
前言
启动是门面,好的印象也助于留存率提高。苹果也在系统启动上不断努力,提升用户体验,最新的 M1 宣传中还特别强调了翻盖秒开 macOS,可以看出其对极致启动速度的追求。这篇文章提到,据 Akamai 调查,每多1秒等待,转化率会下降7%,KissMetrics 的一份报告说启动超5秒,会使19%的用户放弃等待卸载 App。
高德 App 启动优化专项完成后已经有一段时间了,一直保持实属不易,我一年前在这篇文章里也做了些总结。我这里再补充些启动优化用到一些手段和一些想法,希望这些能够对你有帮助。
通过 Universal Links 和 App Links 优化唤端启动体验
App 都会存在拉新和导流的诉求,如何提高这样场景的用户体验呢?这里会用到唤端技术。包含选择什么样的换端协议,我们先看看唤端路径,如下:
唤端的协议分为自定义协议和平台标准协议,自定义协议在 iOS 端会有系统提示弹框,在 Android 端 chrome 25 后自定义协议失效,需用 Intent 协议包装才能打开 App。如果希望提高体验最好使用平台标准协议。平台标准协议在 iOS 平台叫 Universal Links,在 iOS 9 开始引入的,所以 iOS 9 及以上系统都支持,如果用户安装了要跳的 App 就会直接跳到 App,不会有系统弹框提示。相对应的 Android 平台标准协议叫 App Links,Android 6 以上都支持。
这里需要注意的是 iOS 的 Universal Links 不支持自动唤端,也就是页面加载后自动执行唤端是不行的,需要用户主动点击进行唤端。对于自定义协议和平台标准协议在有些 App 里是遇到屏蔽或者那些 App 自定义弹窗提示,这就只能通过沟通加白来解决了。
另外对于启动时展示 H5 启动页,或唤端跳转特定功能页,可以将拦截判断置前,判断出启动去往功能页,优先加载功能页的任务,主图相关任务项延后再加载,以提升启动到特定页面的速度。
H5启动页
现在 App 启动会在有活动时先弹出活动运营 H5 页面提高活动曝光率。但如果 H5 加载慢势必非常影响启动的体验。
iOS 的话可以使用 ODR(On-Demand Resources) 在安装后先下载下来,点击启动前实际上就可以直接加载本地的了。ODR 安装后立刻下载的模式,下载资源会被清除,所以需要将下载内容移动到自定义的地方,同时还需要做自己兜底的下载来保证在 On-Demand Resources 下载失败时,还能够再从自己兜底服务器上拉下资源。
On-Demand Resources 还能够放很多资源,甚至包括脚本代码的预加载,可以减少包体积。由于使用的是苹果服务器,还能够减少 CDN 产生的峰值成本。
如果不使用 On-Demand Resources 也可以对 WKWebView 进行预加载,虽然安装后第一次还是需要从服务器上加载一次,不过后面就可以从本地快速读取了。
iOS 有三套方案,一套是通过 WKBrowsingContextController 注册 scheme,使用 URLProtocol 进行网络拦截。第二套是基于 WKURLSchemeHandler 自定义 scheme 拦截请求。第三套是在本地搭建 local server,拦截网络请求重定向到本地 server。第三套搭建本地 server 成本高,启动 server 比较耗时。第二套 WKURLSchemeHandler 使用自定义 scheme,对于 H5 适配成本很高,而且需要 iOS 11 以上系统支持。
第一套方案是使用了 WKBrowsingContextController 的 registerSchemeForCustomProtocol: 这个方法,这个方法的参数设置为 http 或 https 然后执行,后面这类 scheme 就能够被 NSURLProtocol 处理了,具体实现可以在这里看到。
Android 通过系统提供的资源拦截Api即可实现加载拦截,拦截后根据请求的url识别资源类型,命中后设置对应的mimeType、encoding、fileStream即可。
下载速度

App 安装前的下载速度也直接影响到了用户从选择你的 App 到使用的体验,如果下载大小过大,用户没有耐心等待,可能就放弃了你的 App,4G5G 环境下超 200MB 会弹窗提示是否继续下载,严重影响转化率。
因此还对下载大小做了优化,将 __TEXT 字段迁移到自定义段,使得 iPhone X 以前机器的下载大小减少了1/3的大小,这招之所以对 iPhone X 以前机器管用的原因是因为先前机器是按照先加密再压缩,压缩率低,而之后机器改变了策略因此下载大小就会大幅减少。Michael Eisel 这篇博客《One Quick Way to Drastically Reduce your iOS App’s Download Size》 提出了这套方案,你可以立刻应用到自己应用中,提高老机器下载速度,效果立竿见影。
Michael Eisel 还用 Swift 包装了 simdjson 写了个库 ZippyJSONDecoder 比系统自带 JSONDecoder 快三倍,很符合本篇“要更快”的主题对吧,人类对速度的追求是没有止境的,最近 YY 大神 ibireme 也在写 JSON 库 YYJSON 速度比 simdjson 还快。Michael 还写个了提速构建的自制链接器 zld,项目说明还描述了如何开发定制自己的链接器。还有主线程阻塞(ANR)检测的 swift 类 ANRChecker,还有通过hook 方式记录系统错误日志的例子展示如何通过截获自动布局错误,函数是 UIViewAlertForUnsatisfiableConstraints ,malloc 问题替换函数为 malloc_error_break 即可。Michael 的这些性能问题处理手段非常实用,真是个宝藏男孩。
通过每月新增激活量、浏览到新增激活转换率、下载到激活转换率、转换率受体积因素影响占比、每个用户获取成本,使用公式计算能够得到每月成本收益,把你们公司对应具体参数数值套到公式中,算出来后你会发现如果降低了50多MB,每月就会有非常大的收益。
对于 Android 来说,很多功能是可以放在云端按需下载使用,后面的方向是重云轻端,云端一体,打通云端链路。
下载和安装完成后,就要分析 App 开始启动时如何做优化了,我接下来跟你说说 Android 启动 so 库加载如何做监控和优化。
Android so 库加载优化
编译阶段-静态分析优化
依托自动化构建平台,通过构建配置实现对源码模块的灵活配置,进行定制化编译。
-ffunction-sections -fdata-sections // 实现按需加载
-fvisibility=hidden -fvisibility-inlines-hidden // 实现符号隐藏这样可以避免无用模块的引入,效果如下图: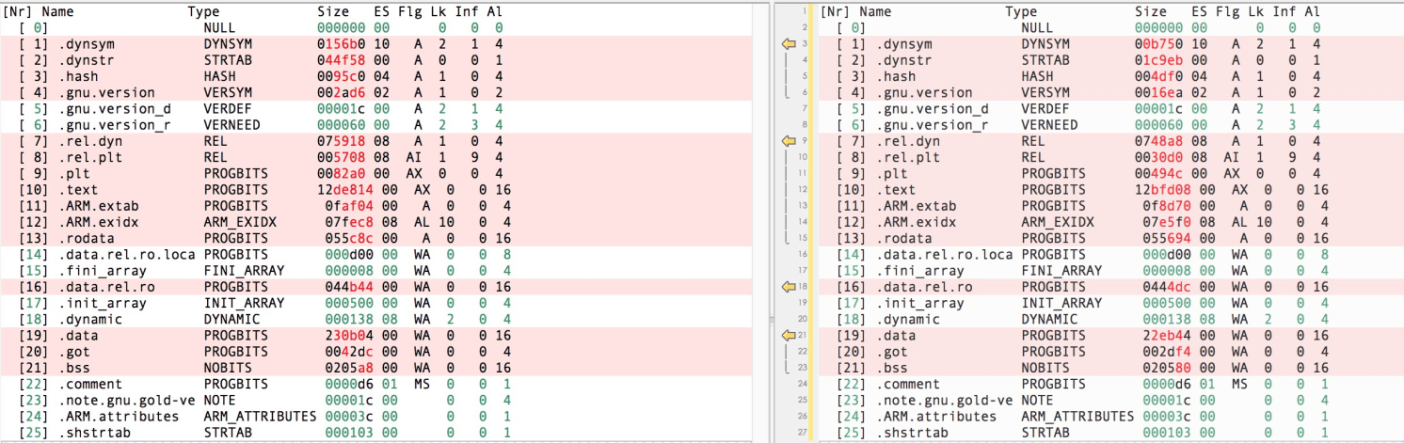
运行阶段-hook分析优化
Android Linker 调用流程如下:
注意,find_library 加载成功后返回 soinfo 对象指针,然后调用其 call_constructors 来调用 so 的 init_array。call_constructors 调用 call_array,其内部循环调用 call_funtion 来访问 init_array 数组的调用。
高德Android小伙伴们基于 frida-gum 的 hook 引擎开发了线下性能监控工具,可以 hook c++ 库,支持 macos、android、ios,针对 so 的全局构造时间和链接时间进行 hook,对关键 so 加载的关键节点耗时进行分析。dlopen 相关 hook 监控点如下:
static target_func_t android_funcs_22[] = {
{"__dl_dlopen", 0, (void *)my_dlopen},
{"__dl_ZL12find_libraryPKciPK12android_dlextinfo", 0, (void *)my_find_library},
{"__dl_ZN6soinfo16CallConstructorsEv", 0, (void *)my_soinfo_CallConstructors},
{"__dl_ZN6soinfo9CallArrayEPKcPPFvvEjb", 0, (void *)my_soinfo_CallArray}
};
static target_func_t android_funcs_28[] = {
