答下这个问题,编译器程序是用什么编译的?看看 《linkers and loaders》 这本书就知道了。
编译流程
在列出完整步骤之前可以先看个简单例子。看看是如何完成一次编译的。
#import <Foundation/Foundation.h>
#define DEFINEEight 8
int main(){
@autoreleasepool {
int eight = DEFINEEight;
int six = 6;
NSString* site = [[NSString alloc] initWithUTF8String:”starming”];
int rank = eight + six;
NSLog(@“%@ rank %d”, site, rank);
}
return 0;
}在命令行输入
clang -ccc-print-phases main.m可以看到编译源文件需要的几个不同的阶段
0: input, “main.m”, objective-c
1: preprocessor, {0}, objective-c-cpp-output
2: compiler, {1}, ir
3: backend, {2}, assembler
4: assembler, {3}, object
5: linker, {4}, image
6: bind-arch, “x86_64”, {5}, image这样能够了解到过程和重要的信息。
查看oc的c实现可以使用如下命令
clang -rewrite-objc main.m查看操作内部命令,可以使用 -### 命令
clang -### main.m -o main想看清clang的全部过程,可以先通过-E查看clang在预编译处理这步做了什么。
clang -E main.m执行完后可以看到文件
# 1 “/System/Library/Frameworks/Foundation.framework/Headers/FoundationLegacySwiftCompatibility.h” 1 3
# 185 “/System/Library/Frameworks/Foundation.framework/Headers/Foundation.h” 2 3
# 2 “main.m” 2
int main(){
@autoreleasepool {
int eight = 8;
int six = 6;
NSString* site = [[NSString alloc] initWithUTF8String:”starming”];
int rank = eight + six;
NSLog(@“%@ rank %d”, site, rank);
}
return 0;
}这个过程的处理包括宏的替换,头文件的导入。下面这些代码也会在这步处理。
- “#define”
- “#include”
- “#indef”
- 注释
- “#pragma”
预处理完成后就会进行词法分析,这里会把代码切成一个个 Token,比如大小括号,等于号还有字符串等。
clang -fmodules -fsyntax-only -Xclang -dump-tokens main.m然后是语法分析,验证语法是否正确,然后将所有节点组成抽象语法树 AST 。
clang -fmodules -fsyntax-only -Xclang -ast-dump main.m完成这些步骤后就可以开始IR中间代码的生成了,CodeGen 会负责将语法树自顶向下遍历逐步翻译成 LLVM IR,IR 是编译过程的前端的输出后端的输入。
clang -S -fobjc-arc -emit-llvm main.m -o main.ll这里 LLVM 会去做些优化工作,在 Xcode 的编译设置里也可以设置优化级别-01,-03,-0s,还可以写些自己的 Pass,官方有比较完整的 Pass 教程: Writing an LLVM Pass — LLVM 5 documentation 。
clang -O3 -S -fobjc-arc -emit-llvm main.m -o main.llPass 是 LLVM 优化工作的一个节点,一个节点做些事,一起加起来就构成了 LLVM 完整的优化和转化。
如果开启了 bitcode 苹果会做进一步的优化,有新的后端架构还是可以用这份优化过的 bitcode 去生成。
clang -emit-llvm -c main.m -o main.bc生成汇编
clang -S -fobjc-arc main.m -o main.s生成目标文件
clang -fmodules -c main.m -o main.o生成可执行文件,这样就能够执行看到输出结果
clang main.o -o main
执行
./main
输出
starming rank 14下面是完整步骤:
- 编译信息写入辅助文件,创建文件架构 .app 文件
- 处理文件打包信息
- 执行 CocoaPod 编译前脚本,checkPods Manifest.lock
- 编译.m文件,使用 CompileC 和 clang 命令
- 链接需要的 Framework
- 编译 xib
- 拷贝 xib ,资源文件
- 编译 ImageAssets
- 处理 info.plist
- 执行 CocoaPod 脚本
- 拷贝标准库
- 创建 .app 文件和签名
Clang 编译 .m 文件
在 Xcode 编译过后,可以通过 Show the report navigator 里对应 target 的 build 中查看每个 .m 文件的 clang 参数信息,这些参数都是通过Build Setting。
具体拿编译 AFSecurityPolicy.m 的信息来看看。首先对任务进行描述。
CompileC DerivedData path/AFSecurityPolicy.o AFNetworking/AFNetworking/AFSecurityPolicy.m normal x86_64 objective-c com.apple.compilers.llvm.clang.1_0.compiler接下来对会更新工作路径,同时设置 PATH
cd /Users/didi/Documents/Demo/GitHub/GCDFetchFeed/GCDFetchFeed/Pods
export LANG=en_US.US-ASCII
export PATH=“/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform/Developer/usr/bin:/Applications/Xcode.app/Contents/Developer/usr/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin”接下来就是实际的编译命令
clang -x objective-c -arch x86_64 -fmessage-length=0 -fobjc-arc… -Wno-missing-field-initializers … -DDEBUG=1 … -isysroot iPhoneSimulator10.1.sdk -fasm-blocks … -I -F -c AFSecurityPolicy.m -o AFSecurityPolicy.oclang 命令参数
-x 编译语言比如objective-c
-arch 编译的架构,比如arm7
-f 以-f开头的。
-W 以-W开头的,可以通过这些定制编译警告
-D 以-D开头的,指的是预编译宏,通过这些宏可以实现条件编译
-iPhoneSimulator10.1.sdk 编译采用的iOS SDK版本
-I 把编译信息写入指定的辅助文件
-F 需要的Framework
-c 标识符指明需要运行预处理器,语法分析,类型检查,LLVM生成优化以及汇编代码生成.o文件
-o 编译结果构建 Target
编译工程中的第三方依赖库后会构建我们程序的 target,会按顺序输出如下的信息:
Create product structure
Process product packaging
Run custom shell script ‘Check Pods Manifest.lock’
Compile … 各个项目中的.m文件
Link /Users/… 路径
Copy … 静态文件
Compile asset catalogs
Compile Storyboard file …
Process info.plist
Link Storyboards
Run custom shell script ‘Embed Pods Frameworks’
Run custom shell script ‘Copy Pods Resources’
…
Touch GCDFetchFeed.app
Sign GCDFetchFeed.app从这些信息可以看出在这些步骤中会分别调用不同的命令行工具来执行。
Target 在 Build 过程的控制
在 Xcode 的 Project editor 中的 Build Setting,Build Phases 和 Build Rules 能够控制编译的过程。
Build Phases
构建可执行文件的规则。指定 target 的依赖项目,在 target build 之前需要先 build 的依赖。在 Compile Source 中指定所有必须编译的文件,这些文件会根据 Build Setting 和 Build Rules 里的设置来处理。
在 Link Binary With Libraries 里会列出所有的静态库和动态库,它们会和编译生成的目标文件进行链接。
build phase 还会把静态资源拷贝到 bundle 里。
可以通过在 build phases 里添加自定义脚本来做些事情,比如像 CocoaPods 所做的那样。
Build Rules
指定不同文件类型如何编译。每条 build rule 指定了该类型如何处理以及输出在哪。可以增加一条新规则对特定文件类型添加处理方法。
Build Settings
在 build 的过程中各个阶段的选项的设置。
pbxproj工程文件
build 过程控制的这些设置都会被保存在工程文件 .pbxproj 里。在这个文件中可以找 rootObject 的 ID 值
rootObject = 3EE311301C4E1F0800103FA3 /* Project object */;然后根据这个 ID 找到 main 工程的定义。
/* Begin PBXProject section */
3EE311301C4E1F0800103FA3 /* Project object */ = {
isa = PBXProject;
…
/* End PBXProject section */在 targets 里会指向各个 taget 的定义
targets = (
3EE311371C4E1F0800103FA3 /* GCDFetchFeed */,
3EE311501C4E1F0800103FA3 /* GCDFetchFeedTests */,
3EE3115B1C4E1F0800103FA3 /* GCDFetchFeedUITests */,
);顺着这些 ID 就能够找到更详细的定义地方。比如我们通过 GCDFetchFeed 这个 target 的 ID 找到定义如下:
3EE311371C4E1F0800103FA3 /* GCDFetchFeed */ = {
isa = PBXNativeTarget;
buildConfigurationList = 3EE311651C4E1F0800103FA3 /* configuration list for PBXNativeTarget “GCDFetchFeed”
buildPhases = (
9527AA01F4AAE11E18397E0C /* Check Pods st.lock */,
3EE311341C4E1F0800103FA3 /* Sources */,
3EE311351C4E1F0800103FA3 /* Frameworks */,
3EE311361C4E1F0800103FA3 /* Resources */,
C3DDA7C46C0308459A18B7D9 /* Embed Pods Frameworks
DD33A716222617FAB49F1472 /* Copy Pods Resources
);
buildRules = (
);
dependencies = (
);
name = GCDFetchFeed;
productName = GCDFetchFeed;
productReference = 3EE311381C4E1F0800103FA3 /* chFeed.app */;
productType = “com.apple.product-type.application”;
};这个里面又有更多的 ID 可以得到更多的定义,其中 buildConfigurationList 指向了可用的配置项,包含 Debug 和 Release。可以看到还有 buildPhases,buildRules 和 dependencies 都能够通过这里索引找到更详细的定义。
接下来详细的看看 Clang 所做的事情吧。
Clang Static Analyzer静态代码分析
可以在 llvm/clang/ Source Tree - Woboq Code Browser 上查看 Clang 的代码。
Youtube上一个教程:The Clang AST - a Tutorial - YouTube
CMU关于llvm的教案 http://www.cs.cmu.edu/afs/cs.cmu.edu/academic/class/15745-s14/public/lectures/
静态分析前会对源代码分词成 Token,这个过程称为词法分析(Lexical Analysis),在 TokensKind.def 里有 Clang 定义的所有 Token。Token 可以分为以下几类
- 关键字:语法中的关键字,if else while for 等。
- 标识符:变量名
- 字面量:值,数字,字符串
- 特殊符号:加减乘除等符号
通过下面的命令可以输出所有 token 和所在文件具体位置,命令如下。
clang -fmodules -E -Xclang -dump-tokens main.m可以获得每个 token 的类型,值还有类似 StartOfLine 的位置类型和 Loc=main.m:11:1 这个样的具体位置。
接着进行语法分析(Semantic Analysis)将 token 先按照语法组合成语义生成 VarDecl 节点,然后将这些节点按照层级关系构成抽象语法树 Abstract Syntax Tree (AST)。
打个比方,如果遇到 token 是 = 符号进行赋值的处理,遇到加减乘除就先处理乘除,然后处理加减,这些组合经过嵌套后会生成一个语法数的结构。这个过程完成后会进行赋值操作时类型是不是匹配的处理。
打印语法树的命令
clang -fmodules -fsyntax-only -Xclang -ast-dump main.mTranslationUnitDecl 是根节点,表示一个源文件。Decl 表示一个声明,Expr 表示表达式,Literal 表示字面量是特殊的 Expr,Stmt 表示语句。
clang 静态分析是通过建立分析引擎和 checkers 所组成的架构,这部分功能可以通过 clang —analyze 命令方式调用。clang static analyzer 分为 analyzer core 分析引擎和 checkers 两部分,所有 checker 都是基于底层分析引擎之上,通过分析引擎提供的功能能够编写新的 checker。
可以通过 clang —analyze -Xclang -analyzer-checker-help 来列出当前 clang 版本下所有 checker。如果想编写自己的 checker,可以在 clang 项目的 lib / StaticAnalyzer / Checkers 目录下找到实例参考,比如 ObjCUnusedIVarsChecker.cpp 用来检查未使用定义过的变量。这种方式能够方便用户扩展对代码检查规则或者对 bug 类型进行扩展,但是这种架构也有不足,每执行完一条语句后,分析引擎会遍历所有 checker 中的回调函数,所以 checker 越多,速度越慢。通过 clang -cc1 -analyzer-checker-help 可以列出能调用的 checker,下面是常用 checker
debug.ConfigDumper Dump config table
debug.DumpCFG Display Control-Flow Graphs
debug.DumpCallGraph Display Call Graph
debug.DumpCalls Print calls as they are traversed by the engine
debug.DumpDominators Print the dominance tree for a given CFG
debug.DumpLiveVars Print results of live variable analysis
debug.DumpTraversal Print branch conditions as they are traversed by the engine
debug.ExprInspection Check the analyzer's understanding of expressions
debug.Stats Emit warnings with analyzer statistics
debug.TaintTest Mark tainted symbols as such.
