介绍
最近在做 JavaScript 和 Native 打交道的工作,虽然6年前服务端和前端包括 JavaScript 经验也有些,不过如今前端标准和前端引擎也发展了很多,这里做个记录吧。本文会着重介绍 QuickJS,其中会针对 js 语言的一些特性来看这些特性在 QuickJS 是如何解释执行和优化的,能够加深对 js 语言的理解。QuickJS 是在 MIT 许可下发的一个轻量 js 引擎包含 js 的编译器和解释器,支持最新 TC39 的 ECMA-262 标准。QuickJS 和其它 js 引擎的性能对比,可以参看 QuickJS 的 benchmark 对比结果页,从结果看,JerryScript 内存和体积小于 QuickJS,但各项性能均低于 QuickJS,Hermes 体积和内存大于 QuickJS,性能和 QuickJS 差不多,但 Hermes 对于 TC39 的标准支持并没 QuickJS 全。Frida 在14.0版本引入了 QuickJS,经作者验证内存使用只有 V8的五分之一,于是设为默认引擎。14.3版本将默认引擎切回 V8,主要是因为某些场景 V8表现和调试功能更好,对于调试已经在 Fabrice bellard 的规划里了,未来可期。
在详细介绍和剖析 QuickJS 之前,我先跟你聊聊 JavaScript 的背景和 QuickJS 作者的背景吧。我觉得这样更有助于理解 QuickJS。
先说说 JavaScript。
JavaScript 背景
第一个图文浏览器是1993年的 Mosaic,由 Marc Andreessen 开发。后替代 Mosaic 的是 Netscape 的 Netscape Navigator 浏览器。Brendan Eich 给 Netscape 开发 Java 辅助语言 Mocha(后更名为 JavaScript),耗时10天出原型(包含了eval 函数),集成到 Netscape 2预览版里,Mocha 基于对象而非 Java 那样基于类。Mocha 采用源码解析生成字节码解释执行方式而非直接使用字节码的原因是 Netscape 公司希望 Mocha 代码简单易用,能够直接在网页代码中编写。
直到现在各 js 引擎都还不直接使用字节码,这是由于不同的 js 引擎都有自己的字节码规范,不像 js 代码规范有统一一套,而且字节码会有捆绑版本和验证难的问题。 TC39 有份中间代码的提案,叫做 Binary AST,提案在这 Binary AST Proposal Overview。Binary AST 这份提案还会去设计解决变量的绑定机制对解析性能影响,还有延缓 Early Error 语义到最近的 enclosing 函数或全局执行脚本的时候来提升解析性能,解决区分列表表达式和箭头函数参数列表的区别需要做回溯等可能会存在字符层面歧义,还有单字节和双字节编码检查的问题,字符串和标识符使用 UTF-8,不用转义码。Binary AST 借鉴 WebAssembly 对解析后得到的 AST 使用基本 primitives(字符串、数字、元组)来进行简单二进制编码,再压缩,每个文件都会有个 header 来保证向前和向后的兼容,节点种类通过 header 的索引来引用,避免使用名称可能带来的版本问题,为减少大小会支持 presets。
下面回到90年代,接着说代号是 Mocha 的 JavaScript 发展历程。
Mocha 的动态的对象模型,使用原型链的机制能够更好实现,对象有属性键和对应的值,属性的值可以是多种类型包括函数、对象和基本数据类型等,找不到属性和未初始化的变量都会返回 undefined,对象本身找不到时返回 null,null 本身也是对象,表示没有对象的对象,因此 typeof null 会返回 object。基础类型中字符串还没支持 Unicode,有8位字符编码不可变序列组成,数字类型由 IEEE 754 双精度二进制64位浮点值组成。新的属性也可以动态的创建,使用键值赋值方式。
Brendan Eich 喜欢 Lisp,来 Netscape 本打算是将 lisp 引入浏览器的。因此 Mocha 里有着很多的 lisp 影子,比如函数一等公民和 lambda,函数是一等公民的具体表现就是,函数可以作为函数的参数,函数返回值可以是函数,也可将函数赋值给变量。Brendan Eich 的自己关于当时开发的回顾文章可以看他博客这篇,还有这篇《New JavaScript Engine Module Owner》,访谈稿《Bending over backward to make JavaScript work on 14 platforms》。
Netscape 2 正式版将 Mocha 更名为 JavaScript,后简称 js。1.0 版本 js 语法大量借鉴 C 语言。行末可不加分号,一开始 js 就是支持的。1.1版 js 支持隐式类型转换,可以把任意对象转成数字和字符串。1.0版 js 对象不能继承,1.1 加入对象的 prototype 属性,prototype 的属性和实例的对象共享。为了加到 ISO 标准中,Netscape 找到了 Ecma,因为 ISO 对 Ecma 这个组织是认可的。接着 Ecma 组建了 TC39 技术委员会负责创建和维护 js 的规范。期间,微软为了能够兼容 js,组建了团队开发 JScript,过程比较痛苦,因为 js 的规范当时还没有,微软只能自己摸索,并写了份规范 The JScript Language Specification, version 0.1 提交给 TC39,微软还将 VBScript 引入 IE。96年 Netscape 为 JavaScript 1.1 写了规范 Javascript 1.1 Specification in Winword format 作为 TC39 标准化 js 的基础。97年 TC39 发布了 ECMA-262 第一版规范。