{"__dl_Z9do_dlopenPKciPK17android_dlextinfoPKv", 0, (void *)my_do_dlopen_28},
{"__dl_Z14find_librariesP19android_namespace"},
{"__dl_ZN6soinfo17call_constructorsEv", 0, (void *)my_soinfo_CallConstructors},
{"__dl_ZL10call_arrayIPFviPPcS1_EEvPKcPT_jbS5_", 0, (void *)my_call_array_28<constructor_func>},
{"__dl_ZN6soinfo10link_imageERK10LinkListIS"},
{"__dl_g_argc", 0, 0},
{"__dl_g_argv", 0, 0},
{"__dl_g_envp", 0, 0}
};android 版本不同对应 hook 方法有所不同,要注意当 so 有其他外部链接依赖时,针对 dlopen 的监控数据,不只包括自身部分,也包括依赖的 so 部分。在这种情况下,so 加载顺序也会产生很大的影响。
JNI_OnLoad 的 hook 监控代码如下:
#ifdef ABTOR_ANDROID
jint my_JNI_ONLoad(JavaVM* vm, void* reserved) {
asl::HookEngine::HoolContext *ctx = asl::HookEngine::getHookContext();
uint64_t start = PerfUtils::getTickTime();
jint res = asl::CastFuncPtr(my_JNI_OnLoad, ctx->org_func)(vm, reserved);
int duration = (int)(PerfUtils::getTickTime() - start);
LibLoaderMonitorImpl *monitor = (LibLoaderMonitorImpl*)LibLoaderMonitor::getInstance();
monitor->addOnloadInfo(ctx->user_data, duration);
return res;
}
#endif如上代码所示,linker 的 dlopen 完成加载,然后调用 dlsym 来调用目标 so 的 JNI_OnLoad,完成 JNI 涉及的初始化操作。
加载 so 需要注意并行出现 loadLibrary0 锁的问题,这样会让多线程发生等锁现象。可以减少并发加载,但不能简单把整个加载过程放到串行任务里,这样耗时可能会更长,并且没法充分利用资源。比较好的做法是,将耗时少的串行起来同时并行耗时长的 so 加载。
至此完成了 so 的初始化和链接的监控。
说完 Android,那么 iOS 的加载是怎样的,如何优化呢?我接着跟你说。
App 加载
_dyld_start 之前做了什么,dyld_start 是谁调用的,通过查看xnu的源码可以理出,当 App 点击后会通过__mac_execve 函数 fork 进程,加载解析 Mach-O 文件,调用 exec_activate_image() 开始激活 image 的过程。先根据 image 类型来选择 imgact,开始 load_machfile,这个过程会先解析 Mach-O,解析后依据其中的 LoadCommand 启动 dyld。最后使用 activate_exec_state() 处理结构信息,thread_setentrypoint() 设置 entry_point App的入口点。
_dyld_start 之后要少些动态库,因为链接耗时;少些 +load、C 的 constructor 函数和 C++ 静态对象,因为这些会在启动阶段执行,多了就会影响启动时间。因此,没有用的代码就需要定期清理和线上监控。通过元类中flag的方式进行监控然后定期清理。
iOS 主线程方法调用时长检测
+load 方法时间统计,使用运行时 swizzling 的方式,将统计代码放到链接顺序的最前面即可。静态初始化函数在 DATA 的 mod_init_func 区,先把里面原始函数地址保存,前后加上自定义函数记录时间。
在 Linux上 有 strace 工具,还有库跟踪工具 ltrace,OSX 有包装了 dtrace 的 instruments 和 dtruss 工具,不过在某些场景需求下不好用。objc_msgSend 实际上会通过在类对象中查找选择器到函数的映射来重定向执行到实现函数。一旦它找到了目标函数,它就会简单地跳转到那里,而不必重新调整参数寄存器。这就是为什么我把它称为路由机制,而不是消息传递。Objective-C 的一个方法被调用时,堆栈和寄存器是为 objc_msgSend 调用配置的,objc_msgSend 路由执行。objc_msgSend 会在类对象中查找函数表对应定向到的函数,找到目标函数就跳转,参数寄存器不会重新调整。
因此可以在这里 hook 住做统一处理。hook objc_msgSend 还可以获取启动方法列表,用于二进制重排方案中所需要的 AppOrderFiles,不过 AppOrderFiles 还可以通过 Clang SanitizerCoverage 获得,具体可以看宝藏男孩 Michael Eisel 这个这篇博客《Improving App Performance with Order Files》 的介绍。
objc_msgSend 可以通过 fishhook 指定到你定义的 hook 方法中,也可以使用创建跳转 page 的方式来 hook。做法是先用 mmap 分配一个跳转的 page,这个内存后面会用来执行原函数,使用特殊指令集将CPU重定向到内存的任意位置。创建一个内联汇编函数用来放置跳转的地址,利用 C 编译器自动复制跳转 page 的结构,指向 hook 的函数,之前把指令复制到跳转 page 中。ARM64 是一个 RISC 架构,需要根据指令种类检查分支指令。可以在 _objc_msgSend 里找到 b 指令的检查。相关代码如下:
ENTRY _objc_msgSend
MESSENGER_START
cmp x0, #0 // nil check and tagged pointer check
b.le LNilOrTagged // (MSB tagged pointer looks negative)
ldr x13, [x0] // x13 = isa
and x9, x13, #ISA_MASK // x9 = class检查通过就可以用这个指针读取偏移量,并修改指向跳转地址,跳转page完成,hook 函数就可以被调用了。
接下来看下 hook _objc_msgSend 的函数,这个我在以前博客《深入剖析 iOS 性能优化》写过,不过多赘述,只做点补充说明。从这里的源码可以看实现,其中的attribute((naked)) 表示无参数准备和栈初始化, asm 表示其后面是汇编代码,volatile 是让后面的指令避免被编译优化到缓存寄存器中和改变指令顺序,volatile 使其修饰变量被访问时都会在共享内存里重新读取,变量值变化时也能写到共享内存中,这样不同线程看到的变量都是一个值。如果你发现不加 volatile 也没有问题,你可以把编译优化选项调到更优试试。stp表示操作两个寄存器,中括号部分表示压栈存入sp偏移地址,!符号表合并了压栈指令。
save() 的作用是把传递参数寄存器入栈保存,call(b, value)用来跳到指定函数地址,call(blr, &before_objc_msgSend) 是调用原 _objc_msgSend 之前指定执行函数,call(blr, orig_objc_msgSend) 是调用 objc_msgSend 函数,call(blr, &after_objc_msgSend) 是调用原 _objc_msgSend 之后指定执行函数。before_objc_msgSend 和 after_objc_msgSend 分别记录时间,差值就是方法调用执行的时长。
调用之间通过 save() 保存参数,通过 load() 来读取参数。call 的第一个参数是blr,blr 是指跳转到寄存器地址后会返回,由于 blr 会改变 lr 寄存器X30的值,影响 ret 跳到原方法调用方地址,崩溃堆栈找方法调研栈也依赖 lr 在栈上记录的地址,所以需要在 call() 之前对 lr 进行保存,call() 都调用完后再进行恢复。跳转到hook函数,hook函数可以执行我们自定义的事情,完成后恢复CPU状态。