debug.ViewCFG View Control-Flow Graphs using GraphViz
debug.ViewCallGraph View Call Graph using GraphViz
debug.ViewExplodedGraph View Exploded Graphs using GraphViz这些 checker 里最常用的是 DumpCFG,DumpCallGraph,DumpLiveVars 和 DumpViewExplodedGraph。
clang static analyzer 引擎大致分为 CFG,MemRegion,SValBuilder,ConstraintManager 和 ExplodedGraph 几个模块。clang static analyzer 本质上就是 path-sensitive analysis,要很好的理解 clang static analyzer 引擎就需要对 Data Flow Analysis 有所了解,包括迭代数据流分析,path-sensitive,path-insensitive ,flow-sensitive等。
编译的概念(词法->语法->语义->IR->优化->CodeGen)在 clang static analyzer 里到处可见,例如 Relaxed Live Variables Analysis 可以减少分析中的内存消耗,使用 mark-sweep 实现 Dead Symbols 的删除。
clang static analyzer 提供了很多辅助方法,比如 SVal.dump(),MemRegion.getString 以及 Stmt 和 Dcel 提供的 dump 方法。Clang 抽象语法树 Clang AST 常见的 API 有 Stmt,Decl,Expr 和 QualType。在编写 checker 时会遇到 AST 的层级检查,这时有个很好的接口 StmtVisitor,这个接口类似 RecursiveASTVisitor。
整个 clang static analyzer 的入口是 AnalysisConsumer,接着会调 HandleTranslationUnit() 方法进行 AST 层级进行分析或者进行 path-sensitive 分析。默认会按照 inline 的 path-sensitive 分析,构建 CallGraph,从顶层 caller 按照调用的关系来分析,具体是使用的 WorkList 算法,从 EntryBlock 开始一步步的模拟,这个过程叫做 intra-procedural analysis(IPA)。这个模拟过程还需要对内存进行模拟,clang static analyzer 的内存模型是基于《A Memory Model for Static Analysis of C Programs》这篇论文而来,pdf地址:http://lcs.ios.ac.cn/~xuzb/canalyze/memmodel.pdf 在clang里的具体实现代码可以查看这两个文件 MemRegion.h和 RegionStore.cpp 。
下面举个简单例子看看 clang static analyzer 是如何对源码进行模拟的。
int main()
{
int a;
int b = 10;
a = b;
return a;
}对应的 AST 以及 CFG
#————————AST—————————
# clang -cc1 -ast-dump
TranslationUnitDecl 0xc75b450 <<invalid sloc>> <invalid sloc>
|-TypedefDecl 0xc75b740 <<invalid sloc>> <invalid sloc> implicit __builtin_va_list ‘char *’
`-FunctionDecl 0xc75b7b0 <test.cpp:1:1, line:7:1> line:1:5 main ‘int (void)’
`-CompoundStmt 0xc75b978 <line:2:1, line:7:1>
|-DeclStmt 0xc75b870 <line:3:2, col:7>
| `-VarDecl 0xc75b840 <col:2, col:6> col:6 used a ‘int’
|-DeclStmt 0xc75b8d8 <line:4:2, col:12>
| `-VarDecl 0xc75b890 <col:2, col:10> col:6 used b ‘int’ cinit
| `-IntegerLiteral 0xc75b8c0 <col:10> ‘int’ 10
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< a = b <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
|-BinaryOperator 0xc75b928 <line:5:2, col:6> ‘int’ lvalue ‘=‘
| |-DeclRefExpr 0xc75b8e8 <col:2> ‘int’ lvalue Var 0xc75b840 ‘a’ ‘int’
| `-ImplicitCastExpr 0xc75b918 <col:6> ‘int’ <LValueToRValue>
| `-DeclRefExpr 0xc75b900 <col:6> ‘int’ lvalue Var 0xc75b890 ‘b’ ‘int’
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
`-ReturnStmt 0xc75b968 <line:6:2, col:9>
`-ImplicitCastExpr 0xc75b958 <col:9> ‘int’ <LValueToRValue>
`-DeclRefExpr 0xc75b940 <col:9> ‘int’ lvalue Var 0xc75b840 ‘a’ ‘int’
#————————CFG—————————
# clang -cc1 -analyze -analyzer-checker=debug.DumpCFG
int main()
[B2 (ENTRY)]
Succs (1): B1
[B1]
1: int a;
2: 10
3: int b = 10;
4: b
5: [B1.4] (ImplicitCastExpr, LValueToRValue, int)
6: a
7: [B1.6] = [B1.5]
8: a
9: [B1.8] (ImplicitCastExpr, LValueToRValue, int)
10: return [B1.9];
Preds (1): B2
Succs (1): B0
[B0 (EXIT)]
Preds (1): B1CFG 将程序拆得更细,能够将执行的过程表现的更直观些,为了避免路径爆炸,函数 inline 的条件会设置的比较严格,函数 CFG 块多时不会进行 inline 分析,模拟栈深度超过一定值不会进行 inline 分析,这个默认是5。
在MRC使用的是CFG这样的执行路径模拟,ARC就没有了,举个例子,没有全部条件都返回,CFG就会报错,而AST就不会。
官方 AST 相关文档
- http://clang.llvm.org/docs/Tooling.html
- http://clang.llvm.org/docs/IntroductionToTheClangAST.html
- http://clang.llvm.org/docs/RAVFrontendAction.html
- http://clang.llvm.org/docs/LibTooling.html
- http://clang.llvm.org/docs/LibASTMatchers.html
静态检查的一些库以及使用方法
- FauxPas_document_translation/README.md at master · DeveloperLx/FauxPas_document_translation · GitHub
CodeGen 生成 IR 代码
将语法树翻译成 LLVM IR 中间代码,做为 LLVM Backend 输入的桥接语言。这样做的好处在前言里也提到了,方便 LLVM Backend 给多语言做相同的优化,做到语言无关。
这个过程中还会跟 runtime 桥接。
- 各种类,方法,成员变量等的结构体的生成,并将其放到对应的Mach-O的section中。
- Non-Fragile ABI 合成 OBJC_IVAR_$_ 偏移值常量。
- ObjCMessageExpr 翻译成相应版本的 objc_msgSend,super 翻译成 objc_msgSendSuper。
- strong,weak,copy,atomic 合成 @property 自动实现 setter 和 getter。
- @synthesize 的处理。
- 生成 block_layout 数据结构
- __block 和 __weak
- _block_invoke
- ARC 处理,插入 objc_storeStrong 和 objc_storeWeak 等 ARC 代码。ObjCAutoreleasePoolStmt 转 objc_autorealeasePoolPush / Pop。自动添加 [super dealloc]。给每个 ivar 的类合成 .cxx_destructor 方法自动释放类的成员变量。
不管编译的语言时 Objective-C 还是 Swift 也不管对应机器是什么,亦或是即时编译,LLVM 里唯一不变的是中间语言 LLVM IR。那么我们就来看看如何玩 LLVM IR。
IR 结构
下面是刚才生成的 main.ll 中间代码文件。
; ModuleID = ‘main.c’
source_filename = “main.c”
target datalayout = “e-m:o-i64:64-f80:128-n8:16:32:64-S128”
target triple = “x86_64-apple-macosx10.12.0”
@.str = private unnamed_addr constant [16 x i8] c”Please input a:\00”, align 1
@.str.1 = private unnamed_addr constant [3 x i8] c”%d\00”, align 1
@.str.2 = private unnamed_addr constant [16 x i8] c”Please input b:\00”, align 1
@.str.3 = private unnamed_addr constant [32 x i8] c”a is:%d,b is :%d,count equal:%d\00”, align 1
; Function Attrs: nounwind ssp uwtable
define i32 @main() #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = bitcast i32* %1 to i8*
call void @llvm.lifetime.start(i64 4, i8* %3) #3
%4 = bitcast i32* %2 to i8*
call void @llvm.lifetime.start(i64 4, i8* %4) #3
%5 = tail call i32 (i8*, …) @printf(i8* getelementptr inbounds ([16 x i8], [16 x i8]* @.str, i64 0, i64 0))
%6 = call i32 (i8*, …) @scanf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32* nonnull %1)
%7 = call i32 (i8*, …) @printf(i8* getelementptr inbounds ([16 x i8], [16 x i8]* @.str.2, i64 0, i64 0))
%8 = call i32 (i8*, …) @scanf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32* nonnull %2)
%9 = load i32, i32* %1, align 4, !tbaa !2
%10 = load i32, i32* %2, align 4, !tbaa !2
%11 = add nsw i32 %10, %9
%12 = call i32 (i8*, …) @printf(i8* getelementptr inbounds ([32 x i8], [32 x i8]* @.str.3, i64 0, i64 0), i32 %9, i32 %10, i32 %11)
call void @llvm.lifetime.end(i64 4, i8* %4) #3
call void @llvm.lifetime.end(i64 4, i8* %3) #3
ret i32 0
}
; Function Attrs: argmemonly nounwind
declare void @llvm.lifetime.start(i64, i8* nocapture) #1
; Function Attrs: nounwind
declare i32 @printf(i8* nocapture readonly, …) #2
; Function Attrs: nounwind
declare i32 @scanf(i8* nocapture readonly, …) #2
; Function Attrs: argmemonly nounwind
declare void @llvm.lifetime.end(i64, i8* nocapture) #1
attributes #0 = { nounwind ssp uwtable “disable-tail-calls”=“false” “less-precise-fpmad”=“false” “no-frame-pointer-elim”=“true” “no-frame-pointer-elim-non-leaf” “no-infs-fp-math”=“false” “no-nans-fp-math”=“false” “stack-protector-buffer-size”=“8” “target-cpu”=“penryn” “target-features”=“+cx16,+fxsr,+mmx,+sse,+sse2,+sse3,+sse4.1,+ssse3” “unsafe-fp-math”=“false” “use-soft-float”=“false” }
attributes #1 = { argmemonly nounwind }
attributes #2 = { nounwind “disable-tail-calls”=“false” “less-precise-fpmad”=“false” “no-frame-pointer-elim”=“true” “no-frame-pointer-elim-non-leaf” “no-infs-fp-math”=“false” “no-nans-fp-math”=“false” “stack-protector-buffer-size”=“8” “target-cpu”=“penryn” “target-features”=“+cx16,+fxsr,+mmx,+sse,+sse2,+sse3,+sse4.1,+ssse3” “unsafe-fp-math”=“false” “use-soft-float”=“false” }
attributes #3 = { nounwind }
!llvm.module.flags = !{!0}
!llvm.ident = !{!1}
!0 = !{i32 1, !”PIC Level”, i32 2}
!1 = !{!”Apple LLVM version 8.0.0 (clang-800.0.42.1)”}
!2 = !{!3, !3, i64 0}
!3 = !{!”int”, !4, i64 0}
!4 = !{!”omnipotent char”, !5, i64 0}
!5 = !{!”Simple C/C++ TBAA”}LLVM IR 有三种表示格式,第一种是 bitcode 这样的存储格式,以 .bc 做后缀,第二种是可读的以 .ll,第三种是用于开发时操作 LLVM IR 的内存格式。
一个编译的单元即一个文件在 IR 里就是一个 Module,Module 里有 Global Variable 和 Function,在 Function里有 Basic Block,Basic Block 里有 指令 Instructions。
‘
通过下面的 IR 结构图能够更好的理解 IR 的整体结构。
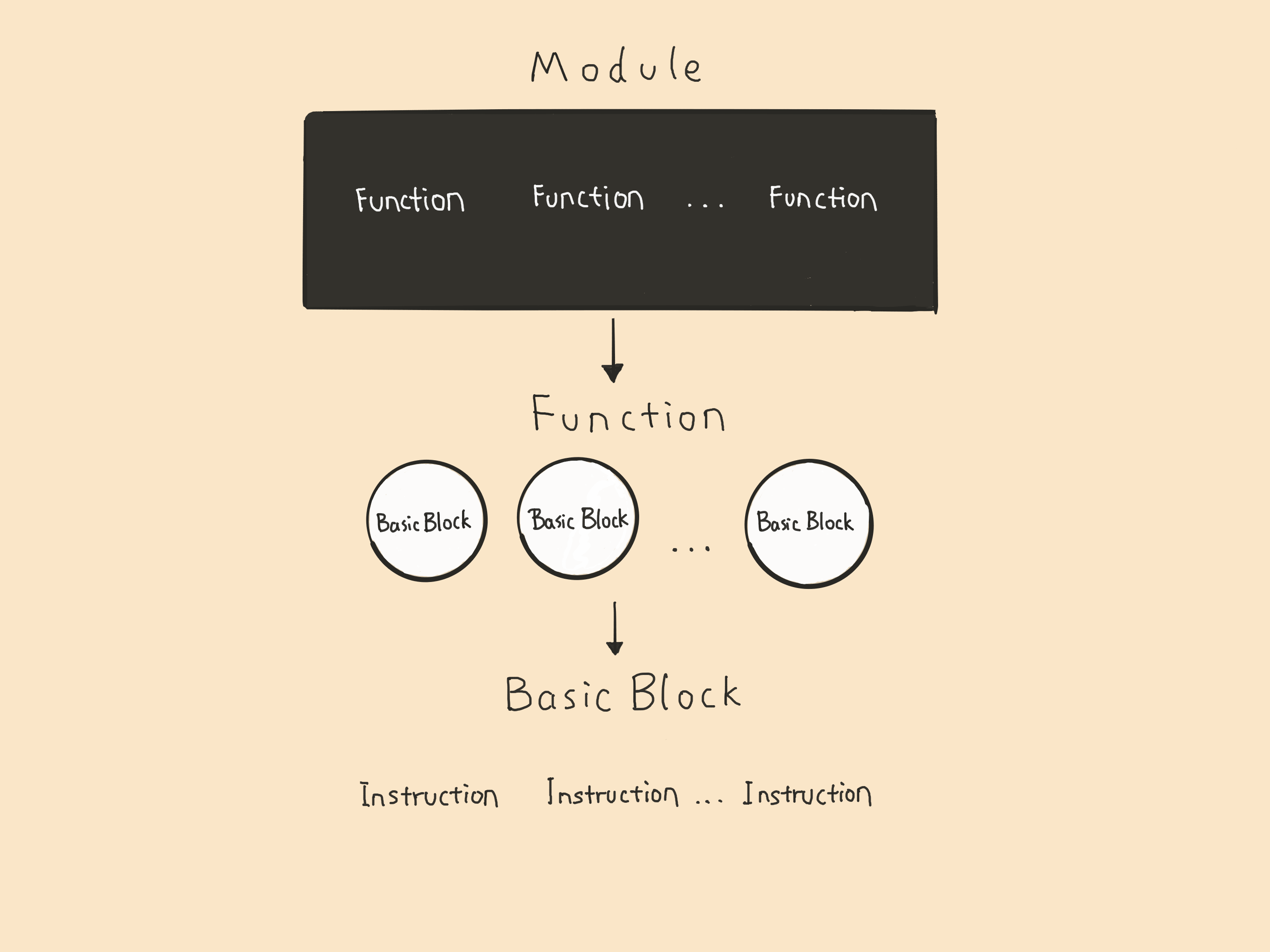
图中可以看出最大的是 Module,里面包含多个 Function,每个 Function 包含多个 BasicBlock,BasicBlock 里含有 Instruction,代码非常清晰,这样如果想开发一个新语言只需要完成语法解析后通过 LLVM 提供的丰富接口在内存中生成 IR 就可以直接运行在各个不同的平台。
IR 语言满足静态单赋值,可以很好的降低数据流分析和控制流分析的复杂度。及只能在定义时赋值,后面不能更改。但是这样就没法写程序了,输入输出都没法弄,所以函数式编程才会有类似 Monad 这样机制的原因。
LLVM IR 优化
使用 O2,O3 这样的优化会调用对应的 Pass 来进行处理,有比如类似死代码清理,内联化,表达式重组,循环变量移动这样的 Pass。可以通过 llvm-opt 调用 LLVM 优化相关的库。
可能直接这么说不太直观,我们可以更改下原 c 代码举个小例子看看这些 Pass 会做哪些优化。当我们加上
int i = 0;
while (i < 10) {
i++;
printf("%d",i);
}对应的 IR 代码是
%call4 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 1)
%call4.1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 2)
%call4.2 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 3)
%call4.3 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 4)
%call4.4 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 5)
%call4.5 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 6)
%call4.6 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 7)
%call4.7 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 8)
%call4.8 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 9)
%call4.9 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 10)可以看出来这个 while 在 IR 中就是重复的打印了10次,那要是我把10改成100是不是会变成打印100次呢?
我们改成100后,再次生成 IR 可以看到 IR 变成了这样:
br label %while.body
while.body: ; preds = %while.body, %entry
%i.010 = phi i32 [ 0, %entry ], [ %inc, %while.body ]
%inc = add nuw nsw i32 %i.010, 1
%call4 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i32 %inc)
%exitcond = icmp eq i32 %inc, 100
br i1 %exitcond, label %while.end, label %while.body
while.end: ; preds = %while.body
%2 = load i32, i32* %a, align 4, !tbaa !2
%3 = load i32, i32* %b, align 4, !tbaa !2
%add = add nsw i32 %3, %2
%call5 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([11 x i8], [11 x i8]* @.str.3, i64 0, i64 0), i32 %add)
call void @llvm.lifetime.end(i64 4, i8* nonnull %1) #3
call void @llvm.lifetime.end(i64 4, i8* nonnull %0) #3
ret i32 0
}这里对不同条件生成的不同都是 Pass 优化器做的事情。解读上面这段 IR 需要先了解下 IR 语法关键字,如下:
- @ - 代表全局变量
- % - 代表局部变量
- alloca - 指令在当前执行的函数的堆栈帧中分配内存,当该函数返回到其调用者时,将自动释放内存。
- i32:- i 是几这个整数就会占几位,i32就是32位4字节
- align - 对齐,比如一个 int,一个 char 和一个 int。单个 int 占4个字节,为了对齐只占一个字节的 char需要向4对齐占用4字节空间。
- Load - 读出,store 写入
- icmp - 两个整数值比较,返回布尔值
- br - 选择分支,根据 cond 来转向 label,不根据条件跳转的话类似 goto
- indirectbr - 根据条件间接跳转到一个 label,而这个 label 一般是在一个数组里,所以跳转目标是可变的,由运行时决定的
- label - 代码标签
br label %while.body如上面表述,br 会选择跳向 while.body 定义的这个标签。这个标签里可以看到
%exitcond = icmp eq i32 %inc, 100
br i1 %exitcond, label %while.end, label %while.body这段,icmp 会比较当前的 %inc 和定义的临界值 100,根据返回的布尔值来决定 br 跳转到那个代码标签,真就跳转到 while.end 标签,否就在进入 while.body 标签。这就是 while 的逻辑。通过br 跳转和 label 这种标签的概念使得 IR 语言能够成为更低级兼容性更高更方便转向更低级语言的语言。
SSA
LLVM IR 是 SSA 形式的,维护双向 def-use 信息,use-def 是通过普通指针实现信息维护,def-use 是通过内存跳表和链表来实现的,便于 forward dataflow analysis 和 backward dataflow analysis。可以通过 ADCE 这个 Pass 来了解下 backward dataflow,这个pass 的源文件在 lib/Transforms/Scalar/ADCE.cpp 中,ADCE 实现了 Aggressive Dead Code Elimination Pass。这个 Pass 乐观地假设所有 instructions 都是 Dead 直到证明是否定的,允许它消除其他 DCE Pass 的 Dead 计算 catch,特别是涉及循环计算。其它 DCE 相关的 Pass 可以查看同级目录下的 BDCE.cpp 和 DCE.cpp,目录下其它的 Pass 都是和数据流相关的分析包含了各种分析算法和思路。
那么看看加法这个操作的相关的 IR 代码
%2 = load i32, i32* %a, align 4, !tbaa !2
%3 = load i32, i32* %b, align 4, !tbaa !2
%add = add nsw i32 %3, %2加法对应的指令是
BinaryOperator::CreateAdd(Value *V1, Value *V2, const Twine &Name)两个输入 V1 和 V2 的 def-use 是如何的呢,看看如下代码
class Value {
void addUse(Use &U) { U.addToList(&UseList); }
// ...
};
class Use {
Value *Val;
Use *Next;
PointerIntPair<Use **, 2, PrevPtrTag> Prev;
// ...
};
void Use::set(Value *V) {
if (Val) removeFromList();
Val = V;
if (V) V->addUse(*this);
}
Value *Use::operator=(Value *RHS) {
set(RHS);
return RHS;
}
class User : public Value {
template <int Idx, typename U> static Use &OpFrom(const U *that) {
return Idx < 0
? OperandTraits<U>::op_end(const_cast<U*>(that))[Idx]
: OperandTraits<U>::op_begin(const_cast<U*>(that))[Idx];
}
template <int Idx> Use &Op() {
return OpFrom<Idx>(this);
}
template <int Idx> const Use &Op() const {
return OpFrom<Idx>(this);
}
// ...
};
class Instruction : public User,
public ilist_node_with_parent<Instruction, BasicBlock> {
// ...
};
class BinaryOperator : public Instruction {
/// Construct a binary instruction, given the opcode and the two
/// operands. Optionally (if InstBefore is specified) insert the instruction
/// into a BasicBlock right before the specified instruction. The specified
/// Instruction is allowed to be a dereferenced end iterator.
///
static BinaryOperator *Create(BinaryOps Op, Value *S1, Value *S2,
const Twine &Name = Twine(),
Instruction *InsertBefore = nullptr);
// ...
};
BinaryOperator::BinaryOperator(BinaryOps iType, Value *S1, Value *S2,
Type *Ty, const Twine &Name,
Instruction *InsertBefore)
: Instruction(Ty, iType,
OperandTraits<BinaryOperator>::op_begin(this),
OperandTraits<BinaryOperator>::operands(this),
InsertBefore) {
Op<0>() = S1;
Op<1>() = S2;
init(iType);
setName(Name);
}
BinaryOperator *BinaryOperator::Create(BinaryOps Op, Value *S1, Value *S2,
const Twine &Name,
Instruction *InsertBefore) {
assert(S1->getType() == S2->getType() &&
"Cannot create binary operator with two operands of differing type!");
return new BinaryOperator(Op, S1, S2, S1->getType(), Name, InsertBefore);
}从代码里可以看出是使用了 Use 对象来把 use 和 def 联系起来的。
LLVM IR 通过 mem2reg 这个 Pass 来把局部变量成 SSA 形式。这个 Pass 的代码在 lib/Transforms/Utils/Mem2Reg.cpp 里。LLVM通过 mem2reg Pass 能够识别 alloca 模式,将其设置 SSA value。这时就不在需要 alloca,load和store了。mem2reg 是对 PromoteMemToReg 函数调用的一个简单包装,真正的算法实现是在 PromoteMemToReg 函数里,这个函数在 lib/Transforms/Utils/PromoteMemoryToRegister.cpp 这个文件里。
这个算法会使 alloca 这个仅仅作为 load 和 stores 的用途的指令使用迭代 dominator 边界转换成 PHI 节点,然后通过使用深度优先函数排序重写 loads 和 stores。这种算法叫做 iterated dominance frontier算法,具体实现方法可以参看 PromoteMemToReg 函数的实现。
当然把多个字节码 .bc 合成一个文件,链接时还会优化,IR 结构在优化后会有变化,这样还能够在变化后的 IR 的结构上再进行更多的优化。
这里可以进行 lli 解释执行 LLVM IR。
llc 编译器是专门编译 LLVM IR 的编译器用来生成汇编文件。
调用系统汇编器比如 GNU 的 as 来编译生成 .o Object 文件,接下来就是用链接器链接相关库和 .o 文件一起生成可执行的 .out 或者 exe 文件了。
llvm-mc 还可以直接生成 object 文件。
Clang CFE
动手玩肯定不能少了 Clang 的前端组件及库,熟悉这些库以后就能够自己动手用这些库编写自己的程序了。下面我就对这些库做些介绍,然后再着重说说 libclang 库,以及如何用它来写工具。
- LLVM Support Library - LLVM libSupport 库提供了许多底层库和数据结构,包括命令行 option 处理,各种容器和系统抽象层,用于文件系统访问。
- The Clang “Basic” Library - 提供了跟踪和操纵 source buffers,source buffers 的位置,diagnostics,tokens,抽象目标以及编译语言子集信息的 low-level 实用程序。还有部分可以用在其他的非 c 语言比如 SourceLocation,SourceManager,Diagnositics,FileManager 等。其中 Diagnositics 这个子系统是编译器和普通写代码人交流的主要组成部分,它会诊断当前代码哪些不正确,按照严重程度而产生 WARNING 或 ERROR,每个诊断会有唯一 ID , SourceLocation 会负责管理。
- The Driver Library - 和 Driver 相关的库,上面已经对其做了详细的介绍。
- Precompiled Headers - Clang 支持预编译 headers 的两个实现。
- The Frontend Library - 这个库里包含了在 Clang 库之上构建的功能,比如输出 diagnositics 的几种方法。
- The Lexer and Preprocessor Library - 词法分析和预处理的库,包含了 Token,Annotation Tokens,TokenLexer,Lexer 等词法类,还有 Parser Library 和 AST 语法树相关的比如 Type,ASTContext,QualType,DeclarationName,DeclContext 以及 CFG 类。
- The Sema Library - 解析器调用此库时,会对输入进行语义分析。 对于有效的程序,Sema 为解析构造一个 AST。
- The CodeGen Library - CodeGen 用 AST 作为输入,并从中生成 LLVM IR 代码。
libclang
libclang 会让你觉得 clang 不仅仅只是一个伟大的编译器。下面从解析源码来说下
先写个 libclang 的程序来解析源码
int main(int argc, char *argv[]) {
CXIndex Index = clang_createIndex(0, 0);
CXTranslationUnit TU = clang_parseTranslationUnit(Index, 0,
argv, argc, 0, 0, CXTranslationUnit_None); for (unsigned I = 0, N = clang_getNumDiagnostics(TU); I != N; ++I) {
CXDiagnostic Diag = clang_getDiagnostic(TU, I);
CXString String = clang_formatDiagnostic(Diag,clang_defaultDiagnosticDisplayOptions());
fprintf(stderr, "%s\n", clang_getCString(String));
clang_disposeString(String);
}
clang_disposeTranslationUnit(TU);
clang_disposeIndex(Index);
return 0;
}再写个有问题的 c 程序
struct List { /**/ };
int sum(union List *L) { /* ... */ }运行了语法检查后会出现提示信息
list.c:2:9: error: use of 'List' with tag type that does not match
previous declaration
int sum(union List *Node) {
^~~~~
struct
list.c:1:8: note: previous use is here
struct List {
^下面我们看看诊断过程,显示几个核心诊断方法诊断出问题
- enum CXDiagnosticSeverity clang_getDiagnosticSeverity(CXDiagnostic Diag);
- CXSourceLocation clang_getDiagnosticLocation(CXDiagnostic Diag);
- CXString clang_getDiagnosticSpelling(CXDiagnostic Diag);
接着进行高亮显示,最后提供两个提示修复的方法
- unsigned clang_getDiagnosticNumFixIts(CXDiagnostic Diag);
- CXString clang_getDiagnosticFixIt(CXDiagnostic Diag, unsigned FixIt,
CXSourceRange *ReplacementRange);
我们先遍历语法树的节点。源 c 程序如下
struct List {
int Data;
struct List *Next;
};
int sum(struct List *Node) {
int result = 0;
for (; Node; Node = Node->Next)
result = result + Node->Data;
return result;
}先找出所有的声明,比如 List,Data,Next,sum,Node 以及 result 等。再找出引用,比如 struct List *Next 里的 List。还有声明和表达式,比如 int result = 0; 还有 for 语句等。还有宏定义和实例化等。
CXCursor 会统一 AST 的节点,规范包含的信息
- 代码所在位置和长度
- 名字和符号解析
- 类型
- 子节点
举个 CXCursor 分析例子
struct List {
int Data;
struct List *Next;
};CXCursor 的处理过程如下
//Top-level cursor C
clang_getCursorKind(C) == CXCursor_StructDecl
clang_getCursorSpelling(C) == "List" //获取名字字符串
clang_getCursorLocation(C) //位置
clang_getCursorExtent(C) //长度
clang_visitChildren(C, ...); //访问子节点
//Reference cursor R
clang_getCursorKind(R) == CXCursor_TypeRef
clang_getCursorSpelling(R) == "List"
clang_getCursorLocation(R)
clang_getCursorExtent(R)
clang_getCursorReferenced(R) == C //指向CDriver
动手玩的话,特别是想要使用这些工具链之前最好先了解我们和 LLVM 交互的实现。那么这部分就介绍下 LLVM 里的 Driver。
Driver 是 Clang 面对用户的接口,用来解析 Option 设置,判断决定调用的工具链,最终完成整个编译过程。
相关源代码在这里:clang/tools/driver/driver.cpp
整个 Driver 源码的入口函数就是 driver.cpp 里的 main() 函数。从这里可以作为入口看看整个 driver 是如何工作的,这样更利于我们以后轻松动手驾驭 LLVM。
int main(int argc_, const char **argv_) {
llvm::sys::PrintStackTraceOnErrorSignal(argv_[0]);
llvm::PrettyStackTraceProgram X(argc_, argv_);
llvm::llvm_shutdown_obj Y; // Call llvm_shutdown() on exit.
if (llvm::sys::Process::FixupStandardFileDescriptors())
return 1;
SmallVector<const char *, 256> argv;
llvm::SpecificBumpPtrAllocator<char> ArgAllocator;
std::error_code EC = llvm::sys::Process::GetArgumentVector(
argv, llvm::makeArrayRef(argv_, argc_), ArgAllocator);
if (EC) {
llvm::errs() << "error: couldn't get arguments: " << EC.message() << '\n';
return 1;
}
llvm::InitializeAllTargets();
std::string ProgName = argv[0];
std::pair<std::string, std::string> TargetAndMode =
ToolChain::getTargetAndModeFromProgramName(ProgName);
llvm::BumpPtrAllocator A;
llvm::StringSaver Saver(A);
//省略
...
// If we have multiple failing commands, we return the result of the first
// failing command.
return Res;
}Driver 的工作流程图
在 driver.cpp 的 main 函数里有 Driver 的初始化。我们来看看和 driver 相关的代码
Driver TheDriver(Path, llvm::sys::getDefaultTargetTriple(), Diags);
SetInstallDir(argv, TheDriver, CanonicalPrefixes);
insertTargetAndModeArgs(TargetAndMode.first, TargetAndMode.second, argv,
SavedStrings);
SetBackdoorDriverOutputsFromEnvVars(TheDriver);
std::unique_ptr<Compilation> C(TheDriver.BuildCompilation(argv));
int Res = 0;
SmallVector<std::pair<int, const Command *>, 4> FailingCommands;
if (C.get())
Res = TheDriver.ExecuteCompilation(*C, FailingCommands);
// Force a crash to test the diagnostics.
if (::getenv("FORCE_CLANG_DIAGNOSTICS_CRASH")) {
Diags.Report(diag::err_drv_force_crash) << "FORCE_CLANG_DIAGNOSTICS_CRASH";
// Pretend that every command failed.
FailingCommands.clear();
for (const auto &J : C->getJobs())
if (const Command *C = dyn_cast<Command>(&J))
FailingCommands.push_back(std::make_pair(-1, C));
}
for (const auto &P : FailingCommands) {
int CommandRes = P.first;
const Command *FailingCommand = P.second;
if (!Res)
Res = CommandRes;
// If result status is < 0, then the driver command signalled an error.
// If result status is 70, then the driver command reported a fatal error.
// On Windows, abort will return an exit code of 3. In these cases,
// generate additional diagnostic information if possible.
bool DiagnoseCrash = CommandRes < 0 || CommandRes == 70;
#ifdef LLVM_ON_WIN32
DiagnoseCrash |= CommandRes == 3;
#endif
if (DiagnoseCrash) {
TheDriver.generateCompilationDiagnostics(*C, *FailingCommand);
break;
}
}可以看到初始化 Driver 后 driver 会调用 BuildCompilation 生成 Compilation。Compilation 字面意思是合集的意思,通过 driver.cpp 的 include 可以看到
#include "clang/Driver/Compilation.h"根据此路径可以细看下 Compilation 这个为了 driver 设置的一组任务的类。通过这个类我们提取里面这个阶段比较关键的几个信息出来
class Compilation {
/// The original (untranslated) input argument list.
llvm::opt::InputArgList *Args;
/// The driver translated arguments. Note that toolchains may perform their
/// own argument translation.
llvm::opt::DerivedArgList *TranslatedArgs;
/// The driver we were created by.
const Driver &TheDriver;
/// The default tool chain.
const ToolChain &DefaultToolChain;
...
/// The list of actions. This is maintained and modified by consumers, via
/// getActions().
ActionList Actions;
/// The root list of jobs.
JobList Jobs;
...
public:
...
const Driver &getDriver() const { return TheDriver; }