进入主图后的优化
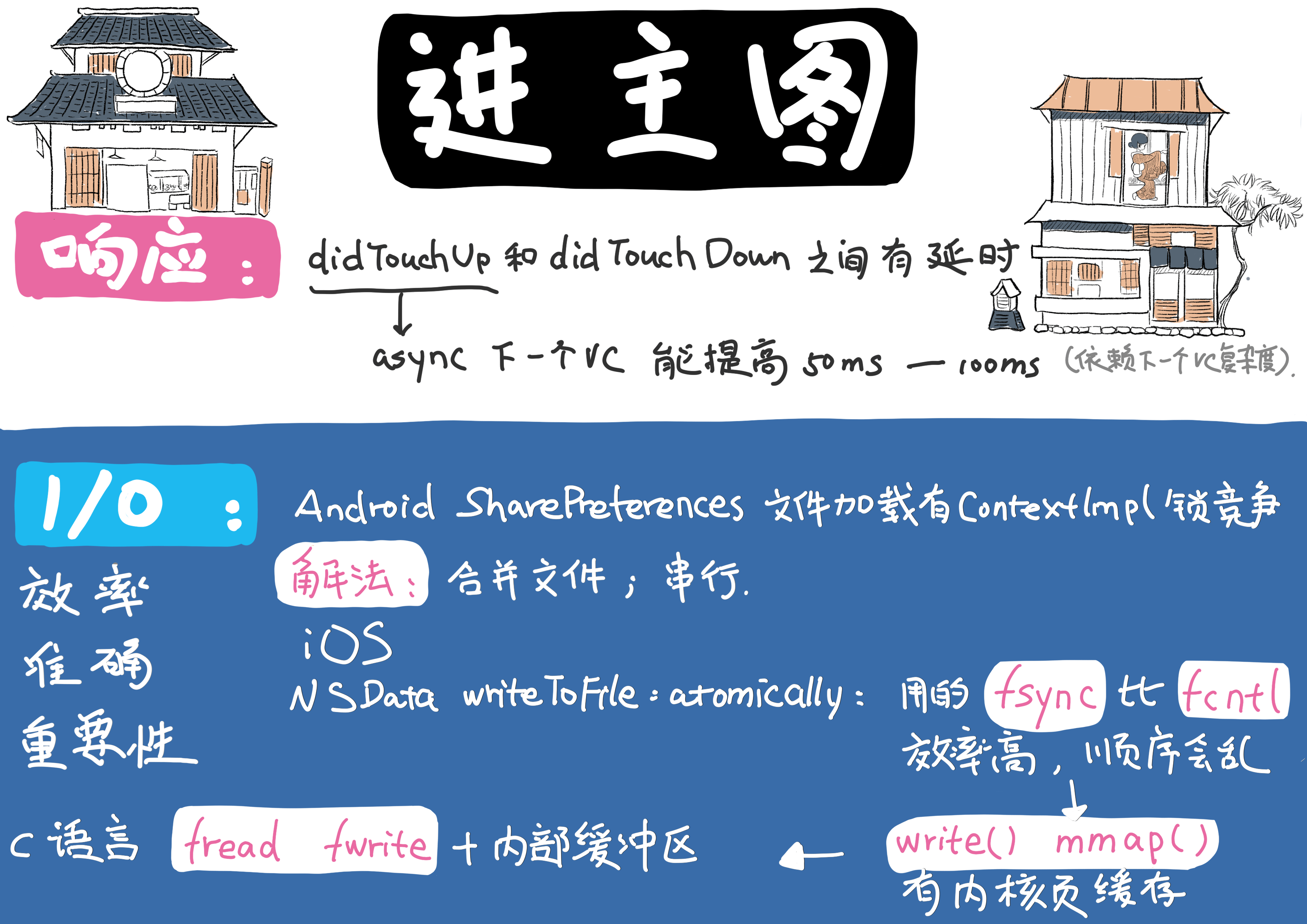
进入主图后,用户就可以点击按钮进入不同功能了,是否能够快速响应按钮点击操作也是启动体验感知很重要的事情。按钮点击的两个事件 didTouchUp 和 didTouchDown 之间也会有延时,因此可以在 didTouchDown 时在主线程先 async 初始化下一个 VC,把初始化提前完成,这样做可以提高50ms-100ms的速度,甚至更多,具体收益依赖当前主线程繁忙情况和下一个页面 viewDidLoad 等初始化方法里的耗时,启动阶段主线程一定不会闲,即使点击后主线程阻塞,使用 async 也能保证下一个页面的初始化不会停。
线程调度和任务编排
整体思路
对于任务编排有种打法,就是先把所有任务滞后,然后再看哪个是启动开始必须要加载的。效果立竿见影,很快就能看到最好的结果,后面就是反复斟酌,严格把关谁才是必要的启动任务了。
启动阶段的任务,先理出相关依赖关系,在框架中进行配置,有依赖的任务有序执行,无依赖独立任务可以在非密集任务执行期串行分组,组内并发执行。
这里需要注意的是Android 的 SharedPreferences 文件加载导致的 ContextImpl 锁竞争,一种解法是合并文件,不过后期维护成本会高,另一种是使用串行任务加载。你可能会疑惑,我没怎么用锁,那是不是就不会有锁等待的问题了。其实不然,比如在 iOS中,dispatch_once 里有 dispatch_atomic_barrier 方法,此方法就有锁的作用,因此锁其实存在各个 API 之下,如不用工具去做检查,有时还真不容易发现这些问题。
有 IO 操作的任务除了锁等待问题,还有效率方面也需要特别注意,比如 iOS 的 Fundation 库使用的是 NSData writeToFile:atomically: 方法,此方法会调用系统提供的 fsync 函数将文件描述符 fd 里修改的数据强写到磁盘里,fsync 相比较与 fcntl 效率高但写入物理磁盘会有等待,可能会在系统异常时出现写入顺序错乱的情况。系统提供的 write() 和 mmap() 函数都会用到内核页缓存,是否写入磁盘不由调用返回是否成功决定,另外 c 的标准库的读写 API fread 和 fwrite 还会在系统内核页缓存同步对应由保存了缓冲区基地址的 FILE 结构体的内部缓冲区。因此启动阶段 IO 操作方法需要综合做效率、准确和重要性三方面因素的权衡考虑,再进行有 IO 操作的任务编排。
针对初始化耗时的库,比如埋点库,可以延后初始化,先将所需要的数据存储到内存中,待到埋点库初始化时再进行记录。对一些主图上业务网络可以延后请求,比如闪屏、消息盒子、主图天气、限行控件数据请求、开放图层数据、Wi-Fi信息上报请求等。
多线程共享数据的问题
并发任务编排缺少一个统一的异步编程模型,并发通信共享数据方式的手段,比如代理和通知会让处理到处飞,闭包这种匿名函数排查问题不方便,而且回调中套回调前期设计后期维护和理解很困难,调试、性能测试也乱。这些通过回调来处理异步,不光复杂难控,还有静态条件、依赖关系、执行顺序这样的额外复杂度,为了解决这些额外复杂度,还需要使用更多的复杂机制来保证线程安全,比如使用低效的 mutex、超高复杂度的读写锁、双重检查锁定、底层原子操作或信号量的方式来保护数据,需要保证数据是正确锁住的,不然会有内存问题,锁粒度要定还要注意避免死锁。
并发线程通信一般都会使用 libdispatch(GCD)这样的共享数据方式来处理,也就异步再回调的方式。libdispatch 的 async 策略是把任务的 block 放到队列链表,使用时会在底层的线程池里找可用线程,有就直接用,没有就新建一个线程(参看 libdispatch 源码,监控线程池 workqueue.c,队列调度 queue.c),使用这样的策略来减少线程创建。当并发任务多时,比如启动期间,即使线程没爆,但 CPU 在各个线程切换处理任务时也是会有时间开销的,每次切换线程,CPU 都需要执行调度程序增加调度成本和增加 CPU 使用率,并且还容易出现多线程竞争问题。单次线程切换看起来不长,但整个启动,切换频率高的话,整体时间就会增大。
多线程的问题以及处理方式,带来了开发和排查问题的复杂性,以及出现问题机率的提高,资源和功能云化也有类似的问题,云化和本地的耦合依赖、云化之间的关系处理、版本兼容问题会带来更复杂的开发以及测试挑战,还有问题排查的复杂度。这些都需要去做权衡,对基础建设方案提出了更高的要求,对容错回滚的响应速度也有更高的要求。
这里有个 book 专门来说并行编程难的,并告诉你该怎么做。这里有篇文章 列出了苹果公司 libdispatch 的维护者 Pierre Habouzit 关于 libdispatch 的讨论邮件。
说了一堆共享数据方式的问题,没有体感,下面我说个最近碰到的多线程问题,你也看看排查有多费劲。
一个具体多线程问题排查思路
问题是工程引入一个系统库,暂叫 A 库,出现的问题现象是 CoreMotion 不回调,网络请求无法执行,除了全局并发队列会 pending block 外主线程和其它队列工作正常。
第一阶段,排查思路看是否跟我们工程相关,首先看是不是各个系统都有此问题,发现 iOS14 和 iOS13 都有问题。然后把A库放到一个纯净 Demo 工程中,发现没有出问题了。基于上面两种情况,推测只有将A库引入我们工程才会出现问题。在纯净 Demo 工程中,A库使用时 CPU 会占用60%-80%,集成到我们工程后涨到100%,所以下个阶段排查方向就是性能。
第二阶段的打法是看是否是由性能引起的问题。先在纯净工程中创建大量线程,直到线程打满,然后进行大量浮点运算使 CPU 到100%,但是没法复现,任务通过 libdispatch 到全局并发队列能正常工作。
怎么在 Demo 里看到出线程已爆满了呢?
libdispatch 可以使用线程数是有上限的,在 libdispatch 的源码里可以看到 libdispatch 的队列初始化时使用 pthread 线程池相关代码:
#if DISPATCH_USE_PTHREAD_POOL
static inline void
_dispatch_root_queue_init_pthread_pool(dispatch_queue_global_t dq,
int pool_size, dispatch_priority_t pri)
{
dispatch_pthread_root_queue_context_t pqc = dq->do_ctxt;
int thread_pool_size = DISPATCH_WORKQ_MAX_PTHREAD_COUNT;
if (!(pri & DISPATCH_PRIORITY_FLAG_OVERCOMMIT)) {
thread_pool_size = (int32_t)dispatch_hw_config(active_cpus);
}
if (pool_size && pool_size < thread_pool_size) thread_pool_size = pool_size;
... // 省略不相关代码
}如上面代码所示,dispatch_hw_config 会用 dispatch_source 来监控逻辑 CPU、物理 CPU、激活 CPU 的情况计算出线程池最大线程数量,如果当前状态是 DISPATCH_PRIORITY_FLAG_OVERCOMMIT,也就是会出现 overcommit 队列时,线程池最大线程数就按照 DISPATCH_WORKQ_MAX_PTHREAD_COUNT 这个宏定义的数量来,这个宏对应的值是255。因此通过查看是否出现 overcommit 队列可以看出线程池是否已满。
什么时候 libdispatch 会创建一个新线程?
当 libdispatch 要执行队列里 block 时会去检查是否有可用的线程,发现有可用线程时,在可用线程去执行 block,如果没有,通过 pthread_create 新建一个线程,在上面执行,函数关键代码如下:
static void
_dispatch_root_queue_poke_slow(dispatch_queue_global_t dq, int n, int floor)
{
...