const ToolChain &getDefaultToolChain() const { return DefaultToolChain; }
...
ActionList &getActions() { return Actions; }
const ActionList &getActions() const { return Actions; }
...
JobList &getJobs() { return Jobs; }
const JobList &getJobs() const { return Jobs; }
void addCommand(std::unique_ptr<Command> C) { Jobs.addJob(std::move(C)); }
...
/// ExecuteCommand - Execute an actual command.
///
/// \param FailingCommand - For non-zero results, this will be set to the
/// Command which failed, if any.
/// \return The result code of the subprocess.
int ExecuteCommand(const Command &C, const Command *&FailingCommand) const;
/// ExecuteJob - Execute a single job.
///
/// \param FailingCommands - For non-zero results, this will be a vector of
/// failing commands and their associated result code.
void ExecuteJobs(
const JobList &Jobs,
SmallVectorImpl<std::pair<int, const Command *>> &FailingCommands) const;
...
};通过这些关键定义再结合 BuildCompilation 函数的实现可以看出这个 Driver 的流程是按照 ArgList - Actions - Jobs 来的,完整的图如下:
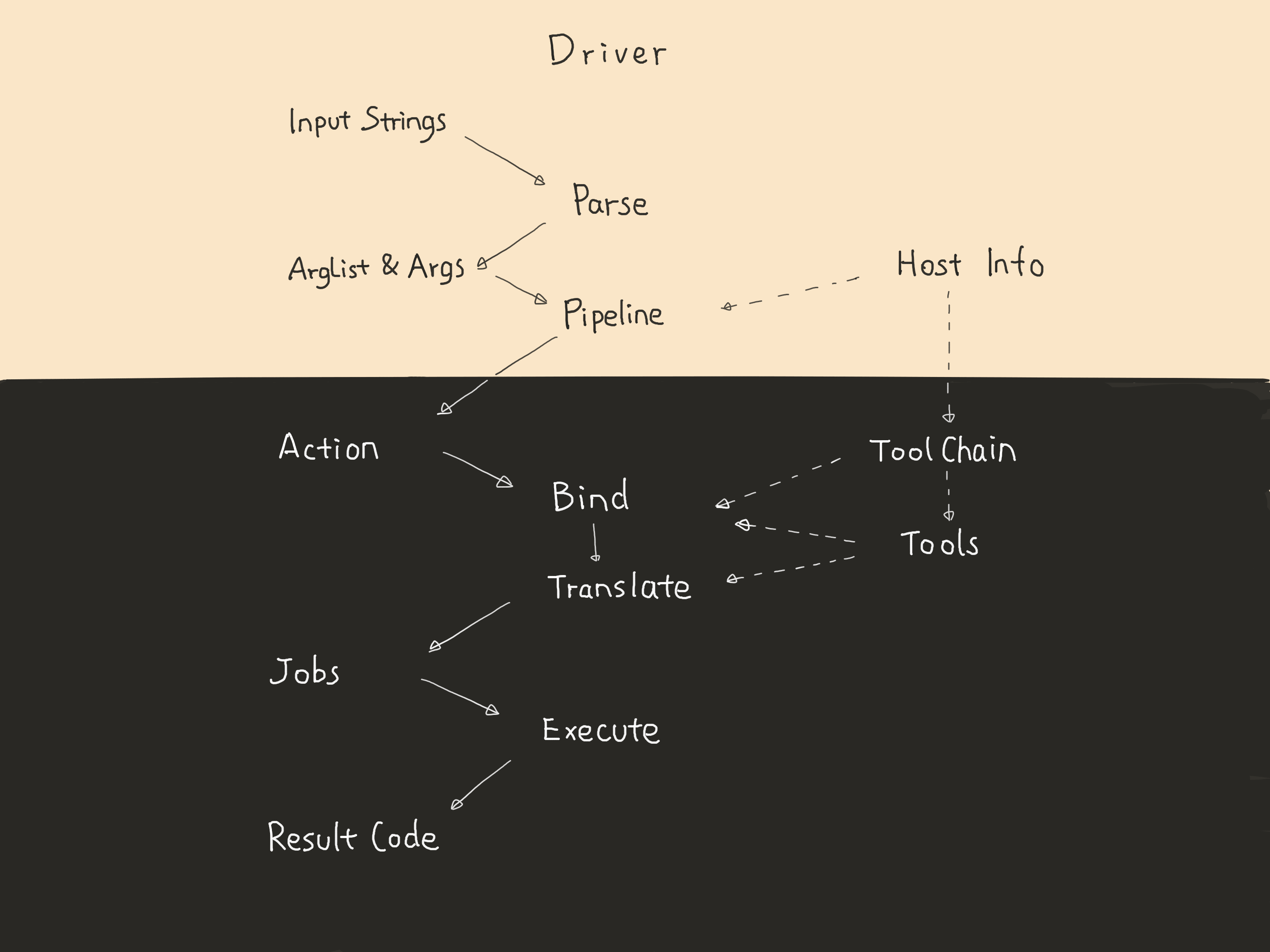
Parse
看完完整的 Driver 流程后,我们就先从 Parse 开始说起。
Parse 是解析选项,对应的代码在 ParseArgStrings 这个函数里。
下面通过执行一个试试,比如 clang -### main.c -ITheOptionWeAdd
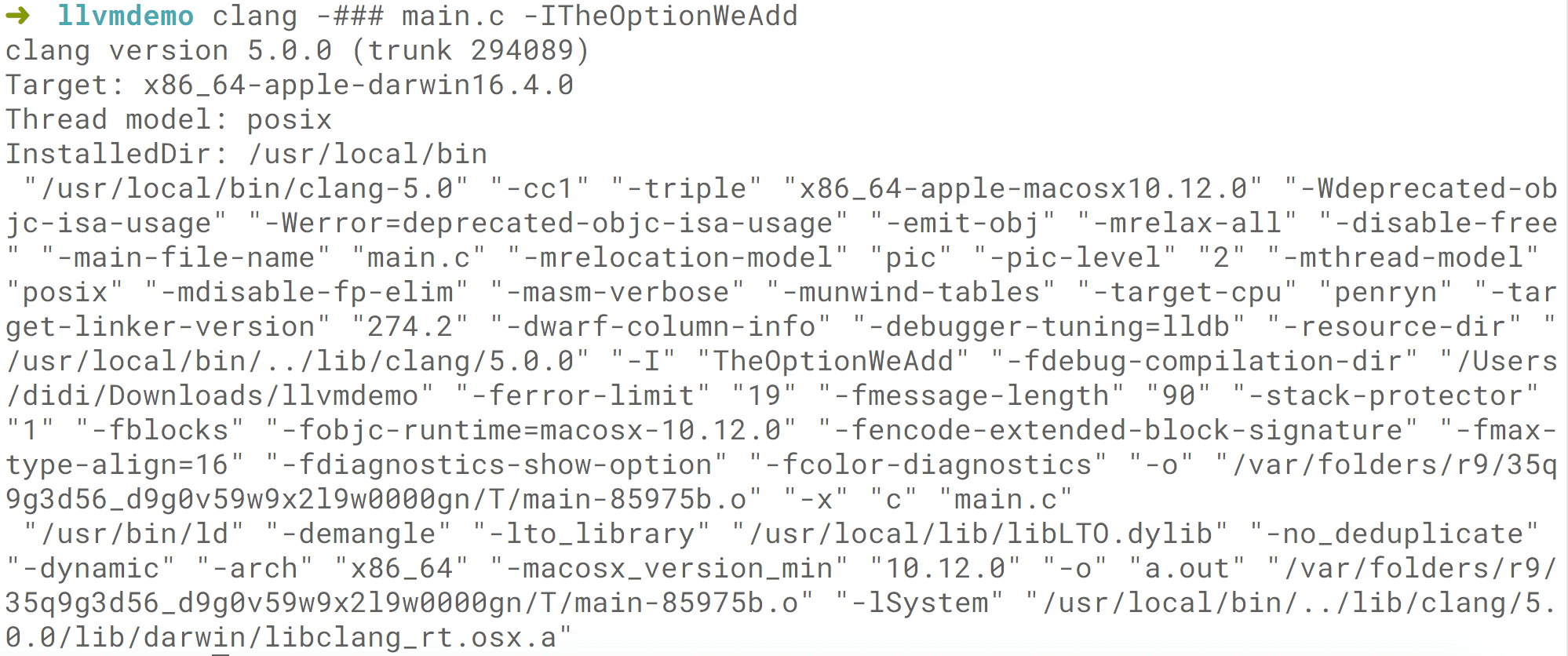
这里的 -I 是 Clang 支持的,在 Clang 里是 Option 类,Clang 会对这些 Option 专门的进行解析,使用一种 DSL 语言将其转成 .tb 文件后使用 table-gen 转成 C++ 语言和其它代码一起进行编译。
Driver 层会解析我们传入的 -I Option 参数。
-x 后加个 c 表示是对 c 语言进行编译,Clang Driver 通过文件的后缀 .c 来自动加上这个 参数的。如果是 c++ 语言,仅仅通过在 -x 后添加 cpp 编译还是会出错的。
clang -x c++ main.cpp
通过报错信息可以看出一些链接错误
因为需要链接 C++ 标准库,所以加上参数 -lc++ 就可以了
clang -x c++ -lc++ main.cpp那么 clang++ 和 clang 命令的区别就在于会加载 C++ 库,其实 clang++ 最终还是会调用 Clang,那么手动指定加载库就好了何必还要多个 clang++ 命令呢,这主要是为了能够在这个命令里去加载更多的库,除了标准库以外,还有些非 C++ 标准库,辅助库等等。这样只要是 C++ 的程序用 clang++ 够了。
只有加上 -cc1 这个 option 才能进入到 Clang driver 比如 emit-obj 这个 option 就需要先加上 -cc1。
这点可以通过 driver.cpp 源码来看,在 main() 函数里可以看到在做了些多平台的兼容处理后就开始进行对入参判断第一个是不是 -cc1。
if (MarkEOLs && argv.size() > 1 && StringRef(argv[1]).startswith("-cc1"))
MarkEOLs = false;
llvm::cl::ExpandResponseFiles(Saver, Tokenizer, argv, MarkEOLs);
// 处理 -cc1 集成工具
auto FirstArg = std::find_if(argv.begin() + 1, argv.end(),
[](const char *A) { return A != nullptr; });
if (FirstArg != argv.end() && StringRef(*FirstArg).startswith("-cc1")) {
// 如果 -cc1 来自 response file, 移除 EOL sentinels
if (MarkEOLs) {
auto newEnd = std::remove(argv.begin(), argv.end(), nullptr);
argv.resize(newEnd - argv.begin());
}
return ExecuteCC1Tool(argv, argv[1] + 4);
}如果是 -cc1 的话会调用 ExecuteCC1Tool 这个函数,先看看这个函数
static int ExecuteCC1Tool(ArrayRef<const char *> argv, StringRef Tool) {
void *GetExecutablePathVP = (void *)(intptr_t) GetExecutablePath;
if (Tool == "")
return cc1_main(argv.slice(2), argv[0], GetExecutablePathVP);
if (Tool == "as")
return cc1as_main(argv.slice(2), argv[0], GetExecutablePathVP);
// 拒绝未知工具
llvm::errs() << "error: unknown integrated tool '" << Tool << "'\n";
return 1;
}最终的执行会执行 cc1-main 或者 cc1as_main 。这两个函数分别在 driver.cpp 同级目录里的 cc1_main.cpp 和 cc1as_main.cpp 中。
下面看看有哪些解析 Args 的方法
- ParseAnalyzerArgs - 解析出静态分析器 option
- ParseMigratorArgs - 解析 Migrator option
- ParseDependencyOutputArgs - 解析依赖输出 option
- ParseCommentArgs - 解析注释 option
- ParseFileSystemArgs - 解析文件系统 option
- ParseFrontendArgs - 解析前端 option
- ParseTargetArgs - 解析目标 option
- ParseCodeGenArgs - 解析 CodeGen 相关的 option
- ParseHeaderSearchArgs - 解析 HeaderSearch 对象相关初始化相关的 option
- parseSanitizerKinds - 解析 Sanitizer Kinds
- ParsePreprocessorArgs - 解析预处理的 option
- ParsePreprocessorOutputArgs - 解析预处理输出的 option
Pipeline
Pipeline 这里可以添加 -ccc-print-phases 看到进入 Pipeline 以后的事情。
这些如 -ccc-print-phases 这样的 option 在编译时会生成.inc 这样的 C++ TableGen 文件。在 Options.td 可以看到全部的 option 定义。
在 Clang 的 Pipeline 中很多实际行为都有对应的 Action,比如 preprocessor 时提供文件的 InputAction 和用于绑定机器架构的 BindArchAction。
使用 clang main.c -arch i386 -arch x86_64 -o main 然后 file main 能够看到这时 BindArchAction 这个 Action 起到了作用,编译链接了两次同时创建了一个库既能够支持32位也能够支持64位用 lipo 打包。
Action
/// BuildActions - Construct the list of actions to perform for the
/// given arguments, which are only done for a single architecture.
///
/// \param C - The compilation that is being built.
/// \param Args - The input arguments.
/// \param Actions - The list to store the resulting actions onto.
void BuildActions(Compilation &C, llvm::opt::DerivedArgList &Args,
const InputList &Inputs, ActionList &Actions) const;
/// BuildUniversalActions - Construct the list of actions to perform
/// for the given arguments, which may require a universal build.
///
/// \param C - The compilation that is being built.
/// \param TC - The default host tool chain.
void BuildUniversalActions(Compilation &C, const ToolChain &TC,
const InputList &BAInputs) const;上面两个方法中 BuildUniversalActions 最后也会走 BuildActions。BuildActions 了,进入这个方法
void Driver::BuildActions(Compilation &C, DerivedArgList &Args,
const InputList &Inputs, ActionList &Actions) const {
llvm::PrettyStackTraceString CrashInfo("Building compilation actions");
if (!SuppressMissingInputWarning && Inputs.empty()) {
Diag(clang::diag::err_drv_no_input_files);
return;
}
Arg *FinalPhaseArg;
phases::ID FinalPhase = getFinalPhase(Args, &FinalPhaseArg);接着跟 getFinalPhase 这个方法。
// -{E,EP,P,M,MM} only run the preprocessor.
if (CCCIsCPP() || (PhaseArg = DAL.getLastArg(options::OPT_E)) ||
(PhaseArg = DAL.getLastArg(options::OPT__SLASH_EP)) ||
(PhaseArg = DAL.getLastArg(options::OPT_M, options::OPT_MM)) ||
(PhaseArg = DAL.getLastArg(options::OPT__SLASH_P))) {
FinalPhase = phases::Preprocess;
// -{fsyntax-only,-analyze,emit-ast} only run up to the compiler.
} else if ((PhaseArg = DAL.getLastArg(options::OPT_fsyntax_only)) ||
(PhaseArg = DAL.getLastArg(options::OPT_module_file_info)) ||
(PhaseArg = DAL.getLastArg(options::OPT_verify_pch)) ||
(PhaseArg = DAL.getLastArg(options::OPT_rewrite_objc)) ||
(PhaseArg = DAL.getLastArg(options::OPT_rewrite_legacy_objc)) ||
(PhaseArg = DAL.getLastArg(options::OPT__migrate)) ||
(PhaseArg = DAL.getLastArg(options::OPT__analyze,
options::OPT__analyze_auto)) ||
(PhaseArg = DAL.getLastArg(options::OPT_emit_ast))) {
FinalPhase = phases::Compile;
// -S only runs up to the backend.
} else if ((PhaseArg = DAL.getLastArg(options::OPT_S))) {
FinalPhase = phases::Backend;
// -c compilation only runs up to the assembler.
} else if ((PhaseArg = DAL.getLastArg(options::OPT_c))) {
FinalPhase = phases::Assemble;
// Otherwise do everything.
} else
FinalPhase = phases::Link;看完这段代码就会发现其实每次的 option 都会完整的走一遍从预处理,静态分析,backend 再到汇编的过程。
下面列下一些编译器的前端 Action,大家可以一个个用着玩。
- InitOnlyAction - 只做前端初始化,编译器 option 是 -init-only
- PreprocessOnlyAction - 只做预处理,不输出,编译器的 option 是 -Eonly
- PrintPreprocessedAction - 做预处理,子选项还包括-P、-C、-dM、-dD 具体可以查看PreprocessorOutputOptions 这个类,编译器 option 是 -E
- RewriteIncludesAction - 预处理
- DumpTokensAction - 打印token,option 是 -dump-tokens
- DumpRawTokensAction - 输出原始tokens,包括空格符,option 是 -dump-raw-tokens
- RewriteMacrosAction - 处理并扩展宏定义,对应的 option 是 -rewrite-macros
- HTMLPrintAction - 生成高亮的代码网页,对应的 option 是 -emit-html
- DeclContextPrintAction - 打印声明,option 对应的是 -print-decl-contexts
- ASTDeclListAction - 打印 AST 节点,option 是 -ast-list
- ASTDumpAction - 打印 AST 详细信息,对应 option 是 -ast-dump
- ASTViewAction - 生成 AST dot 文件,能够通过 Graphviz 来查看图形语法树。 option 是 -ast-view
- AnalysisAction - 运行静态分析引擎,option 是 -analyze
- EmitLLVMAction - 生成可读的 IR 中间语言文件,对应的 option 是 -emit-llvm
- EmitBCAction - 生成 IR Bitcode 文件,option 是 -emit-llvm-bc
- MigrateSourceAction - 代码迁移,option 是 -migrate
Bind
Bind 主要是与工具链 ToolChain 交互
根据创建的那些 Action,在 Action 执行时 Bind 来提供使用哪些工具,比如生成汇编时是使用内嵌的还是 GNU 的,还是其它的呢,这个就是由 Bind 来决定的,具体使用的工具有各个架构,平台,系统的 ToolChain 来决定。
通过 clang -ccc-print-bindings main.c -o main 来看看 Bind 的结果
可以看到编译选择的是 clang,链接选择的是 darwin::Linker,但是在链接时前没有汇编器的过程,这个就是 Bind 起了作用,它会根据不同的平台来决定选择什么工具,因为是在 Mac 系统里 Bind 就会决定使用 integrated-as 这个内置汇编器。那么如何在不用内置汇编器呢。可以使用 -fno-integrated-as 这个 option。
Translate
Translate 就是把相关的参数对应到不同平台上不同的工具。
Jobs
从创建 Jobs 的方法
/// BuildJobsForAction - Construct the jobs to perform for the action \p A and
/// return an InputInfo for the result of running \p A. Will only construct
/// jobs for a given (Action, ToolChain, BoundArch, DeviceKind) tuple once.
InputInfo
BuildJobsForAction(Compilation &C, const Action *A, const ToolChain *TC,
StringRef BoundArch, bool AtTopLevel, bool MultipleArchs,
const char *LinkingOutput,
std::map<std::pair<const Action *, std::string>, InputInfo>
&CachedResults,
Action::OffloadKind TargetDeviceOffloadKind) const;可以看出 Jobs 需要前面的 Compilation,Action,ToolChain 等,那么 Jobs 就是将前面获取的信息进行组合分组给后面的 Execute 做万全准备。
Execute
在 driver.cpp 的 main 函数里的 ExecuteCompilation 方法里可以看到如下代码:
// Set up response file names for each command, if necessary
for (auto &Job : C.getJobs())
setUpResponseFiles(C, Job);
C.ExecuteJobs(C.getJobs(), FailingCommands);能够看到 Jobs 准备好了后就要开始 Excute 他们。
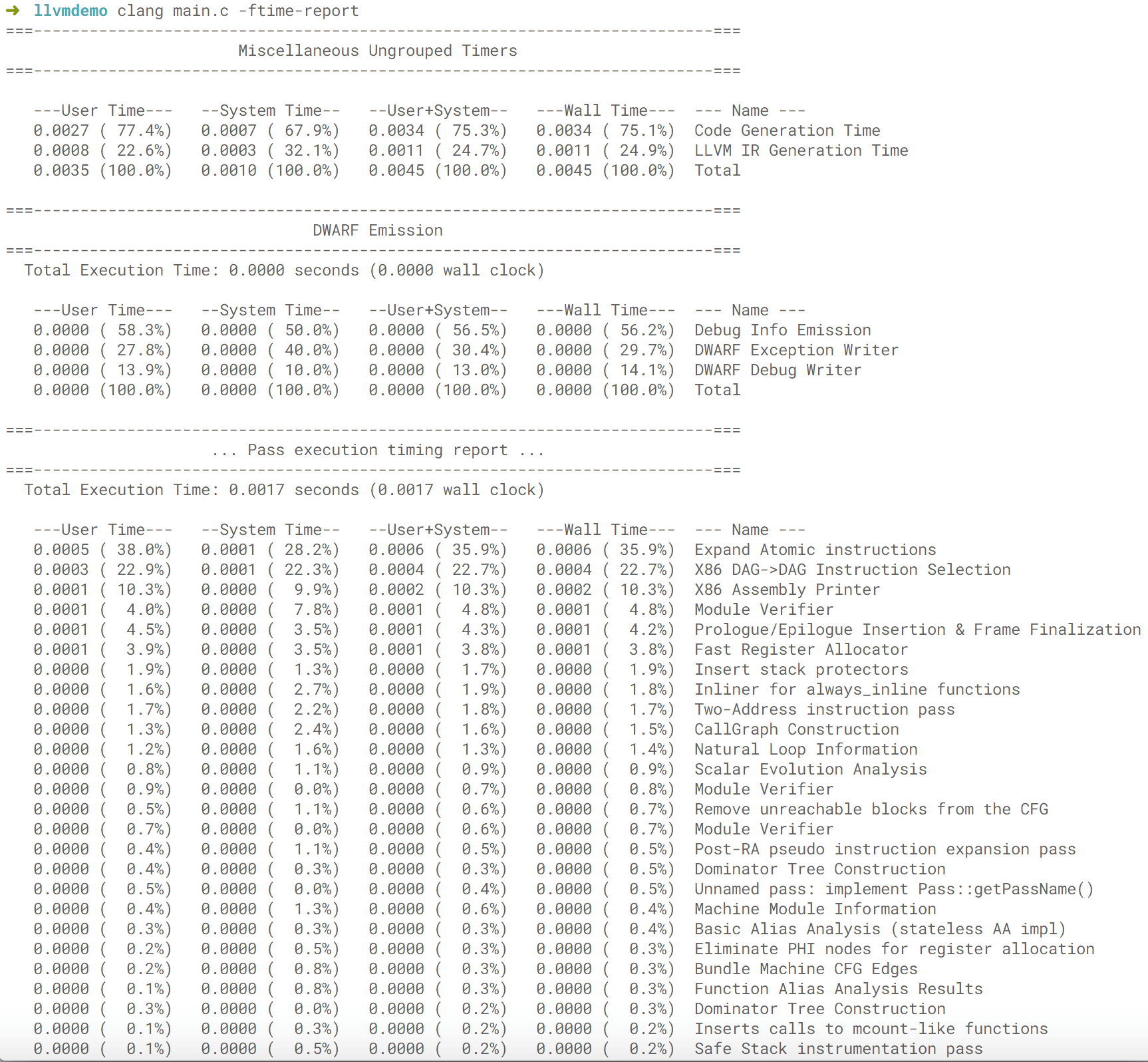
Execute 就是执行整个的编译过程的 Jobs。过程执行的内容和耗时可以通过添加 -ftime-report 这个 option 来看到。
Clang Attributes
以 attribute(xx) 的语法格式出现,是 Clang 提供的一些能够让开发者在编译过程中参与一些源码控制的方法。下面列一些会用到的用法:
attribute((format(NSString, F, A))) 格式化字符串
可以查看 NSLog 的用法
FOUNDATION_EXPORT void NSLog(NSString *format, …) NS_FORMAT_FUNCTION(1,2) NS_NO_TAIL_CALL;
// Marks APIs which format strings by taking a format string and optional varargs as arguments
#if !defined(NS_FORMAT_FUNCTION)
#if (__GNUC__*10+__GNUC_MINOR__ >= 42) && (TARGET_OS_MAC || TARGET_OS_EMBEDDED)
#define NS_FORMAT_FUNCTION(F,A) __attribute__((format(__NSString__, F, A)))
#else
#define NS_FORMAT_FUNCTION(F,A)
#endif
#endifattribute((deprecated(s))) 版本弃用提示
在编译过程中能够提示开发者该方法或者属性已经被弃用
- (void)preMethod:( NSString *)string __attribute__((deprecated(“preMethod已经被弃用,请使用newMethod”)));
- (void)deprecatedMethod DEPRECATED_ATTRIBUTE; //也可以直接使用DEPRECATED_ATTRIBUTE这个系统定义的宏attribute((availability(os,introduced=m,deprecated=n, obsoleted=o,message=“” VA_ARGS))) 指明使用版本范围
os 指系统的版本,m 指明引入的版本,n 指明过时的版本,o 指完全不用的版本,message 可以写入些描述信息。
- (void)method __attribute__((availability(ios,introduced=3_0,deprecated=6_0,obsoleted=7_0,message=“iOS3到iOS7版本可用,iOS7不能用”)));attribute((unavailable(…))) 方法不可用提示
这个会在编译过程中告知方法不可用,如果使用了还会让编译失败。
attribute((unused))
没有被使用也不报警告
attribute((warn_unused_result))
不使用方法的返回值就会警告,目前 swift3 已经支持该特性了。oc中也可以通过定义这个attribute来支持。
attribute((availability(swift, unavailable, message=_msg)))
OC 的方法不能在 Swift 中使用。
attribute((cleanup(…))) 作用域结束时自动执行一个指定方法
作用域结束包括大括号结束,return,goto,break,exception 等情况。这个动作是先于这个对象的 dealloc 调用的。
Reactive Cocoa 中有个比较好的使用范例,@onExit 这个宏,定义如下:
#define onExit \
rac_keywordify \
__strong rac_cleanupBlock_t metamacro_concat(rac_exitBlock_, __LINE__) __attribute__((cleanup(rac_executeCleanupBlock), unused)) = ^
static inline void rac_executeCleanupBlock (__strong rac_cleanupBlock_t *block) {
(*block)();
}这样可以在就可以很方便的把需要成对出现的代码写在一起了。同样可以在 Reactive Cocoa 看到其使用
if (property != NULL) {
rac_propertyAttributes *attributes = rac_copyPropertyAttributes(property);
if (attributes != NULL) {
@onExit {
free(attributes);
};
BOOL isObject = attributes->objectClass != nil || strstr(attributes->type, @encode(id)) == attributes->type;
BOOL isProtocol = attributes->objectClass == NSClassFromString(@“Protocol”);
BOOL isBlock = strcmp(attributes->type, @encode(void(^)())) == 0;
BOOL isWeak = attributes->weak;
shouldAddDeallocObserver = isObject && isWeak && !isBlock && !isProtocol;
}
}可以看出 attributes 的设置和释放都在一起使得代码的可读性得到了提高。
attribute((overloadable)) 方法重载
能够在 c 的函数上实现方法重载。即同样的函数名函数能够对不同参数在编译时能够自动根据参数来选择定义的函数
__attribute__((overloadable)) void printArgument(int number){
NSLog(@“Add Int %i”, number);
}
__attribute__((overloadable)) void printArgument(NSString *number){
NSLog(@“Add NSString %@“, number);
}
__attribute__((overloadable)) void printArgument(NSNumber *number){
NSLog(@“Add NSNumber %@“, number);
}attribute((objc_designated_initializer)) 指定内部实现的初始化方法
- 如果是 objc_designated_initializer 初始化的方法必须调用覆盖实现 super 的 objc_designated_initializer 方法。
- 如果不是 objc_designated_initializer 的初始化方法,但是该类有 objc_designated_initializer 的初始化方法,那么必须调用该类的 objc_designated_initializer 方法或者非 objc_designated_initializer 方法,而不能够调用 super 的任何初始化方法。
attribute((objc_subclassing_restricted)) 指定不能有子类
相当于 Java 里的 final 关键字,如果有子类继承就会出错。
attribute((objc_requires_super)) 子类继承必须调用 super
声明后子类在继承这个方法时必须要调用 super,否则会出现编译警告,这个可以定义一些必要执行的方法在 super 里提醒使用者这个方法的内容时必要的。
attribute((const)) 重复调用相同数值参数优化返回
用于数值类型参数的函数,多次调用相同的数值型参数,返回是相同的,只在第一次是需要进行运算,后面只返回第一次的结果,这时编译器的一种优化处理方式。
attribute((constructor(PRIORITY))) 和 attribute((destructor(PRIORITY)))
PRIORITY 是指执行的优先级,main 函数执行之前会执行 constructor,main 函数执行后会执行 destructor,+load 会比 constructor 执行的更早点,因为动态链接器加载 Mach-O 文件时会先加载每个类,需要 +load 调用,然后才会调用所有的 constructor 方法。
通过这个特性,可以做些比较好玩的事情,比如说类已经 load 完了,是不是可以在 constructor 中对想替换的类进行替换,而不用加在特定类的 +load 方法里。
Clang 警告处理
先看看这个
#pragma clang diagnostic push
#pragma clang diagnostic ignored “-Wdeprecated-declarations”
sizeLabel = [self sizeWithFont:font constrainedToSize:size lineBreakMode:NSLineBreakByWordWrapping];
#pragma clang diagnostic pop如果没有#pragma clang 这些定义,会报出 sizeWithFont 的方法会被废弃的警告,这个加上这个方法当然是为了兼容老系统,加上 ignored “-Wdeprecated-declarations” 的作用是忽略这个警告。通过 clang diagnostic push/pop 可以灵活的控制代码块的编译选项。
使用 libclang 来进行语法分析
使用 libclang 里面提供的方法对源文件进行语法分析,分析语法树,遍历语法树上每个节点。
使用这个库可以直接使用 C 的 API,官方也提供了 python binding。还有开源的 node-js / ruby binding,还有 Objective-C的开源库 GitHub - macmade/ClangKit: ClangKit provides an Objective-C frontend to LibClang. Source tokenization, diagnostics and fix-its are actually implemented. 。
写个 python 脚本来调用 clang
pip install clang
#!/usr/bin/python
# vim: set fileencoding=utf-8
import clang.cindex
import asciitree
import sys
def node_children(node):
return (c for c in node.get_children() if c.location.file == sys.argv[1])
def print_node(node):
text = node.spelling or node.displayname
kind = str(node.kind)[str(node.kind).index(‘.’)+1:]
return ‘{} {}’.format(kind, text)
if len(sys.argv) != 2:
print(“Usage: dump_ast.py [header file name]”)
sys.exit()
clang.cindex.Config.set_library_file(‘/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/libclang.dylib’)
index = clang.cindex.Index.create()
translation_unit = index.parse(sys.argv[1], [‘-x’, ‘objective-c’])
print asciitree.draw_tree(translation_unit.cursor,
lambda n: list(n.get_children()),
lambda n: “%s (%s)” % (n.spelling or n.displayname, str(n.kind).split(“.”)[1]))基于语法树的分析还可以针对字符串做加密。
LibTooling 对语法树完全的控制
因为 LibTooling 能够完全控制语法树,那么可以做的事情就非常多了。
- 可以改变 clang 生成代码的方式。
- 增加更强的类型检查。
- 按照自己的定义进行代码的检查分析。
- 对源码做任意类型分析,甚至重写程序。
- 给 clang 添加一些自定义的分析,创建自己的重构器。
- 基于现有代码做出大量的修改。
- 基于工程生成相关图形或文档。
- 检查命名是否规范,还能够进行语言的转换,比如把 OC 语言转成JS或者 Swift 。
官方有个文档开发者可以按照这个里面的说明去构造 LLVM,clang 和其工具: Tutorial for building tools using LibTooling and LibASTMatchers — Clang 4.0 documentation
按照说明编译完成后进入 LLVM 的目录 ~/llvm/tools/clang/tools/ 在这了可以创建自己的 clang 工具。这里有个范例: GitHub - objcio/issue-6-compiler-tool: Example code for a standalone clang/llvm tool. 可以直接 make 成一个二进制文件。
下面是检查 target 对象中是否有对应的 action 方法存在检查的一个例子
@interface Observer
+ (instancetype)observerWithTarget:(id)target action:(SEL)selector;
@end//查找消息表达式,observer 作为接受者,observerWithTarget:action: 作为 selector,检查 target 中是否存在相应的方法。
virtual bool VisitObjCMessageExpr(ObjCMessageExpr *E) {
if (E->getReceiverKind() == ObjCMessageExpr::Class) {
QualType ReceiverType = E->getClassReceiver();
Selector Sel = E->getSelector();
string TypeName = ReceiverType.getAsString();
string SelName = Sel.getAsString();
if (TypeName == “Observer” && SelName == “observerWithTarget:action:”) {
Expr *Receiver = E->getArg(0)->IgnoreParenCasts();
ObjCSelectorExpr* SelExpr = cast<ObjCSelectorExpr>(E->getArg(1)->IgnoreParenCasts());
Selector Sel = SelExpr->getSelector();
if (const ObjCObjectPointerType *OT = Receiver->getType()->getAs<ObjCObjectPointerType>()) {
ObjCInterfaceDecl *decl = OT->getInterfaceDecl();
if (! decl->lookupInstanceMethod(Sel)) {
errs() << “Warning: class “ << TypeName << “ does not implement selector “ << Sel.getAsString() << “\n”;
SourceLocation Loc = E->getExprLoc();
PresumedLoc PLoc = astContext->getSourceManager().getPresumedLoc(Loc);
errs() << “in “ << PLoc.getFilename() << “ <“ << PLoc.getLine() << “:” << PLoc.getColumn() << “>\n”;
}
}
}
}
return true;
}Clang Plugin
通过自己写个插件,比如上面写的 LibTooling 的 clang 工具,可以将这个插件动态的加载到编译器中,对编译进行控制,可以在 LLVM 的这个目录下查看一些范例 llvm/tools/clang/tools
动态化方案 DynamicCocoa 中就是使用了一个将 OC 源码转 JS 的插件来进行代码的转换,这里整理了些利用 clang 转 js 的库 clangtojs资源 - Lmsgsendnilself ,JSPatch 是直接手写 JS 而没有转换的过程,所以也就没有多出这一步,而鹅厂的OCS更猛,直接在端内写了个编译器。在 C 函数的调用上孙源有个 slides 可以看看: Calling Conventions in Cocoa by sunnyxx bang 也有篇文章: 如何动态调用 C 函数 « bang’s blog 。
这三个方案作者都分别写了文章详细说明其实现方案。
滴滴的王康在做瘦身时也实现了一个自定义的 clang 插件,具体自定义插件的实现可以查看他的这文章 《基于clang插件的一种iOS包大小瘦身方案》
那么我们要自己动手做应该怎么入门呢,除了本身带的范例外还有些教程可以看看。
- 官方 clang 的插件: External Clang Examples
- 收集一些如何使用 clang 库的例子:GitHub - loarabia/Clang-tutorial: A collection of code samples showing usage of clang and llvm as a library
- 在 Xcode 中添加 clang 静态分析自定义 checks: Running the analyzer within Xcode
- 将 LLVM C 的 API 用 swift 来包装: GitHub - harlanhaskins/LLVMSwift: A Swifty wrapper for the LLVM C API version 3.9.1
LLVM Backend
首先通过下图看看 LLVM Backend 在整个 LLVM 里所处的位置: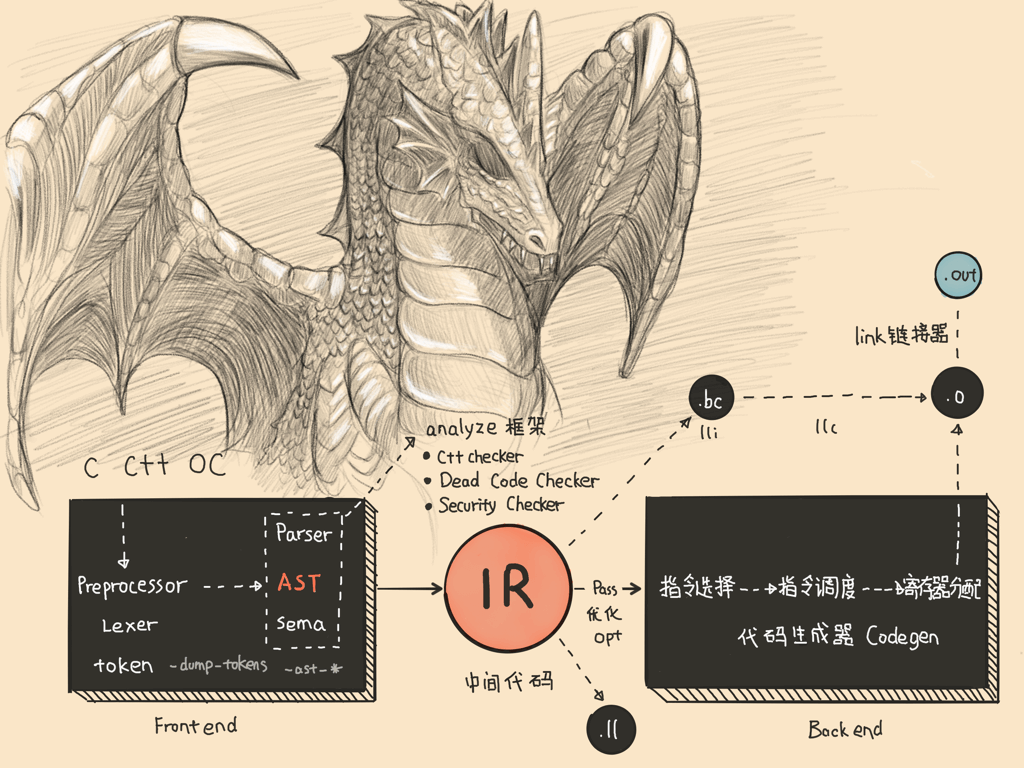
接下来是整个 LLVM Backend 的流程图,后面会对每个过程详细说明
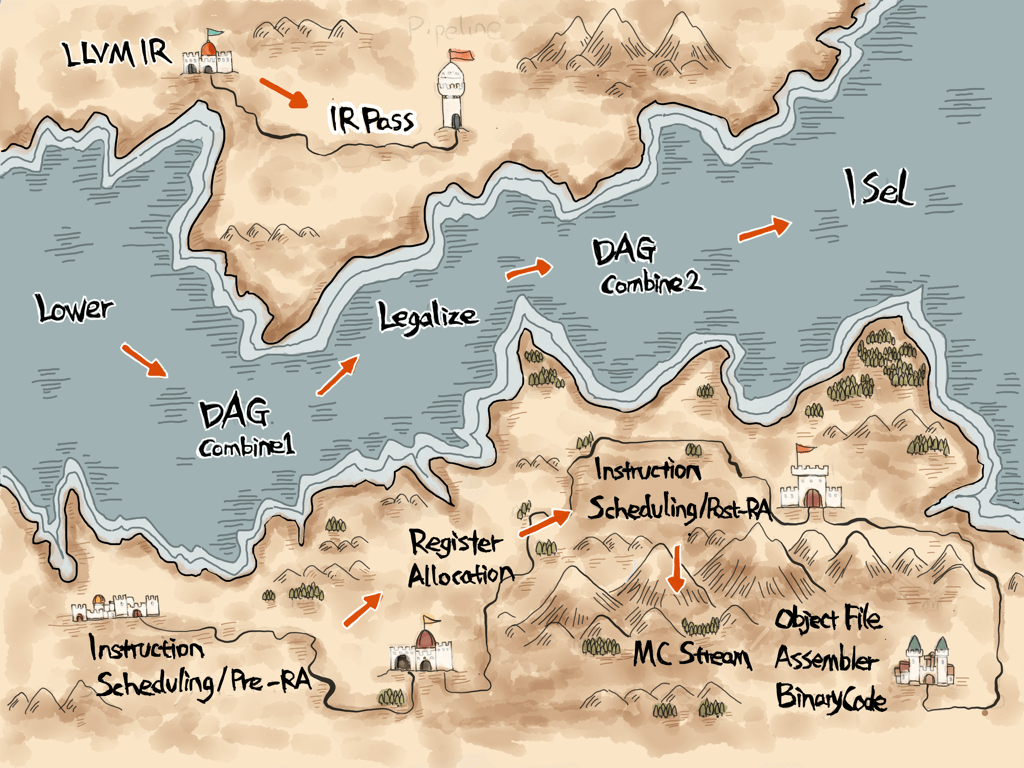
CodeGen 阶段
- Instruction Selection 指令选择:将IR转化成目标平台指令组成的定向非循环图 DAG(Directed Acyclic Graph)。选择既能完成指定操作,又能执行时间最短的指令。