// 如果状态是overcommit,那么就继续添加到pending
bool overcommit = dq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT;
if (overcommit) {
os_atomic_add2o(dq, dgq_pending, remaining, relaxed);
} else {
if (!os_atomic_cmpxchg2o(dq, dgq_pending, 0, remaining, relaxed)) {
_dispatch_root_queue_debug("worker thread request still pending for "
"global queue: %p", dq);
return;
}
}
...
t_count = os_atomic_load2o(dq, dgq_thread_pool_size, ordered);
do {
can_request = t_count < floor ? 0 : t_count - floor;
// 是否有可用
if (remaining > can_request) {
_dispatch_root_queue_debug("pthread pool reducing request from %d to %d",
remaining, can_request);
os_atomic_sub2o(dq, dgq_pending, remaining - can_request, relaxed);
remaining = can_request;
}
// 线程满
if (remaining == 0) {
_dispatch_root_queue_debug("pthread pool is full for root queue: "
"%p", dq);
return;
}
} while (!os_atomic_cmpxchgvw2o(dq, dgq_thread_pool_size, t_count,
t_count - remaining, &t_count, acquire));
...
do {
_dispatch_retain(dq); // 在 _dispatch_worker_thread 里取任务并执行
while ((r = pthread_create(pthr, attr, _dispatch_worker_thread, dq))) {
if (r != EAGAIN) {
(void)dispatch_assume_zero(r);
}
_dispatch_temporary_resource_shortage();
}
} while (--remaining);
...
}如上面代码所示,can_request 表示可用线程数,通过当前最大可用线程数减去已用线程数获得,赋给 remaining后,用来判断线程是否满和控制线程创建。dispatch_worker_thread 会取任务并执行。
当 libdispatch 使用的线程池中线程过多,并且有 pending 标记,当等待超时,也就是 libdispatch 里 DISPATCH_CONTENTION_USLEEP_MAX 宏定义的时间后,也会触发创建一个新的待处理线程。libdispatch 对应函数关键代码如下:
static bool
__DISPATCH_ROOT_QUEUE_CONTENDED_WAIT__(dispatch_queue_global_t dq,
int (*predicate)(dispatch_queue_global_t dq))
{
...
bool pending = false;
do {
...
if (!pending) {
// 添加pending标记
(void)os_atomic_inc2o(dq, dgq_pending, relaxed);
pending = true;
}
_dispatch_contention_usleep(sleep_time);
...
sleep_time *= 2;
} while (sleep_time < DISPATCH_CONTENTION_USLEEP_MAX);
...
if (pending) {
(void)os_atomic_dec2o(dq, dgq_pending, relaxed);
}
if (status == DISPATCH_ROOT_QUEUE_DRAIN_WAIT) {
_dispatch_root_queue_poke(dq, 1, 0); // 创建新线程
}
return status == DISPATCH_ROOT_QUEUE_DRAIN_READY;
}如上所示,在创建新的待处理线程后,会退出当前线程,负载没了就会去用新建的线程。
接下来使用 Instruments 进行分析 Trace 文件,发现启动阶段立刻开始使用A库的话,CPU 会突然上升,如果使用 A 库稍晚些,CPU 使用率就是稳定正常的。这说明在第一个阶段性能相关结论只是偶现情况才会出现,出问题时,并没有出现系统资源紧张的情况,可以得出并不是性能问题的结论。那么下一个阶段只能从A库的使用和排查我们工程其它功能的问题。
第三个阶段的思路是使用功能二分排查法,先排出 A 库使用问题,做法是在使用最简单的 A 库初始化一个页面在首屏也会复现问题。
我们的功能主要分为渲染、引擎、网络库、基础功能、业务几个部分。将渲染、引擎、网络库拉出来建个Demo,发现这个 Demo 不会出现问题。那么有问题的就可能在基础功能、业务上。
先去掉的功能模块有 CoreMotion、网络、日志模块、定时任务(埋点上传),依然复现。接下来去掉队列里的 libdispatch 任务,队列里的任务主要是由 Operation 和 libdispatch 两种方式放入。其中 Operation 最后是使用 libdispatch 将任务 block 放入队列,期间会做优先级和并发数的判断。对于 libdispatch 可以 Hook 住可以把任务 block 放到队列的 libdispatch 方法,有 dispatch_async、dispatch_after、dispatch_barrier_async、dispatch_apply 这些方法。任务直接返回,还是有问题。
推测验证基础能力和业务对出现问题队列有影响,instruments 只能分析线程,无法分析队列,因此需要写工具分析队列情况。
接下来进入第四个阶段。
先 hook 时截获任务 block 使用的 libdispatch 方法、执行队列名、优先级、做唯一标识的入队时间、当前队列的任务数、还有执行堆栈的信息。通过截获的内容按照时间线看,当出现全局并发队列 pending block 数量堆积时,新的使用 libdispatch 加入的部分任务可以得到执行,也有没执行的,都执行了也会有问题。
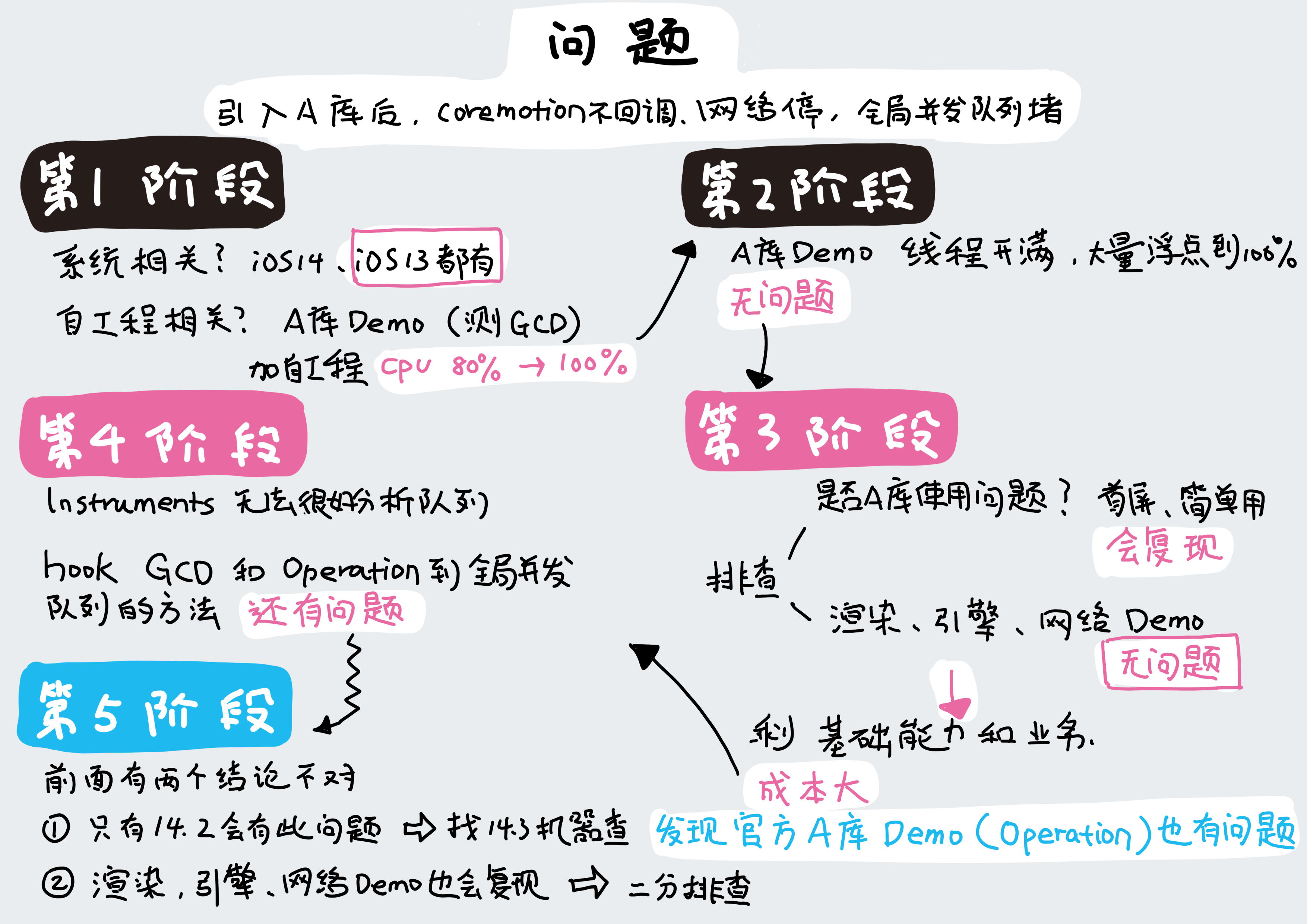
然后去掉 Operation 的任务:通过日志还能发现 Operation 调用 libdispatch 的任务直接 hook libdispatch 的方法是获取不到的,可能是 Operation 调用方法有变化。另外在无法执行任务的线程上新建的 libdispatch 任务也无法执行,无法执行的 Operation 任务达到所设置的 maxConcurrentOperationCount,对应的 OperationQueue 就会在 Operation 的队列里 pending。由此可以推断出,在局并发队列 pending 的 block 包含了直接使用 libdispatch 的和 Operation 的任务,pending 的任务。因此还需要 hook 住 Operation,过滤掉所有添加到 Operation Queue 的任务,但结果还是复现问题。
此时很崩溃,本来做好了一个一个下掉功能的准备(成本高),这时,有同学发现前阶段两个不对的结论。
这个阶段定为第五阶段。
第一个不对的结论是经 QA 同学长时间多轮测试,只在14.2及以上系统版本有问题,由于只有这个版本才开始有此问题,推断可能是系统 bug;第二个不对的是只有渲染、引擎、网络库的 Demo 再次检查,可复现问题,因此可以针对这个 Demo 进行进一步二分排查。
于是,咱们针对两个先前错误结论,再次出发,同步进行验证。对 Demo 排除了网络库依然复现,后排除引擎还是复现,同时使用了自己的示例工程在iOS14.2上复现了问题,和第一阶段纯净Demo的区别是往全局并发队列里方式,官方 Demo 是 Operation,我们的是 libdispatch。
因此得出结论是苹果系统升级问题,原因可能在 OperationQueue,问题重现后,不再运行其中的 operation。14.3beta 版还没有解决。五个阶段总结如下图所示:
那么看下 Operation 实现,分析下系统 bug 原因。
ApportableFoundation 里有Operation的开源实现 NSOperation.m,相比较 GNUstep 和 Cocotron 更完善,可以看到 Operation 如何在 _schedulerRun 函数里通过 libdispatch 的 async 方法将 operation 的任务放到队列执行。
swift源码里的fundation也有实现 Operation,我们看看 _schedule 函数的关键代码:
internal func _schedule() {
...
// 按优先级顺序执行
for prio in Operation.QueuePriority.priorities {
...
while let operation = op?.takeUnretainedValue() {
...
let next = operation.__nextPriorityOperation
...
if Operation.__NSOperationState.enqueued == operation._state && operation._fetchCachedIsReady(&retest) {
if let previous = prev?.takeUnretainedValue() {
previous.__nextPriorityOperation = next
} else {
_setFirstPriorityOperation(prio, next)
}
...
if __mainQ {
queue = DispatchQueue.main
} else {
queue = __dispatch_queue ?? _synthesizeBackingQueue()
}
if let schedule = operation.__schedule {
if operation is _BarrierOperation {
queue.async(flags: .barrier, execute: {
schedule.perform()
})
} else {
queue.async(execute: schedule)
}
}
op = next
} else {
... // 添加
}
}
}
...
}上述代码可见,可以看到 _schedule 函数根据 Operation.QueuePriority.priorities 优先级数组顺序,从最高 barrier 开始到 veryHigh、high、normal、low 到最低的 veryLow,根据 operation 属性设置决定 libdispatch 的 queue 是什么类型的,最后通过 async 函数分配到对应的队列上执行。
查看 operation 代码更新情况,最新 operation 提交修复了一个问题,commit 在这,根据修复问题的描述来看,和 A 库引入导致队列不可添加 OperationQueue 的情况非常类似。修复的地方可以看下图: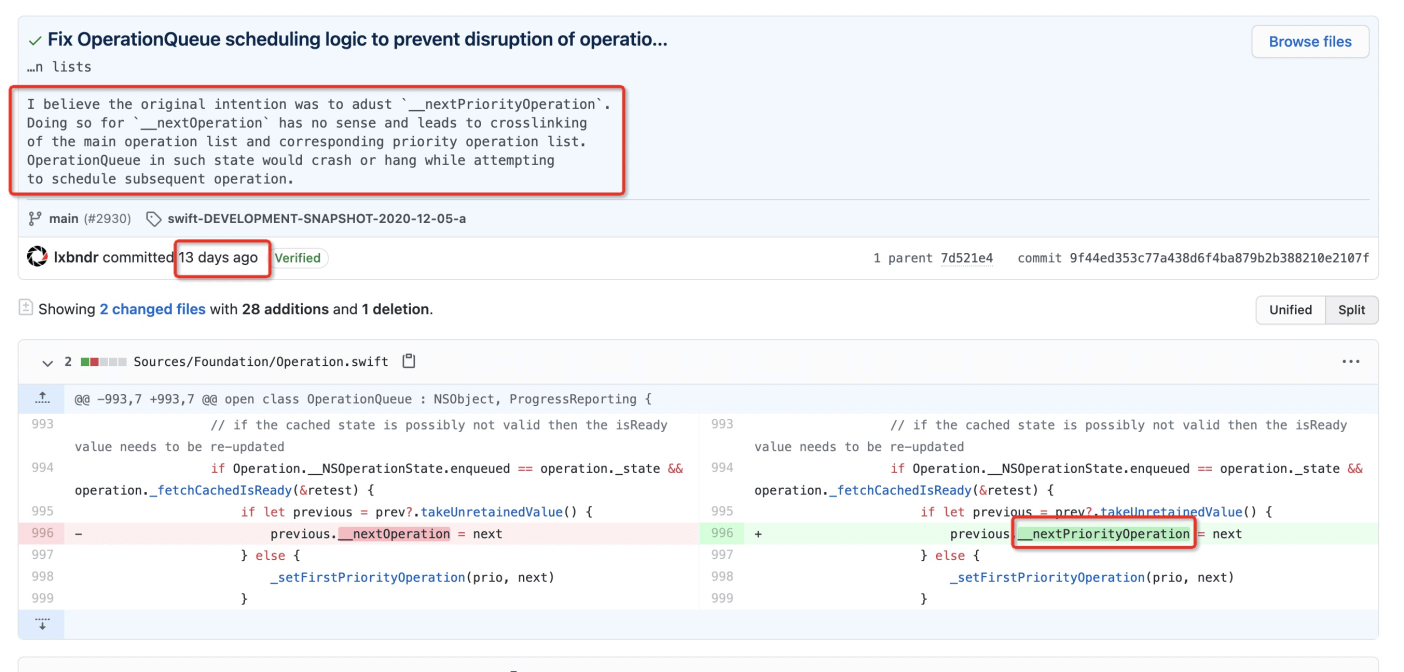
如图所示,在先前 _schedule 函数里使用 nextOperation 而不用 nextPriorityOperation 会导致主操作列表里的不同优先级操作列表交叉连接,可能会在执行后面操作时被挂起,而 A 库里的 OperationQueue 都是高优的,如果有其它优先级的 OperationQueue 加进来就会出现挂起的问题。
从提交记录看,19年6月12日的那次提交变更了很多代码逻辑,描述上看是为了更接近 objc 的实现,changePriority 函数就是那个时候加进去的。提交的 commit 如下图所示: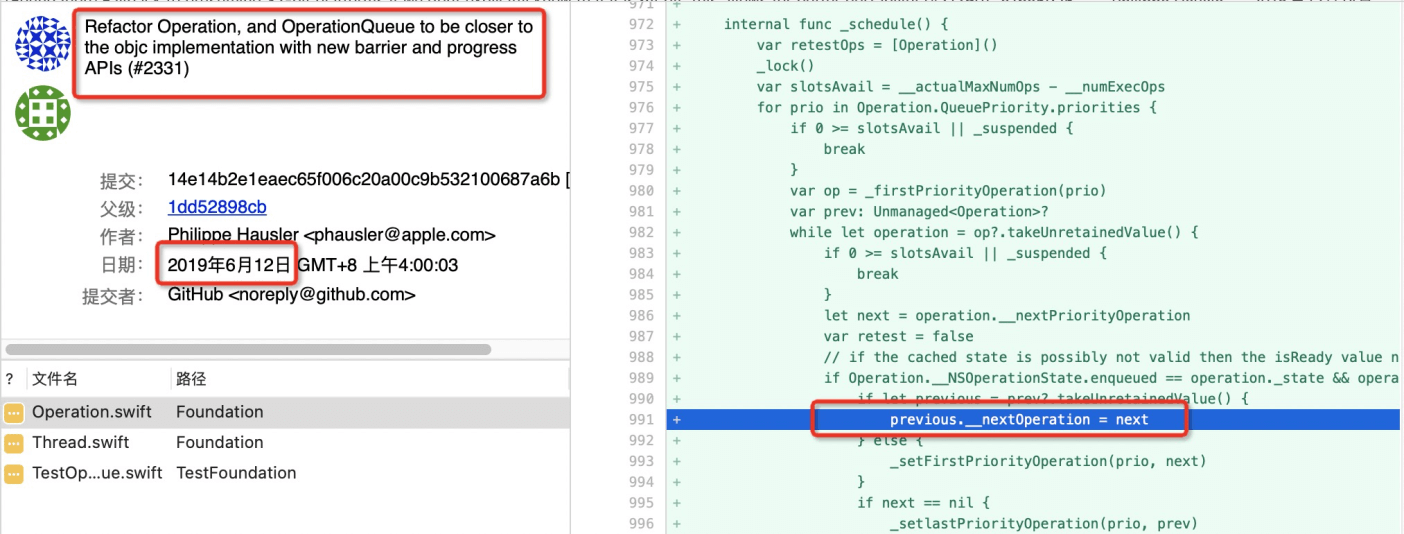
怀疑(只是怀疑,苹果官方并没有说)可能是在 iOS14 引入 swift 版的 Operation,因此这个 Operation 针对 objc 调用做了适配。之所以14.2之前 Operation 重构后的 bug 没有引起问题,可能是当时 A 库的 Queue 优先级还没调高,14.2版本A库的 Queue 优先级开始调高了,所以出现了优先级交叉挂起的情况。
从这次排查可以发现,目前对于并发的监测还是非常复杂的。那么并发问题在 iOS 的将来会得到解决吗?