- Scheduling and Formation 调度与排序:读取 DAG,将 DAG 的指令排成 MachineInstr 的队列。根据指令间的依赖进行指令重排使得能够更好的利用 CPU 的功能单元。
- SSA 优化:多个基于 SSA(Static Single Assignment) 的 Pass 组成。比如 modulo-scheduling 和 peephole optimization 都是在这个阶段完成的
- Register allocation 寄存器分配:将 Virtual Register 映射到 Physical Register 或内存上
Prolog / Epilog 生成 - 确定所需堆栈大小:Machine Code
- 晚期优化:最后一次优化机会
- Code Emission:输出代码,可以选择汇编或者二进制机器码。
SelectionDAG
- 构建最初的 DAG:把 IR 里的 add 指令转成 SelectionDAG 的 add 节点
- 优化构建好的 DAG:把一些平台支持的 meta instructions 比如 Rotates,div / rem 指令识别出
- Legalization SelectionDAG 类型:比如某些平台只有64位浮点和32位整数运算指令,那么就需要把所有 f32 都提升到 f64,i1/i8/i16 都提升到 i32,同时还要把 i64 拆分成两个 i32 来存储,操作符的合法化,比如 SDIV 在 x86 上回转成 SDIVREM。这个过程结果可以通过 llc -view-dag-combine2-dags sum.ll 看到
- 指令选择 instruction selector(ISel):将平台无关的 DAG 通过 TableGen 读入 .tb 文件并且生成对应的模式匹配代码从而转成平台相关的 DAG
- SelectionDAG Scheduling and Formation:因为 CPU 是没法执行 DAG,所以需要将指令从 DAG 中提取依据一定规则比如 minimal register pressure 或隐藏指令延迟重排成指令队列。(DAG -> linear list(SSA form) -> MachineInstr -> MC Layer API MCInst MCStreamr -> MCCodeEmitter -> Binary Instr)
下图是 llc -view-isel-dags 状态下的 DAG 图:
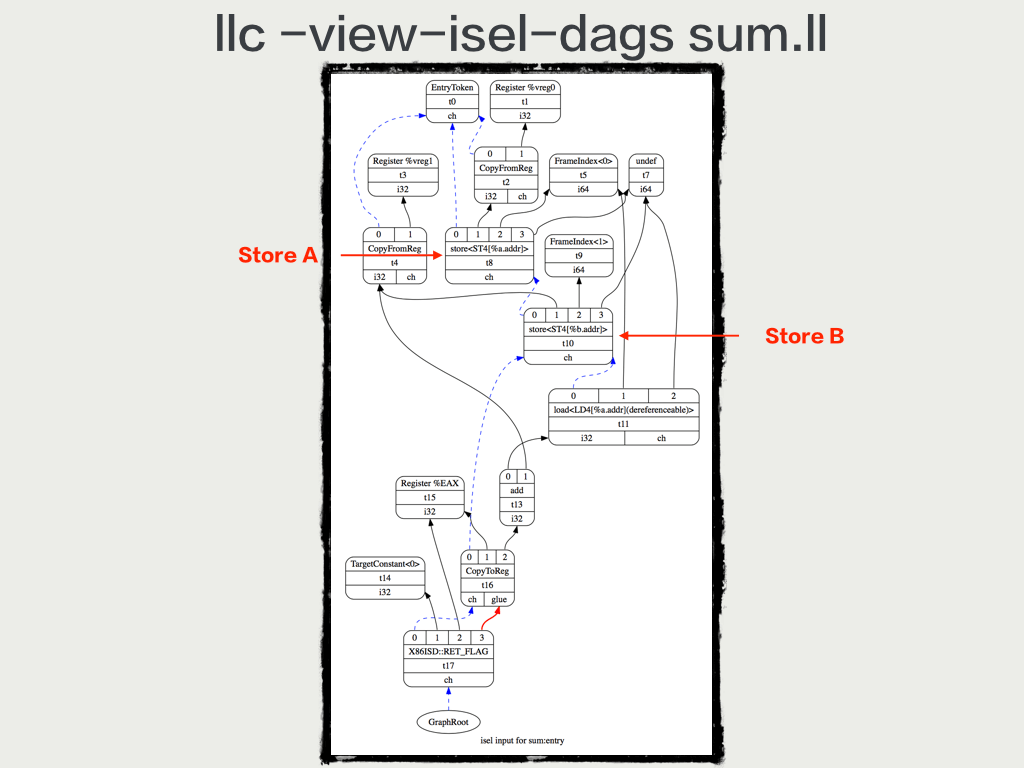
查看 DAG 不同状态的说明如下:
- -view-dag-combine1-dags:可以显示没有被优化的 DAG
- -view-legalize-dags:合法化之前的 DAG
- -view-dag-cmobine2-dags:第二次优化前
- -view-isel-dags:显示指令选择前的 DAG
- -view-sched-dags:在 Scheduler 之前 ISel 之后
- -view-sunit-dags:可以显示 Scheduler 的依赖图
SDNode
DAG 的节点都是有 SDNode 所构成,它的主要是作为 dag 值的操作符,描述这个 dag 所代表的操作,操作数。在 LLVM 里 SDNode 的定义出现在 SelectDAGNodes.h 还有就是 TargetSelectionDAG.td 里,每个 SelectionDAG 节点类型都有一个对应的 SDNode 定义。
class SDNode<string opcode, SDTypeProfile typeprof, list<SDNodeProperty> props = [], string sdclass ="SDNode"> :SDPatternOperator {
stringOpcode = opcode;
string SDClass= sdclass;
list<SDNodeProperty> Properties = props;
SDTypeProfileTypeProfile = typeprof; //类型
}
//类型要求
class SDTypeProfile<intnumresults, int numoperands, list<SDTypeConstraint>constraints> {
int NumResults= numresults; //多少个结果
int NumOperands= numoperands; //多少个操作数
list<SDTypeConstraint> Constraints = constraints; //类型的约束
}
//描述对操作数类型的约束
class SDTypeConstraint<intopnum> {
int OperandNum= opnum; //指明该约束适用第几个操作数
}目标机器可以根据自己的需求定制约束来描述自己特有的指令。
SDNodeProperty 是 SDNode 的属性,用来描述 SDNode 操作的特征。
PatFrag 可复用的结构
为了支持高级语言的特性,TD 也通过 PatFrag 来支持,在SelectionTargetDAG.td 里定义的,这样就可以支持数据与结构的复用。
class PatFrag<dag ops, dag frag, code pred = [{}], SDNodeXForm xform =NOOP_SDNodeXForm> : SDPatternOperator {
dag Operands= ops; //操作数
dag Fragment= frag; //所指定的
code PredicateCode = pred; //表示嵌入生成的指令选择器的代码,满足条件采用用这个 PatFrag
code ImmediateCode = [{}];
SDNodeXForm OperandTransform = xform;
}Pattern 匹配指令
Pattern 主要是解决复杂操作的 DAG 模式,LLVM 会使用贪婪匹配自动完成这个指令选择。定义在 Target.td 里。
class Pattern<dag patternToMatch, list<dag>resultInstrs> {
dagPatternToMatch = patternToMatch;
list<dag>ResultInstrs = resultInstrs;
list<Predicate> Predicates = [];
int AddedComplexity = 0;
}Predicate
在 Pattern 和 Instruction 的定义里都有 Predicates。满足 Predicates 的条件才能够继续,定义也在 Target.td 里
class Predicate<string cond> {
string CondString = cond;
//汇编匹配器的 predicate
bit AssemblerMatcherPredicate = 0;
//被测试的子 target 的名称用作汇编匹配器的替代条件字符串
string AssemblerCondString = "";
//用户级别的 name 给 predicate 用,主要用在诊断时在汇编匹配器里缺少功能。
string PredicateName = "";
}这个 Predicate 实际上就是一个容器,转么装嵌入代码的,然后把这个代码插入到合适的地方来对某些局限的指令进行筛选过滤。
Itinerary 和 SchedRW 调度信息
Itinerary 和 SchedRW 在 Instruction 里定义,用来描述指令调度的信息。目标机器平台会从 InstrltinClass 来派生对应指令的定义,比如 X86,它的指令很多而且复杂所以定义的 InstrltinClass 派生定义数量也很多,都在 X86Schedule.td 里。每条指令都对应一个 InstrltinClass 定义。比如除法的 InstrltinClass 的定义:
def IIC_DIV8_MEM : InstrItinClass;
def IIC_DIV8_REG : InstrItinClass;
def IIC_DIV16 : InstrItinClass;
def IIC_DIV32 : InstrItinClass;
defIIC_DIV64 : InstrItinClass;执行步骤是由 InstrStage 来描述:
class InstrStage<int cycles, list<FuncUnit> units, int timeinc = -1, ReservationKind kind =Required> {
int Cycles = cycles; //完成这个步骤需要的周期数
list<FuncUnit> Units = units; //用于完成该步骤功能单元的选择
int TimeInc = timeinc; //从步骤开始到下个步骤需要多少周期
int Kind = kind.Value;
}通过 InstrltinData 将 InstrltinClass 和 stages 绑在一起使得指令能顺序执行。
class InstrItinData<InstrItinClass Class,list<InstrStage> stages, list<int>operandcycles = [], list<Bypass> bypasses= [], int uops = 1> {
InstrItinClass TheClass = Class;
int NumMicroOps = uops; //指令解码后的 mirco operation 的数量,0表示数量不定
list<InstrStage> Stages = stages;
list<int> OperandCycles =operandcycles; //可选周期数
list<Bypass> Bypasses = bypasses; //绕过寄存器,将写操作指令的结果直接交给后面读操作
}TableGen
在 llvm/lib/Target 目录下有各个 CPU 架构的目录。以 X86 举例
- X86.td:架构描述。
- X86CallingConv.td:架构调用规范。
- X86InstrInfo.td:基本指令集。
- X86InstrMMX.td:MMX 指令集。
- X86InstrMPX.td:MPX(MemoryProtection Extensions)指令集。
- X86InstrSGX.td:SGX(Software GardExtensions)指令集。
- X86InstrSSE.td:SSE指令集。
- X86InstrSVM.td:AMD SVM(Secure VirutalMachine)指令集。
- X86InstrTSX.td:TSX(TransactionalSynchronziation Extensions)指令集。
- X86InstrVMX.td:VMX(Virtual MachineExtensions)指令集。
- X86InstrSystem.td:特权指令集。
- X86InstrXOP.td:对扩展操作的描述。
- X86InstrFMA.td:对融合乘加指令的描述。
- X86InstrFormat.td:格式定义的描述。
- X86InstrFPStack.td:浮点单元指令集的描述。
- X86InstrExtension.td:对零及符号扩展的描述。
- X86InstrFragmentsSIMD.td:描述 SIMD 所使用的模式片段。
- X86InstrShiftRotate.td:对 shift 和 rotate 指令的描述。
- X86Instr3DNow.td:3DNow! 指令集的描述。
- X86InstrArithmetic.td:算术指令的描述。
- X86InstrAVX512.td:AVX512 指令集的描述。
- X86InstrCMovSetCC.td:条件 move 及设置条件指令的描述。
- X86InstrCompiler.td:各种伪指令和指令选择中的 Pat 模式。
- X86InstrControl.td:jump,return,call 指令。
- X86RegisterInfo.td:寄存器的描述。
- X86SchedHaswell.td:对 Haswell 机器模型的描述。
- X86SchedSandyBridge.td:对 Sandy Bridge 机器模型的描述。
- X86Schedule.td:指令调度的一般描述。
- X86ScheduleAtom.td:用于 Intel Atom 处理器指令调度。
- X86SchedSandyBridge.td:用于 Sandy Bridge 机器模型的指令调度。
- X86SchedHaswell.td:用于 Haswell 机器模型的指令调度。
- X86ScheduleSLM.td:用于 Intel Silvermont 机器模型的指令调度。
- X86ScheduleBtVer2.td:用于 AMD btver2 (Jaguar) 机器模型的指令调度。
与平台无关的公用的描述在 llvm/include/llvm/target/ 下
- Target.td:每个机器都要实现的平台无关的接口。
- TargetItinerary.td:平台无关的 instruction itineraries 调度接口。
- TargetSchedule.td:平台无关的基于 Tablegen 调度接口。
- TargetSelectionDAG.td:平台无关的 SelectionDAG 调度接口。
- TargetCallingConv.td:平台无关 CallingConv 接口。
llvm/include/llvm/CodeGen 目录包含 ValueTypes.td 是用来描述具有通用性的寄存器和操作数的类型。在 llvm/include/llvm/IR 包含描述平台无关的固有函数 Intrinsics.td 文件,还有平台相关的比如 IntrinsicsX86.td 这样的文件。
TabelGen 类型
- Dag:表示程序中间表达树中的 DAG 结构,是一个递归构造。有“(“DagArg DagArgList”)”,DagArgList ::= DagArg (“,” DagArg)*,DagArg ::= Value [“:” TokVarName] | TokVarName 这几种语法。比如 (set VR128:$dst, (v2i64 (scalar_to_vector (i64 (bitconvert (x86mmx VR64:$src)))))) 这个 dag 值有多层嵌套,表达的意思是将64位标量的源操作数保存在 MMX 寄存器中,先转成 64 位有符号整数,再转成 2Xi64向量,保存到 128 位寄存器。dag 操作都是比如 def 比如 out,in, set 等,再就是 SDNode 比如 scalar_to_vector 和 bitconvert,或者是 ValueType 的派生定义描述值类型比如 VR128,i64,x86mmx 等。
- List:代表队列,有 “[“ ValueList ”]” [“<” Type ”>”],ValueList ::= [ValueListNE],ValueListNE ::= Value (“,” Value)* 这样的语法,比如 [llvm_ptr_ty, llvm_ptr_ty]
- String:C++ 字符串常量
- Bit,int:Bit 代表字节,int 是64位整数
- Bits:代表若干字节,比如“bits<64>”
Register Allocation 寄存器分配
寄存器
寄存器定义在 TargetRegisterInfo.td 里,它们的基类是这样定义的:
class Register<string n, list<string> altNames =[]> {
string Namespace = "";
string AsmName = n;
list<string> AltNames = altNames;
//别名寄存器
list<Register> Aliases = [];
//属于寄存器的子寄存器
list<Register> SubRegs = [];
//子寄存器的索引编号
list<SubRegIndex> SubRegIndices = [];
//可选名寄存器的索引
list<RegAltNameIndex> RegAltNameIndices= [];
//gcc/gdb 定义的号码
list<int> DwarfNumbers = [];
//寄存器分配器会通过这个值尽量减少一个寄存器的指令数量
int CostPerUse = 0;
//决定寄存器的值是否由子寄存器的值来决定
bit CoveredBySubRegs = 0;
//特定硬件的编码
bits<16> HWEncoding = 0;
}根据目标机器可以派生,比如 X86 可以派生出 X86RegisterInfo.td
class X86Reg<string n, bits<16> Enc, list<Register>subregs = []> : Register<n> {
let Namespace= "X86";
letHWEncoding = Enc;
let SubRegs =subregs;
}RegisterClass
为了描述寄存器用途,将相同用途的寄存器归入同一个 RegisterClass。
class RegisterClass<string namespace, list<ValueType>regTypes, int alignment, dagregList, RegAltNameIndex idx = NoRegAltName> : DAGOperand {
string Namespace = namespace;
//寄存器的值类型,寄存器里的寄存器们必须有相同的值类型
list<ValueType> RegTypes = regTypes;
//指定寄存器溢出大小
int Size = 0;
//当寄存器进行存储或者读取时指定排序
int Alignment = alignment;
//指定在两个寄存器之间拷贝时的消耗,默认值是1,意味着使用一个指令执行拷贝,如果是负数意味着拷贝消耗昂贵或者不可能
int CopyCost = 1;
//说明这个 class 里有哪些寄存器。如果 allocation_order_* 方法没有指定,这个同时定义在寄存器分配器的分配顺序
dagMemberList = regList;
//寄存器备用名用在打印操作这个寄存器 class 时。每个寄存器都需要在一个给定的索引里有一个有效的备用名。
RegAltNameIndex altNameIndex = idx;
//指定寄存器 class 是否能用在虚拟寄存器和寄存器分配里。有些寄存器 class 只限制在模型指令操作,这样就需要设置为0
bit isAllocatable = 1;
//列出可选的分配的命令。默认的命令是 memberlist 自己。当寄存器分配者自动移除保留的寄存器并且移动被调用保存的寄存器到最后是足够好的。
list<dag>AltOrders = [];
//这个函数里作用是选择分配给定机器函数顺序,
code AltOrderSelect = [{}];
//寄存器分配器使用贪婪启发式指定分配优先级。如果值高表示优先。这个值的范围在[0,63]
int AllocationPriority = 0;
}寄存器在 LLVM 中的表达
物理寄存器在 LLVM 里均有 1 - 1023 范围内的编号。在 GenRegisterNames.inc 里找到,比如 lib/Target/X86/X86GenRegisterInfo.inc
虚拟寄存器到物理寄存器的映射
直接映射使用 TargetRegisterInfo 和 MachineOperand 中的 API。间接映射的API用 VirtRegMap 以正确插入读写指令实现内存调度
LLVM 自带的寄存器分配算法
llc -regalloc=Greedy add.bc -o ln.s
- Fast - debug 默认,尽可能保存寄存器。
- Basic - 增量分配
- Greedy - LLVM 默认寄存器分配算法,对 Basic 算法变量生存期进行分裂进行高度优化
- PBQP - 将寄存器分配描述成分区布尔二次规划
Code Emission
下图详细表达了整个 Code Emission 的过程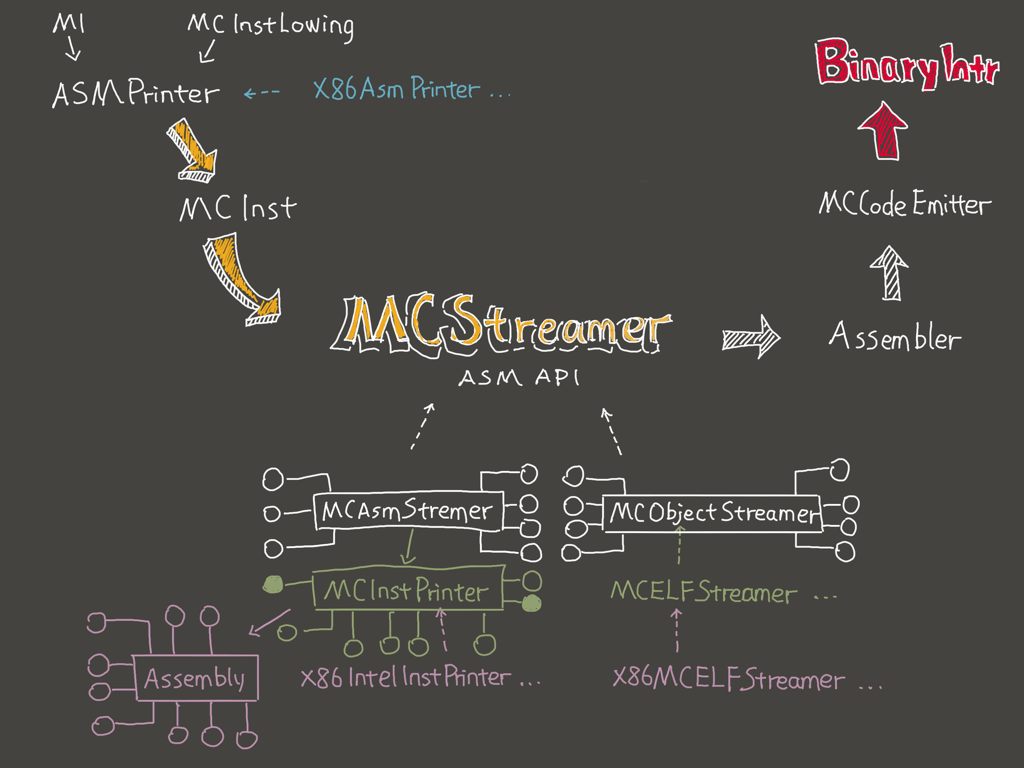
Swift 编译流
Swift 编译流和 Clang 一样都是编译前端,和 Clang 一样代码会被解析成语法数 AST,接下来会比 Clang 多一步,通过 SILGen 生成 SIL 这一次方便做些 Swift 特定的优化,SIL 会被传递给 IR 生成阶段生成 LLVM IR,最后由 LLVM 解决余下事情。看到这里大家肯定会好奇 swift 是如何与 C 和 OC 交互的比如系统底层的模块,这里就要提提 swift 的模块映射了(Module map),它调用 Clang 的模块,将其传入 Clang importer 中生成 AST 来分析是的 swift 能够和 C/OC 进行交互。