多线程并行计算模型
既然共享数据方式问题多,那还有其它选择吗?
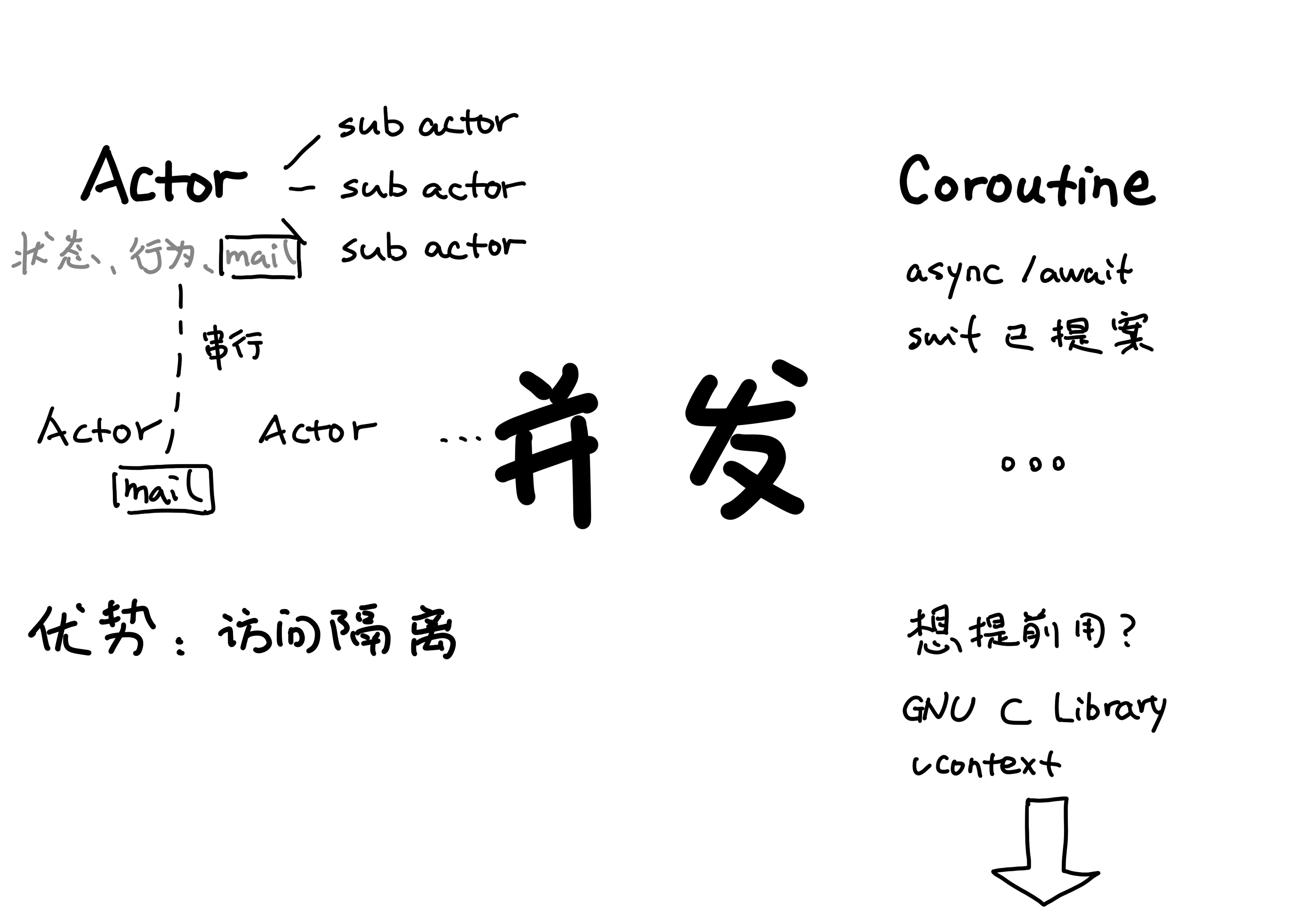
实际上在服务端大量使用着 Actor 这样的并行计算模型,在并行世界里,一切都是 actor,actor 就像一个容器,会有自己的状态、行为、串行队列的消息邮箱。actor 之间使用消息来通信,会把消息发到接受消息 actor 的消息邮箱里,消息盒子可并行接受消息,消息的处理是依次进行,当前处理完才处理下一个,消息邮箱这套机制就好像 actor 们的大管家,让 actor 之间的沟通井然有序。
有谁是在使用 actor 模型呢?
actor 历史悠久,Erlang(Elang设计论文),Akka(Scala 编写的 Akka actor 系统,Akka 使用多,相对成熟)、Go(使用的 goroutine,基于 CSP 构建)都是基于 actor 模型实现数据隔离。
Swift并发路线图也预示着 Swift 要加入 actor,Chris Lattner 也希望 Swift 能够在多核机器,还有大型服务集群能够得到方便的使用,分布式硬件的发展趋势必定是多核,去共享内存的硬件的,因为共享内存的编程不光复杂而且原子性访问比非原子性要慢近百倍。提案中设计到 actor 的设计是把 actor 设计成一种特殊类,让这个类有引用语义,能形成 map,可以 weak 或 unowned 引用。actor 类中包含一些只有 actor 才有的方法,这些方法提供 actor 编程模型所需安全性。但 actor 类不能继承自非 actor 类,因为这样 actor 状态可能会有机会以不安全的方式泄露。actor 和它的函数和属性之间是静态关系,这样可以通过编译方式避免数据竞争,对数据隔离,如果不是安全访问 actor 属性的上下文,编译器可以处理切换到那个上下文中。对于 actor 隔离会借鉴强制执行对内存的独占访问提案的思想,比如局部变量、inout参数、结构体属性编译器可以分析变量的所有访问,有冲突就可以报错,类属性和全局变量要在运行时可以跟踪在进行的访问,有冲突报错。而全局内存还是没法避免数据竞争,这个需要增加一个全局 actor 保护。
按 actor 模型对任务之间通讯重新调整,不用回调代理等手段,将发送消息放到消息邮箱里进行类似 RxSwift 那样 next 的方式一个一个串行传递。说到 RxSwift,那 RxSwift 和 Combine 这样的框架能替代 actor 吗?
对这些响应式框架来说解决线程通信只是其中很小的一部分,其还是会面临闭包、调试和维护复杂的问题,而且还要使用响应式编程范式,显然还是有些重了,除非你已经习惯了响应式编程。
任务都按 actor 模型方式来写,还能够做到功能之间的解耦,如果是服务器应用,actor 可以布到不同的进程甚至是不同机器上。
actor 中消息邮件在同一时间只能处理一个消息,这样等待返回一个值的方式,需要暂停,内部有返回再继续执行,这要怎么实现呢?
答案是使用 Coroutine
在 Swift 并发路线提案里还提到了基于 coroutine 的 async/await 语法,这种语法风格已经被广泛采纳,比如Python、Dart、JavaScript 都有实现,这样能够写出简洁好维护的并发代码。
上述只是提案,最快也需要两个版本的等待,那么语言上的支持还没有来,怎么能提前享用 coroutine 呢?
处理暂停恢复操作,可以使用 context 处理函数 setjmp 和 longjmp,但 setjmp 和 longjmp 较难实现临时切换到不同的执行路径,然后恢复到停止执行的地方,所以服务器用一般都会使用 ucontext 来实现,gnu 的举的例子 GNU C Library: Complete Context Control,这个例子在于创建 context 堆栈,swapcontext 来保存 context,这样可以在其它地方能执行回到原来的地方。创建 context 堆栈代码如下:
uc[1].uc_link = &uc[0];
uc[1].uc_stack.ss_sp = st1;
uc[1].uc_stack.ss_size = sizeof st1;
makecontext (&uc[1], (void (*) (void)) f, 1, 1);上面代码中 uc_link 表示的是主 context。保存 context 的代码如下:
swapcontext (&uc[n], &uc[3 - n]);但是在 Xcode 里一试,出现错误提示如下:
implicit declaration of function 'swapcontext' is invalid in c99原来最新的 POSXI 标准已经没有这个函数了,IEEE Std 1003.1-2001 / Cor 2-2004,应用了项目XBD/TC2/D6/28,标注 getcontext()、makecontext()、setcontext()和swapcontext() 函数过时了。在 POSIX 2004第743页说明了原因,大概意思就是建议使用 pthread 这种系统编程上,后来的 Rust 和 Swift coroutine 的提案里都是使用的系统编程来实现 coroutine,长期看系统编程实现 coroutine 肯定是趋势。那么在 swift 升级之前还有办法在 iOS 用 ucontext 这种轻量级的 coroutine 吗?
其实也是有的,可以考虑临时过渡一下。具体可以看看 ucontext 的汇编实现,重新在自己工程里实现出来就可以了。getcontext、setcontext、makecontext、swapcontext 的在 linux 系统代码里能看到。ucontext_t 结构体里的 uc_stack 会记录 context 使用的栈。getcontext() 是把各个寄存器保存到内存结构体里,setcontext() 是把来自 makecontext() 和 getcontext() 的各寄存器恢复到当前 context 的寄存器里。switchcontext() 合并了 getcontext() 和 setcontext()。
ucontext_t 的结构体设计如下: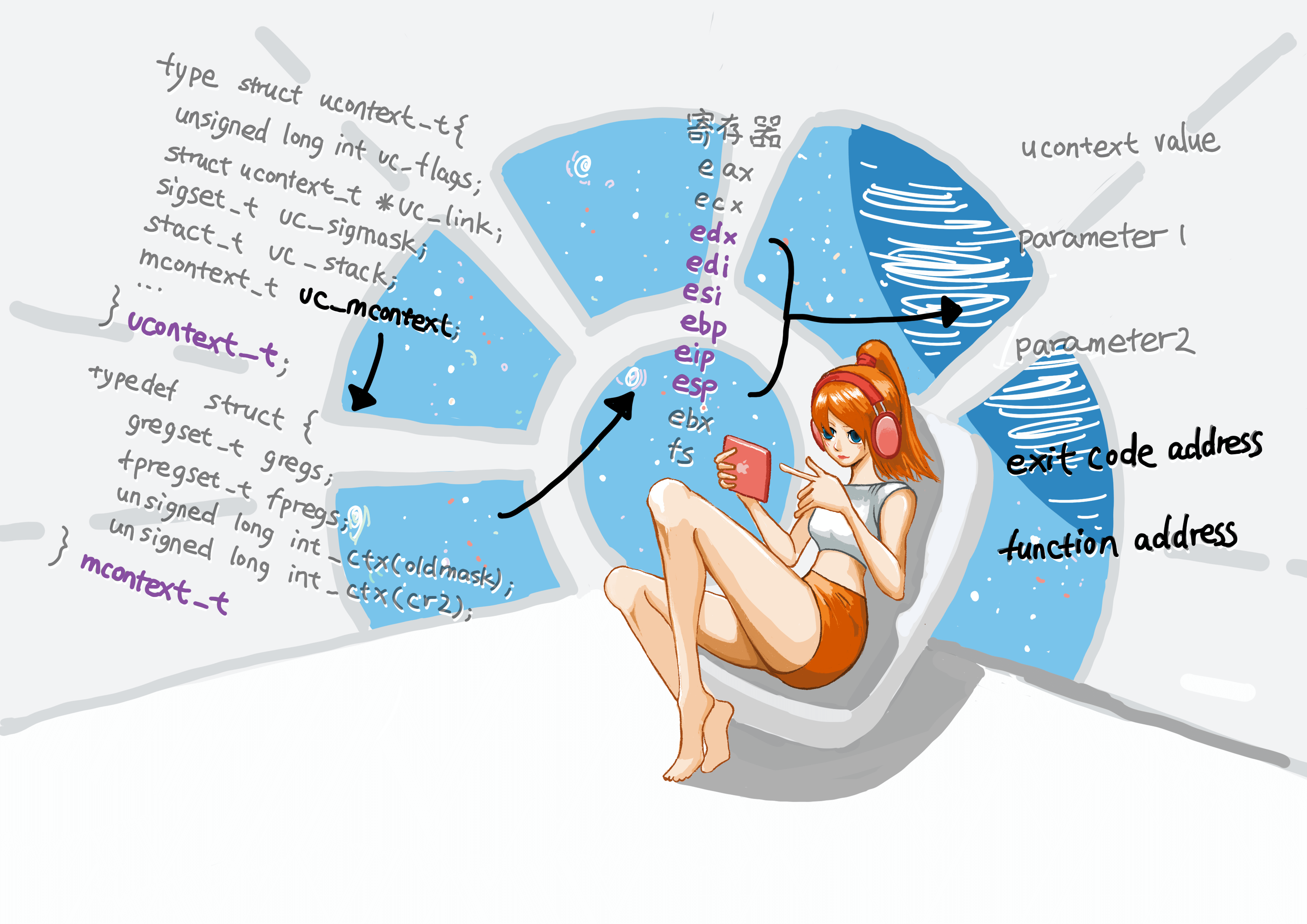
如上图所示,ucontext_t 还包含了一个更高层次的 context 封装 uc_mcontext,uc_mcontext 会保存调用线程的寄存器。上图中 eax 是函数入参地址,寄存器值入栈操作代码如下:
movl $0, oEAX(%eax)
movl %ecx, oECX(%eax)
movl %edx, oEDX(%eax)
movl %edi, oEDI(%eax)
movl %esi, oESI(%eax)
movl %ebp, oEBP(%eax)以上代码中 oECX、oEDX 等表示相应寄存器在内存结构体里的位置。esp 指向返回地址值,由 eip 字段记录,代码如下:
movl (%esp), %ecx
movl %ecx, oEIP(%eax)edx 是 getcontext() 的栈寄存器会记录 ucontext_t.uc_stack.ss_sp 栈顶的值,oSS_SIZE 是栈大小,通过指令addl 可以找到栈底。makecontext() 会根据 ecx 里的参数去设置栈,setcontext() 是 getcontext 的逆操作,设置当前 context,栈顶在 esp 寄存器。
轻量级的 coroutine 实现了,下面咱们可以通过 Swift async/await提案(已加了编号0296,表示核心团队已经认可,上线可期)看下系统编程的 coroutine 是怎么实现的。Swift async/await 提案中的思路是让开发者编写异步操作逻辑,编译器用来转换和生成所需的隐式操作闭包。可以看作是个语法糖,并像其它实现那样会改变完成处理程序被调用的队列。工作原理类似 try,也不需要捕获 self 的转义闭包。挂起会中断原子性,比如一个串行队列中任务要挂起,让其它任务在一个串行队列中交错运行,因此异步函数最好是不阻塞线程。将异步函数当作一般函数调用,这样的调用会暂时离开线程,等待当前线程任务完成再从它离开的地方恢复执行这个函数,并保证是在先前的actor里执行完成。
启动性能分析工具
iOS 官方工具
Instruments 中 Time Profiles 中的 Profile 可以方便的分析模块中每个方法的耗时。Time Profiles 中的 Samples 分析将更加准确的显示出 App 启动后每一个 CPU 核心在一个时间片内所执行的代码。如果在模块开发中有以下的需求,可以考虑使用 Samples 分析:
- 希望更精确的分析某个方法具体执行代码的耗时
- 想知道一个方法到另一个方法的耗时情况(跨方法耗时分析)
MetricKit 2.0 开始加强了诊断特性,通过收集调用栈信息能够方便我们来进行问题的诊断,通过 didReceive 回调 MXMetricPayload 性能数据,可包含 MXSignpostMetric 自定义采集数据,甚至是你捕获不到的崩溃信号的系统强杀崩溃信息传到自己服务器进行分析和报警。
如何在 iOS 真机和模拟器上实现自动化性能分析
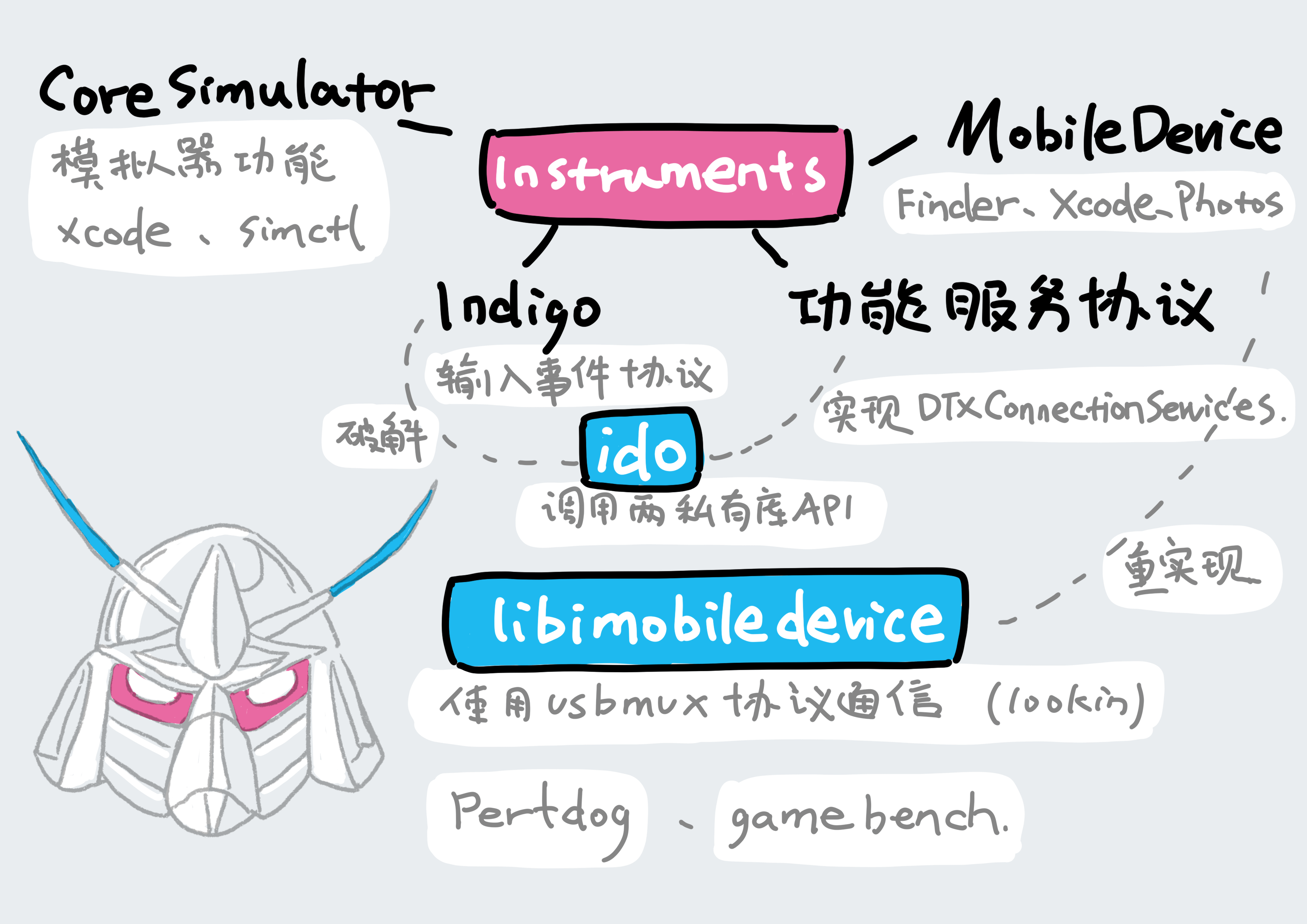
苹果有个 usbmux 协议会给自己 macOS 程序和设备进行通信,场景有备份 iPhone 还有真机调试。macOS 对应的是/System/Library/PrivateFrameworks/MobileDevice.framework/Versions/A/Resources/ 下的 usbmuxd 程序,usbmuxd 是 IPC socket 和 TCP socket 用来进行进程间通信,这里有他的一个开源实现。对于在手机端是 lockdown 来起服务。因此利用 usbmuxd 的协议,就可以自建和设备通信的应用比如 lookin,实现方式可以参考这个 demo。使用 usbmux 协议的 libimobiledevice(相当于 Android 的 adb)提供了更多能力,可以获取设备的信息、搭载 ifuse 访问设备文件系统(没越狱可访问照片媒体、沙盒、日志)、与调试服务器连接远程调试。无侵入的库还有 gamebench 也用到了 libimobiledevice。