下面通过一个例子看详细了解下 Swift 编译流吧。先创建一个 toy.swift
print(“hi!”)生成程序
swiftc toy.swift
./toy生成检查 AST
swiftc -dump-ast toy.swift可以还原之前函数名
swiftc -emit-silgen toy.swift | xcrun swift-demanglellvm ir 和汇编的生成
swiftc -emit-ir toy.swift
swiftc -emit-assembly toy.swift生成可执行的脚本
xcrun -sdk macosx swiftc toy.swift -o toy编译后生成的二进制内容 Link Map File
在 Build Settings 里设置 Write Link Map File 为 Yes 后每次编译都会在指定目录生成这样一个文件。文件内容包含 Object files,Sections,Symbols。下面分别说说这些内容
Object files
这个部分的内容都是 .m 文件编译后的 .o 和需要 link 的 .a 文件。前面是文件编号,后面是文件路径。
Sections
这里描述的是每个 Section 在可执行文件中的位置和大小。每个 Section 的 Segment 的类型分为 __TEXT 代码段和 __DATA 数据段两种。
Symbols
Symbols 是对 Sections 进行了再划分。这里会描述所有的 methods,ivar 和字符串,及它们对应的地址,大小,文件编号信息。
每次编译后生成的 dSYM 文件
在每次编译后都会生成一个 dSYM 文件,程序在执行中通过地址来调用方法函数,而 dSYM 文件里存储了函数地址映射,这样调用栈里的地址可以通过 dSYM 这个映射表能够获得具体函数的位置。一般都会用来处理 crash 时获取到的调用栈 .crash 文件将其符号化。
可以通过 Xcode 进行符号化,将 .crash 文件,.dSYM 和 .app 文件放到同一个目录下,打开 Xcode 的 Window 菜单下的 organizer,再点击 Device tab,最后选中左边的 Device Logs。选择 import 将 .crash 文件导入就可以看到 crash 的详细 log 了。
还可以通过命令行工具 symbolicatecrash 来手动符号化 crash log。同样先将 .crash 文件,.dSYM 和 .app 文件放到同一个目录下,然后输入下面的命令
export DEVELOPER_DIR=/Applications/Xcode.app/Contents/Developer
symbolicatecrash appName.crash appName.app > appName.logMach-O 文件
记录编译后的可执行文件,对象代码,共享库,动态加载代码和内存转储的文件格式。不同于 xml 这样的文件,它只是二进制字节流,里面有不同的包含元信息的数据块,比如字节顺序,cpu 类型,块大小等。文件内容是不可以修改的,因为在 .app 目录中有个 _CodeSignature 的目录,里面包含了程序代码的签名,这个签名的作用就是保证签名后 .app 里的文件,包括资源文件,Mach-O 文件都不能够更改。
Mach-O 文件包含三个区域
- Mach-O Header:包含字节顺序,magic,cpu 类型,加载指令的数量等
- Load Commands:包含很多内容的表,包括区域的位置,符号表,动态符号表等。每个加载指令包含一个元信息,比如指令类型,名称,在二进制中的位置等。
- Data:最大的部分,包含了代码,数据,比如符号表,动态符号表等。
Mach-O 文件的解析
再通过一个例子来分析下:
这次用 xcrun 来
xcrun clang -v先创建一个test.c的文件
touch test.c编辑里面的内容
vi test.c
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("hi there!\n");
return 0;
}编译运行,没有起名默认为 a.out
xcrun clang test.c
./a.outa.out 就是编译生成的二进制文件,下面看看这个二进制文件时如何生成的把。先看看输出的汇编代码
xcrun clang -S -o - test.c | open -f输出的结果里 . 开头的行是汇编指令不是汇编代码,其它的都是汇编代码。先看看前几行
.section __TEXT,__text,regular,pure_instructions
.macosx_version_min 10, 12
.globl _main
.align 4, 0x90.section 指令指定接下来执行哪一个段。
.globl 指令说明 _main 是一个外部符号,因为 main() 函数对于系统来说是需要调用它来运行执行文件的。
.align 指出后面代码的对齐方式,16(2^4) 字节对齐, 0x90 补齐。
看看接下来的 main 函数头部部分
_main: ## @main
.cfi_startproc
## BB#0:
pushq %rbp
Ltmp0:
.cfi_def_cfa_offset 16
Ltmp1:
.cfi_offset %rbp, -16
movq %rsp, %rbp
Ltmp2:
.cfi_def_cfa_register %rbp
subq $32, %rsp_main 是函数开始的地址,二进制文件会有这个位置的引用。
.cfi_startproc 这个指令用于函数的开始,CFI 是 Call Frame Infomation 的缩写是调用帧信息的意思,在用 debugger 时实际上就是 stepping in / out 的一个调用帧。当出现 .cfi_endproc 时表示匹对结束标记出 main() 函数结束。
pushq %rbp 是汇编代码,## BB#0: 这个 label 里的。ABI 会让 rbp 这个寄存器的被保护起来,当函数调用返回时让 rbp 寄存器的值跟以前一样。 ABI 是 application binary interface 的缩写表示应用二进制接口,它指定了函数调用是如何在汇编代码层面上工作的。pushq %rbp 将 rbp 的值 push 到栈中。
.cfi_def_cfa_offset 16 和 .cfi_offset %rbp, -16 会输出一些堆栈和调试信息,确保调试器要使用这些信息时能够找到。
movq %rsp, %rbp 把局部变量放到栈上。
subq $32, %rsp 会将栈指针移动 32 个字节,就是函数调用的位置。旧的栈指针存在 rbp 里作为局部变量的基址,再更新堆栈指针到会使用的位置。
再看看 printf()
leaq L_.str(%rip), %rax
movl $0, -4(%rbp)
movl %edi, -8(%rbp)
movq %rsi, -16(%rbp)
movq %rax, %rdi
movb $0, %al
callq _printfleap 会将 L_.str 这个指针加载到 rax 寄存器里。可以看看 L_.str 的定义
L_.str: ## @.str
.asciz "hi there\n"这个就是我们代码文件里定义的那个字符串。
这里可以看到函数的两个参数分别保存在 edi 和 rsi 寄存器里,根据函数地址做了不同的偏移。
当然也可以看出在这个汇编代码还有能够优化的地方,因为这两个值并没有用,却还是被寄存器存储了。
printf() 是个可变参数的函数,按照 ABI 调用约定存储参数的寄存器数量存储在寄存器 al 中,可变所以数量设置为0,callq 会调用 printf() 函数。
接下来看看返回和函数的结束
xorl %ecx, %ecx
movl %eax, -20(%rbp) ## 4-byte Spill
movl %ecx, %eax
addq $32, %rsp
popq %rbp
retq
.cfi_endprocxorl %ecx, %ecx 相当于将 ecx 寄存器设置为0。ABI 约定 eax 寄存器用来保存函数返回值,拷贝 ecx 到 eax 中,这样 main() 返回值就是0。
函数执行完会恢复堆栈指针,前面是 subq 32 是把 rsp 下移32字节,addq 就是上移归位。然后把 rbp 的值从栈里 pop 出来。ret 会读取出栈返回的地址,.cfi_endproc 和 .cfi_startproc 配对标记结束。
接下来是字符串输出
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "hi there\n"
.subsections_via_symbols同样 .section 指出进入一个新的段。最后 .subsections_via_symbols 是静态链接器用的。
接下来通过 size 工具来看看 a.out 里的 section。
xcrun size -x -l -m a.outSegment __PAGEZERO: 0x100000000 (vmaddr 0x0 fileoff 0)
Segment __TEXT: 0x1000 (vmaddr 0x100000000 fileoff 0)
Section __text: 0x34 (addr 0x100000f50 offset 3920)
Section __stubs: 0x6 (addr 0x100000f84 offset 3972)
Section __stub_helper: 0x1a (addr 0x100000f8c offset 3980)
Section __cstring: 0xa (addr 0x100000fa6 offset 4006)
Section __unwind_info: 0x48 (addr 0x100000fb0 offset 4016)
total 0xa6
Segment __DATA: 0x1000 (vmaddr 0x100001000 fileoff 4096)
Section __nl_symbol_ptr: 0x10 (addr 0x100001000 offset 4096)
Section __la_symbol_ptr: 0x8 (addr 0x100001010 offset 4112)
total 0x18
Segment __LINKEDIT: 0x1000 (vmaddr 0x100002000 fileoff 8192)
total 0x100003000可以看出有四个 segment 和多个section。
在运行时,虚拟内存会把 segment 映射到进程的地址空间,虚拟内存会避免将全部执行文件全部加载到内存。
__PAGEZERO segment 的大小是 4GB,不是文件真实大小,是规定进程地址空间前 4GB 被映射为不可执行,不可写和不可读。
__TEXT segment 包含被执行的代码以只读和可执行的方式映射。
- __text section 包含编译后的机器码。
- __stubs 和 __stub_helper 是给动态链接器 dyld 使用,可以允许延迟链接。
- __cstring 可执行文件中的字符串。
- __const 不可变的常量。
__DATA segment 以可读写和不可执行的方式映射,里面是会被更改的数据。
- __nl_symbol_ptr 非延迟指针。可执行文件加载同时加载。
- __la_symbol_ptr 延迟符号指针。延迟用于可执行文件中调用未定义的函数,可执行文件里没有包含的函数会延迟加载。
- __const 需要重定向的常量,例如 char * const c = “foo”; c指针指向可变的数据。
- __bss 不用初始化的静态变量,例如 static int i; ANSI C 标准规定静态变量必须设置为0。运行时静态变量的值是可修改的。
- __common 包含外部全局变量。例如在函数外定义 int i;
- __dyld 是section占位符,用于动态链接器。
更多 section 类型介绍可以查看苹果文档: OS X Assembler Reference
接下来用 otool 查看下 section 里的内容:
xcrun otool -s __TEXT __text a.outa.out:
Contents of (__TEXT,__text) section
0000000100000f50 55 48 89 e5 48 83 ec 20 48 8d 05 47 00 00 00 c7
0000000100000f60 45 fc 00 00 00 00 89 7d f8 48 89 75 f0 48 89 c7
0000000100000f70 b0 00 e8 0d 00 00 00 31 c9 89 45 ec 89 c8 48 83
0000000100000f80 c4 20 5d c3 这个返回的内容很难读,加个 - v 就可以查看反汇编代码了, -s __TEXT __text 有个缩写 -t
xcrun otool -v -t a.outa.out:
(__TEXT,__text) section
_main:
0000000100000f50 pushq %rbp
0000000100000f51 movq %rsp, %rbp
0000000100000f54 subq $0x20, %rsp
0000000100000f58 leaq 0x47(%rip), %rax
0000000100000f5f movl $0x0, -0x4(%rbp)
0000000100000f66 movl %edi, -0x8(%rbp)
0000000100000f69 movq %rsi, -0x10(%rbp)
0000000100000f6d movq %rax, %rdi
0000000100000f70 movb $0x0, %al
0000000100000f72 callq 0x100000f84
0000000100000f77 xorl %ecx, %ecx
0000000100000f79 movl %eax, -0x14(%rbp)
0000000100000f7c movl %ecx, %eax
0000000100000f7e addq $0x20, %rsp
0000000100000f82 popq %rbp
0000000100000f83 retq看起来是不是很熟悉,和前面的编译时差不多,不同的就是没有汇编指令。
现在来看看可执行文件。
通过 otool 来看看可执行文件头部, 通过 -h 可以打印出头部信息:
otool -v -h a.outMach header
magic cputype cpusubtype caps filetype ncmds sizeofcmds flags
MH_MAGIC_64 X86_64 ALL LIB64 EXECUTE 15 1200 NOUNDEFS DYLDLINK TWOLEVEL PIEmach_header 结构体
struct mach_header {
uint32_t magic;
cpu_type_t cputype;
cpu_subtype_t cpusubtype;
uint32_t filetype;
uint32_t ncmds;
uint32_t sizeofcmds;
uint32_t flags;
};cputype 和 cpusubtype 规定可执行文件可以在哪些目标架构运行。ncmds 和 sizeofcmds 是加载命令。通过 -l 可以查看加载命令
otool -v -l a.out | open -f加载命令结构体
struct segment_command {
uint32_t cmd;
uint32_t cmdsize;
char segname[16];
uint32_t vmaddr;
uint32_t vmsize;
uint32_t fileoff;
uint32_t filesize;
vm_prot_t maxprot;
vm_prot_t initprot;
uint32_t nsects;
uint32_t flags;
};查看 Load command 1 这个部分可以找到 initprot r-x ,表示只读和可执行。
在加载命令里还是看看 __TEXT __text 的section的内容
Section
sectname __text
segname __TEXT
addr 0x0000000100000f50
size 0x0000000000000034
offset 3920
align 2^4 (16)
reloff 0
nreloc 0
type S_REGULAR
attributes PURE_INSTRUCTIONS SOME_INSTRUCTIONS
reserved1 0
reserved2 0addr 的值表示代码的位置地址,在上面反汇编的代码里可以看到地址是一样的,offset 表示在文件中的偏移量。
单个文件的就这样了,但是工程都是多个源文件的,那么多个文件是怎么合成一个可执行文件的呢?那么建多个文件来看看先。
Foo.h
#import <Foundation/Foundation.h>
@interface Foo : NSObject
- (void)say;
@endFoo.m
#import “Foo.h”
@implementation Foo
- (void)say
{
NSLog(@“hi there again!\n”);
}
@endSayHi.m
#import “Foo.h”
int main(int argc, char *argv[])
{
@autoreleasepool {
Foo *foo = [[Foo alloc] init];
[foo say];
return 0;
}
}先编译多个文件
xcrun clang -c Foo.m
xcrun clang -c SayHi.m再将编译后的文件链接起来,这样就可以生成 a.out 可执行文件了。
xcrun clang SayHi.o Foo.o -Wl,`xcrun —show-sdk-path`/System/Library/Frameworks/Foundation.framework/Foundation逆向 Mach-O 文件
需要先安装 tweak,安装越狱可以通过 cydia,不越狱直接打包成 ipa 安装包。越狱的话会安装一个 mobilesubstrate 的动态库,使用 theos 开发工具,非越狱的直接把这个库打包进 ipa 中或者直接修改汇编代码。
Mobilesubstrate 提供了三个模块来方便开发。
- MobileHooker:利用 method swizzling 技术定义一些宏和函数来替换系统或者目标函数。
- MobileLoader:在程序启动时将我们写的破解程序用的第三方库注入进去。怎么注入的呢,还记得先前说的 clang attribute 里的一个 attribute((constructor)) 么,它会在 main 执行之前执行,所以把我们的 hook 放在这里就可以了。
- Safe mode:类似安全模式,会禁用的改动。
先前提到 Mach-O 的结构有 Header,Load commands 和 Data,Mobileloader 会通过修改二进制的 loadCommands 来先把自己注入然后再把我们写的第三方库注入进去,这样破解程序就会放在 Load commands 段里面了。
当然如果是我们自己的程序我们是知道要替换哪些方法的,既然是逆向肯定是别人的程序了,这个时候就需要去先分析下我们想替换方法是哪个,网络相关的分析可以用常用那些抓包工具,比如 Charles,WireShark 等,静态的可以通过砸壳,反汇编,classdump 头文件来分析 app 的架构,对应的常用工具dumpdecrypted,hopper disassembler 和 class_dump。运行时的分析可用工具有运行时控制台cycript,远程断点调试lldb+debugserver,logify。
- 这里有个实例,讲解如何通过逆向实现微信抢红包的插件: 【Dev Club 分享第三期】iOS 黑客技术大揭秘 - DEV CLUB
- 入门文章可以看看这篇: MyArticles/iOS冰与火之歌 at master · zhengmin1989/MyArticles · GitHub
- 玩出新花样: 黑科技:把第三方 iOS 应用转成动态库 - Jun’s Blog,作者另一篇文章: iOS符号表恢复&逆向支付宝 - Jun’s Blog
dyld动态链接