instruments 可以导出 .trace 文件,以前只能用 instruments 打开,Xcode12 提供了 xctrace 命令行工具可以导出可分析的数据。Xcode12 之前的时候是能使用 TraceUtility 这个库,TraceUtility 的做法是链上 Xcode 里 instruments 用的那些库,比如 DVTFoundation 和 InstrumentsKit 等,调用对应的方法去获取.trace文件。使用 libimobiledevice 能构造操作 instruments 的应用,将 instruments 的能力自动化。
perfdog就是使用了libimobiledevice调用了instruments的接口(见接口研究,实现代码)来实现instruments的一些功能,并进行了扩展定制,无侵入的构建本地性能监控并集成到自动测试中出数据,减少人工成本。无侵入的另一个好处就是可以方便用同一套标准看到其他APP的表现情况。
要到具体场景去跑 case 还需要流程自动化。Appium 使用的是 Facebook 开发的一套基于 W3C 标准交互协议 WebDriver 的库 WebDriverAgent,python 版可以看这个,不过后来 Facebook 开发了新的一套命令行工具idb(iOS Development Bridge),归档了 WebDriverAgent。idb 可以对 iOS 模拟器和设备跑自动化测试,idb 主要有两个基于 macOS 系统库 CoreSimulator.framework、MobileDevice.framework,包装的 FBSimulatorControl 和 FBDeviceControl 库。FBSimulatorControl 包含了 iOS 模拟器的所有功能,Xcode 和 simctl 都是用的 CoreSimulator,自动化中输入事件是逆向了 iOS 模拟器 Indigo 服务的协议,Indigo 是模拟器通过 mach IPC 通道 mach_msg_send 接受触摸等输入事件的协议。破解后就可以模拟输入事件了。MobileDevice.framework 也是 macOS 的私有库,macOS 上的 Finder、Xcode、Photos 这些会使用 iOS 设备的应用都是用了 MobileDevice,文件读写用的是包装了 AMDServiceConnection 协议的 AFC 文件操作 API,idb 的 instruments 相关功能是在这里实现了 DTXConnectionServices 服务协议。libmobiledevice 可以看作是重新实现了 MobileDevice.framework。pymobiledevice、MobileDevice、C 编写的 SDMMobileDevice,还有Objective-C 编写的 MobileDeviceAccess,这些库也是用的 MobileDevice.framework。
总结如下图所示:
Android Profiler
Android Profiler 是 Android 中常用的耗时分析工具,以各种图表的形式展示函数执行时间,帮助开发者分析耗时问题。
启动优化着实是牵一发动全身的事情,手段既琐碎又复杂。如何能够将监控体系建设起来,并融入到整个研发到上线流程中,是个庞大的工程。下面给你介绍下我们是如何做的吧。
管控流程体系保障平台建设
APM自动化管控和流程体系保障平台,目标是通过稳定环境更自动化的测试,采集到的性能数据能够通过分析检测,发现问题能够更低成本定位分发告警,同时大盘能够展示趋势和详情。平台设计如下图:
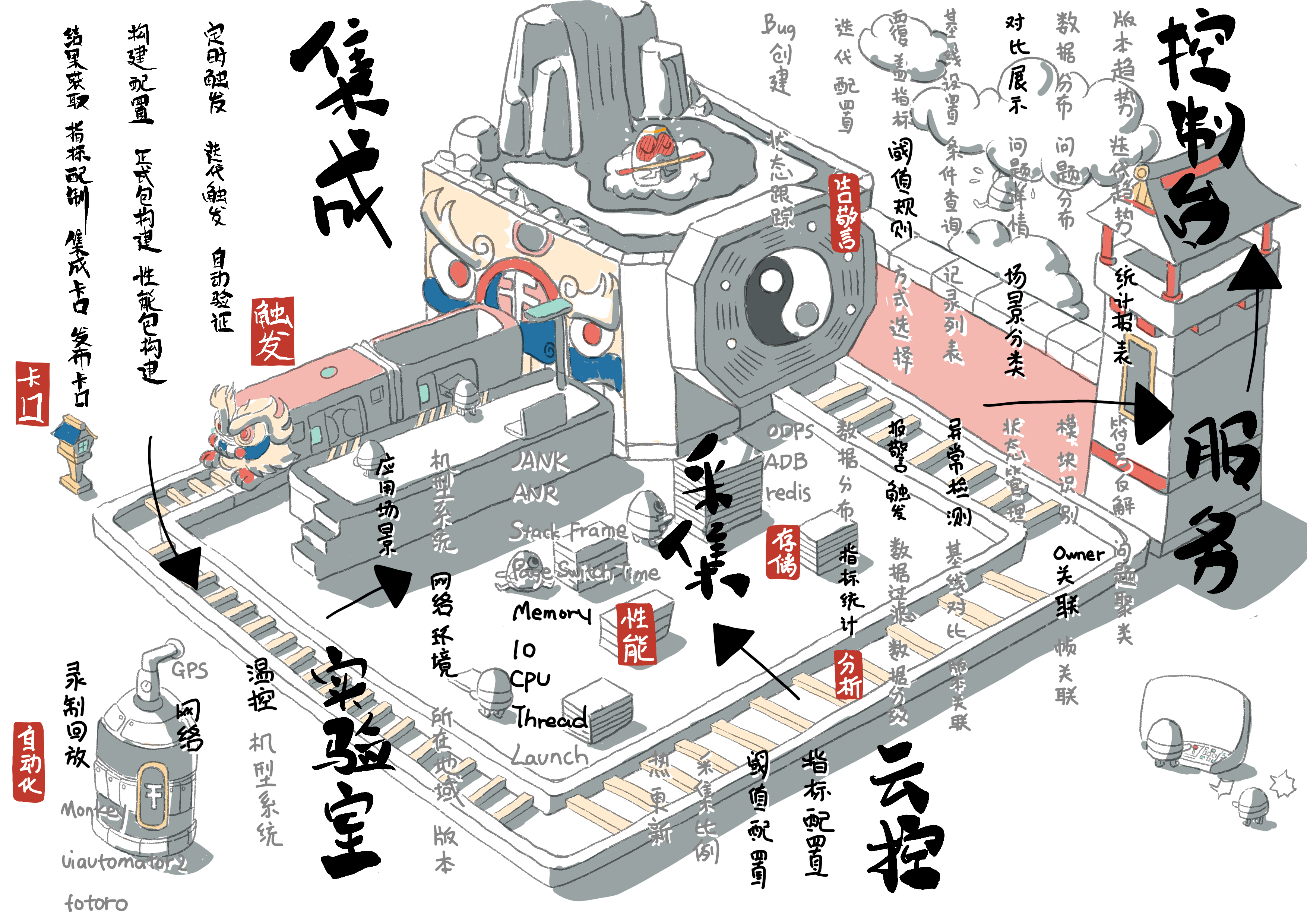
开发过程会 daily 出迭代报告,开发完成后,会有集成卡口,提前卡住迭代性能问题。
集成后,在集成构建平台能够构建正式包和线下性能包,进行线下测试和线上性能数据采集,线下支持录制回放、Monkey 等自动化测试手段,测试期间会有生成版本报告,发布上线前也会有发布卡口,及时处理版本问题。
发布后,通过云控进行指标配置、阈值配置还有采集比例等。性能数据上传服务经异常检测发现问题会触发报警,自动在 Bug 平台创建工单进行跟踪,以便及时修复问题减少用户体验损失。服务还会做统计、分级、基线对比、版本关联以及过滤等数据分析操作,这些分析后的性能数据最终会通过版本、迭代趋势等统计报表方式在大盘上展示,还能展示详情,包括对比展示、问题详情、场景分类、条件查询等。