生成可执行文件后就是在启动时进行动态链接了,进行符号和地址的绑定。首先会加载所依赖的 dylibs,修正地址偏移,因为 iOS 会用 ASLR 来做地址偏移避免攻击,确定 Non-Lazy Pointer 地址进行符号地址绑定,加载所有类,最后执行 load 方法和 clang attribute 的 constructor 修饰函数。
用先前 Mach-O 章节的例子继续分析,每个函数,全局变量和类都是通过符号的形式来定义和使用的,当把目标文件链接成一个执行文件时,链接器在目标文件和动态库之间对符号做解析处理。
符号表会规定它们的符号,使用 nm 工具看看
xcrun nm -nm SayHi.o (undefined) external _OBJC_CLASS_$_Foo
(undefined) external _objc_autoreleasePoolPop
(undefined) external _objc_autoreleasePoolPush
(undefined) external _objc_msgSend
0000000000000000 (__TEXT,__text) external _main- OBJC_CLASS$_Foo 表示 Foo 的 OC 符号。
- (undefined) external 表示未实现非私有,如果是私有就是 non-external。
- external _main 表示 main() 函数,处理 0 地址,将要到 __TEXT,__text section
再看看 Foo
xcrun nm -nm Foo.o (undefined) external _NSLog
(undefined) external _OBJC_CLASS_$_NSObject
(undefined) external _OBJC_METACLASS_$_NSObject
(undefined) external ___CFConstantStringClassReference
(undefined) external __objc_empty_cache
0000000000000000 (__TEXT,__text) non-external -[Foo say]
0000000000000060 (__DATA,__objc_const) non-external l_OBJC_METACLASS_RO_$_Foo
00000000000000a8 (__DATA,__objc_const) non-external l_OBJC_$_INSTANCE_METHODS_Foo
00000000000000c8 (__DATA,__objc_const) non-external l_OBJC_CLASS_RO_$_Foo
0000000000000110 (__DATA,__objc_data) external _OBJC_METACLASS_$_Foo
0000000000000138 (__DATA,__objc_data) external _OBJC_CLASS_$_Foo因为 undefined 符号表示该文件类未实现的,所以在目标文件和 Fundation framework 动态库做链接处理时,链接器会尝试解析所有的 undefined 符号。
链接器通过动态库解析成符号会记录是通过哪个动态库解析的,路径也会一起记录。对比下 a.out 符号表看看是怎么解析符号的。
xcrun nm -nm a.out (undefined) external _NSLog (from Foundation)
(undefined) external _OBJC_CLASS_$_NSObject (from CoreFoundation)
(undefined) external _OBJC_METACLASS_$_NSObject (from CoreFoundation)
(undefined) external ___CFConstantStringClassReference (from CoreFoundation)
(undefined) external __objc_empty_cache (from libobjc)
(undefined) external _objc_autoreleasePoolPop (from libobjc)
(undefined) external _objc_autoreleasePoolPush (from libobjc)
(undefined) external _objc_msgSend (from libobjc)
(undefined) external dyld_stub_binder (from libSystem)
0000000100000000 (__TEXT,__text) [referenced dynamically] external __mh_execute_header
0000000100000e90 (__TEXT,__text) external _main
0000000100000f10 (__TEXT,__text) non-external -[Foo say]
0000000100001130 (__DATA,__objc_data) external _OBJC_METACLASS_$_Foo
0000000100001158 (__DATA,__objc_data) external _OBJC_CLASS_$_Foo看看哪些 undefined 的符号,有了更多信息,可以知道在哪个动态库能够找到。
通过 otool 可以找到所需库在哪
xcrun otool -L a.outa.out:
/System/Library/Frameworks/Foundation.framework/Versions/C/Foundation (compatibility version 300.0.0, current version 1349.25.0)
/usr/lib/libSystem.B.dylib (compatibility version 1.0.0, current version 1238.0.0)
/System/Library/Frameworks/CoreFoundation.framework/Versions/A/CoreFoundation (compatibility version 150.0.0, current version 1348.28.0)
/usr/lib/libobjc.A.dylib (compatibility version 1.0.0, current version 228.0.0)libSystem 里有很多我们熟悉的lib
- libdispatch:GCD
- libsystem_c:C语言库
- libsystem_blocks:Block
- libcommonCrypto:加密,比如md5
dylib 这种格式的表示是动态链接的,编译的时候不会被编译到执行文件中,在程序执行的时候才 link,这样就不用算到包的大小里,而且也能够不更新执行程序就能够更新库。
打印什么库被加载了
(export DYLD_PRINT_LIBRARIES=; ./a.out )dyld: loaded: /Users/didi/Downloads/./a.out
dyld: loaded: /System/Library/Frameworks/Foundation.framework/Versions/C/Foundation
dyld: loaded: /usr/lib/libSystem.B.dylib
dyld: loaded: /System/Library/Frameworks/CoreFoundation.framework/Versions/A/CoreFoundation
…数数还挺多的,因为 Fundation 还会依赖一些其它的动态库,其它的库还会再依赖更多的库,这样相互依赖的符号会很多,需要处理的时间也会比较长,这里系统上的动态链接器会使用共享缓存,共享缓存在 /var/db/dyld/。当加载 Mach-O 文件时动态链接器会先检查共享内存是否有。每个进程都会在自己地址空间映射这些共享缓存,这样可以优化启动速度。
动态链接器的作用顺序是怎么样的呢,可以先看看 Mike Ash 写的这篇关于 dyld 的博客: Dynamic Linking On OS X
dyld 做了些什么事
- kernel 做启动程序初始准备,开始由dyld负责。
- 基于非常简单的原始栈为 kernel 设置进程来启动自身。
- 使用共享缓存来处理递归依赖带来的性能问题,ImageLoader 会读取二进制文件,其中包含了我们的类,方法等各种符号。
- 立即绑定 non-lazy 的符号并设置用于 lazy bind 的必要表,将这些库 link 到执行文件里。
- 为可执行文件运行静态初始化。
- 设置参数到可执行文件的 main 函数并调用它。
- 在执行期间,通过绑定符号处理对 lazily-bound 符号存根的调用提供 runtime 动态加载服务(通过 dl*() 这个 API ),并为gdb和其它调试器提供钩子以获得关键信息。runtime 会调用 map_images 做解析和处理,load_images 来调用 call_load_methods 方法遍历所有加载了的 Class,按照继承层级依次调用 +load 方法。
- 在 mian 函数返回后运行 static terminator。
- 在某些情况下,一旦 main 函数返回,就需要调用 libSystem 的 _exit。
查看运行时的调用 map_images 和 调用 +load 方法的相关 runtime 处理可以通过 RetVal 的可debug 的 objc/runtime RetVal/objc-runtime: objc runtime 706 来进行断点查看调用的 runtime 方法具体实现。在 debug-objc 下创建一个类,在 +load 方法里断点查看走到这里调用的堆栈如下:
0 +[someclass load]
1 call_class_loads()
2 ::call_load_methods
3 ::load_images(const char *path __unused, const struct mach_header *mh)
4 dyld::notifySingle(dyld_image_states, ImageLoader const*, ImageLoader::InitializerTimingList*)
11 _dyld_start在 load_images 方法里断点 p path 可以打印出所有加载的动态链接库,这个方法的 hasLoadMethods 用于快速判断是否有 +load 方法。
prepare_load_methods 这个方法会获取所有类的列表然后收集其中的 +load 方法,在代码里可以发现 Class 的 +load 是先执行的,然后执行 Category 的。为什么这样做,原因可以通过 prepare_load_methods 这个方法看出,在遍历 Class 的 +load 方法时会执行 schedule_class_load 这个方法,这个方法会递归到根节点来满足 Class 收集完整关系树的需求。
最后 call_load_methods 会创建一个 autoreleasePool 使用函数指针来动态调用类和 Category 的 +load 方法。
如果想了解 Cocoa 的 Fundation 库可以通过 GNUStep 源码来学习。比如 NSNotificationCenter 发送通知是按什么顺序发送的可以查看 NSNotificationCenter.m 里的 addObserver 方法和 postNotification 方法,看看观察者是怎么添加的和怎么被遍历通知到的。
dyld 是开源的: GitHub - opensource-apple/dyld
还可以看看苹果的 WWDC 视频 WWDC 2016 Session 406 里讲解对启动进行优化。
这篇文章也不错: Dynamic Linking of Imported Functions in Mach-O - CodeProject
LLVM 工具链
获取 LLVM
#先下载 LLVM
svn co http://llvm.org/svn/llvm-project/llvm/trunk llvm
#在 LLVM 的 tools 目录下下载 Clang
cd llvm/tools
svn co http://llvm.org/svn/llvm-project/cfe/trunk clang
#在 LLVM 的 projects 目录下下载 compiler-rt,libcxx,libcxxabi
cd ../projects
svn co http://llvm.org/svn/llvm-project/compiler-rt/trunk compiler-rt
svn co http://llvm.org/svn/llvm-project/libcxx/trunk libcxx
svn co http://llvm.org/svn/llvm-project/libcxxabi/trunk libcxxabi
#在 Clang 的 tools 下安装 extra 工具
cd ../tools/clang/tools
svn co http://llvm.org/svn/llvm-project/clang-tools-extra/trunk extra编译 LLVM
brew install gcc
brew install cmake
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=Release -DBUILD_SHARED_LIBS=ON -DLLVM_TARGETS_TO_BUILD="AArch64;X86" -G "Unix Makefiles" ..
make j8
#安装
make install
#如果找不到标准库,Xcode 需要安装 xcode-select --install
#如果希望是 xcodeproject 方式 build 可以使用 -GXcode
mkdir xcodeBuild
cd xcodeBuild
cmake -GXcode /path/to/llvm/source
在 bin 下存放着工具链,有了这些工具链就能够完成源码编译了。
LLVM 源码工程目录介绍
- llvm/examples/ - 使用 LLVM IR 和 JIT 的例子。
- llvm/include/ - 导出的头文件。
- llvm/lib/ - 主要源文件都在这里。
- llvm/project/ - 创建自己基于 LLVM 的项目的目录。
- llvm/test/ - 基于 LLVM 的回归测试,健全检察。
- llvm/suite/ - 正确性,性能和基准测试套件。
- llvm/tools/ - 基于 lib 构建的可以执行文件,用户通过这些程序进行交互,-help 可以查看各个工具详细使用。
- llvm/utils/ - LLVM 源代码的实用工具,比如,查找 LLC 和 LLI 生成代码差异工具, Vim 或 Emacs 的语法高亮工具等。
lib 目录介绍
- llvm/lib/IR/ - 核心类比如 Instruction 和 BasicBlock。
- llvm/lib/AsmParser/ - 汇编语言解析器。
- llvm/lib/Bitcode/ - 读取和写入字节码
- llvm/lib/Analysis/ - 各种对程序的分析,比如 Call Graphs,Induction Variables,Natural Loop Identification 等等。
- llvm/lib/Transforms/ - IR-to-IR 程序的变换。
- llvm/lib/Target/ - 对像 X86 这样机器的描述。
- llvm/lib/CodeGen/ - 主要是代码生成,指令选择器,指令调度和寄存器分配。
- llvm/lib/ExecutionEngine/ - 在解释执行和JIT编译场景能够直接在运行时执行字节码的库。
工具链命令介绍
基本命令
- llvm-as - 汇编器,将 .ll 汇编成字节码。
- llvm-dis - 反汇编器,将字节码编成可读的 .ll 文件。
- opt - 字节码优化器。
- llc - 静态编译器,将字节码编译成汇编代码。
- lli - 直接执行 LLVM 字节码。
- llvm-link - 字节码链接器,可以把多个字节码文件链接成一个。
- llvm-ar - 字节码文件打包器。
- llvm-lib - LLVM lib.exe 兼容库工具。
- llvm-nm - 列出字节码和符号表。
- llvm-config - 打印 LLVM 编译选项。
- llvm-diff - 对两个进行比较。
- llvm-cov - 输出 coverage infomation。
- llvm-profdata - Profile 数据工具。
- llvm-stress - 生成随机 .ll 文件。
- llvm-symbolizer - 地址对应源码位置,定位错误。
- llvm-dwarfdump - 打印 DWARF。
调试工具
- bugpoint - 自动测试案例工具
- llvm-extract - 从一个 LLVM 的模块里提取一个函数。
- llvm-bcanalyzer - LLVM 字节码分析器。
开发工具
- FileCheck - 灵活的模式匹配文件验证器。
- tblgen - C++ 代码生成器。
- lit - LLVM 集成测试器。
- llvm-build - LLVM 构建工程时需要的工具。
- llvm-readobj - LLVM Object 结构查看器。
Swift 编译
官网: GitHub - apple/swift: The Swift Programming Language
swift 现在是开源的,如果希望能够为它做贡献可以先了解下官方的介绍说明: Swift.org - Contributing
#首先和 LLVM 一样先安装 cmake 和 ninja ,再创建目录
brew install cmake ninja
mkdir swiftsource
cd swiftsource
#clone 下 swift 源码
git clone https://github.com/apple/swift.git
#checkout 相关编译的依赖,比如 llvm,clang,llbuild,lldb,ninja,cmark 等等,目前差不多有13个
./swift/utils/update-checkout —clone
#查看文件夹
du -h -d 1
#build swift,这里的 -x 参数会生成 xcode 的工程文件方便在xcode里阅读。-R 会使用 release 模式,比 debug 快。
./swift/utils/build-script -x -R
#更新
./swift/utils/update-checkout
./swift/utils/build-script -x -R
#切到指定tag和分支
#tag
./swift/utils/update-checkout —tag swift-3.0-RELEASE
#特定分支
./swift/utils/update-checkout —scheme swift-3.0-branchswift 编译是由多个代码仓库组合而成的,各个代码仓库的介绍说明可以查看官方说明: Swift.org - Source Code
其它编译工具
js写的C++解释器JSCPP
适合学生学习时能够方便的在浏览器里直接编c++程序。项目地址:GitHub - felixhao28/JSCPP: A simple C++ interpreter written in JavaScript
C-SMILE 一套支持C/C++ JS JAVA四种语言的scripting language
在 web 中有个 WebAssembly 是个标准,可以使得 web 运行 C/C++ 成为可能。当然还有其它的比如:http://c-smile.sourceforge.net/
资料网址
- http://llvm.org
- http://clang.llvm.org/
- http://www.aosabook.org/en/llvm.html
- GitHub - loarabia/Clang-tutorial: A collection of code samples showing usage of clang and llvm as a library
- Using an external Xcode Clang Static Analyzer binary, with additional checks - Stack Overflow
- LLVM Developers’ Metting