Netscape 3 发布后,Brendan Eich 重构了 js 引擎核心,加了嵌套函数、lambda、正则表达式、伪属性(动态访问修改对象)、对象和数组的字面量、基于标记和清除的 GC。lambda 的函数名为可选,运行时会创建闭包,闭包可递归引用自己作为参数。新 js 引擎叫 SpiderMonkey。js 语言增加新特性,从更多语言那做了借鉴,比如 Python 和 Perl 的数组相关方法,Perl 对于字符串和正则的处理,Java 的 break / continue 标签语句以及 switch。语言升级为 JavaScript 1.2(特性详细介绍),和 SpiderMonkey 一起集成到 Netscape 4.0。ES3 结合了 js 1.2 和 JScript 3.0,I18N 小组为 ES3 加入了可选 Unicode 库支持。开始兼容 ES3的浏览器是运行微软 JScript 5.5的 IE 5.5,运行 js 1.5 的 Netscape 6。
ES3 标准坚持了10年。
这10年对 js 设计的抱怨,也可以说 js 不让人满意的地方,在这个地方 wtfjs - a little code blog about that language we love despite giving us so much to hat 有汇总。当然也有人会站出来为 js 正名,比如 Douglas Crockford,可以看看他的这篇文章 JavaScript:The World’s Most Misunderstood Programming Language,里面提到很多书都很差,比如用法和特性的遗漏等,只认可了 JavaScript: The Definitive Guide 这本书。并且 Douglas Crockford 自己还写了本书 JavaScript: The Good Parts,中文版叫《JavaScript语言精粹》。另外 Douglas Crockford 做出的最大贡献是利用 js 对象和数组字面量形式实现了独立于语言的数据格式 JavaScript Object Notation,并加入 TC39 的标准中,JavaScript Object Notation 也就是我们如今应用最多的数据交换格式 JSON 的全称。
ES4 初期目标是希望能够支持类、模块、库、package、Decimal、线程安全等。2000年微软 Andrew Clinick 主导的.NET Framework 开始支持 JScript。微软希望通过 ES4 标准能够将 JScript 应用到服务端,并和以往标准不兼容。浏览器大战以 Netscape 失败结束后,微软取得了浏览器统治地位,对 TC39 标准失去了兴趣,希望用自家标准取而代之,以至 TC39 之后几年没有任何实质进展。这个期间流行起来的 Flash 使用的脚本语言 ActionScript 也只是基于 ES3 的,2003年 ActionScript 2.0 开始支持 ES4 的提案语法以简化语义,为了提升性能 Flash 花了3年,在2007年开发出 AVM2虚机支持静态类型的 ActionScript 3.0。那时我所在的创业公司使用的就是 flash 开发的图形社交网站 xcity,网站现在已经不在了,只能在 xcity贴吧找到当年用户写的故事截的图。
Brendan Eich 代表 Mozilla 在2004年开始参与 ES4 的规划,2006年 Opera 的 Lars Thomas Hansen 也加入进来。Flash 将 AVM2 给了 Mozilla,命名为 Tamarin。起初微软没怎么参与 ES4 的工作,后来有20多年 Smalltalk 经验的 Allen Wirfs-Brock 加入微软后,发现 TC39正在设计中 ES4 是基于静态类型的 ActionScript 3.0,于是提出动态语言加静态类型不容易成,而且会有很大的兼容问题,还有个因素是担心 Flash 会影响到微软的产品,希望能够夺回标准主动权。Allen Wirfs-Brock 的想法得到在雅虎的 Douglas Crockford 的支持,他们一起提出新的标准提案,提案偏保守,只是对 ES3 做补丁。
AJAX,以及支持 AJAX 和解决浏览器兼容性问题的库 jQuery 库(同期还有 Dojo 和 Prototype 这样 polyfill 的库)带来了 Web2.0时代。polyfill 这类库一般使用命名空间对象和 IIFE 方式解决库之间的命名冲突问题。我就是这个时期开始使用 js 来开发自己的网站 www.starming.com,当时给网站做了很多小的应用比如图片收藏、GTD、博客系统、记单词、RSS订阅,还有一个三国演义小说游戏,记得那会通过犀牛书(也就是 Douglas Crockford 推荐的 JavaScript: The Definitive Guide ,中文版叫《JavaScript 权威指南》)学了 js 后,就弄了个兼容多浏览器的 js 库,然后用这个库做了个可拖拽生成网站的系统。2013年之后 starming 已经做成了一个个人博客,现在基于 hexo 的静态博客网站。2013年之前的 starming 网站内容依然可以通过 https://web.archive.org/ 网站查看到,点击这个地址。
2006年 Google 的 Lars Bak 开始了 V8 引擎的开发,2008 基于 V8 的 Chrome 浏览器发布,性能比 SpiderMonkey 快了10倍。V8 出来后,各大浏览器公司开始专门组建团队投入 js 引擎的性能角逐中。当时 js 引擎有苹果公司的 SquirrelFish Extreme、微软 IE9 的 Chakra 和 Mozilla 的 TraceMonkey(解释器用的是 SpiderMonkey)。
随着 IBM、苹果和 Google 开始介入标准委员会,更多的声音带来了更真实的诉求,TC39 确定出 ES4 要和 ES3 兼容,同时加入大应用所需的语言特性,比如类、接口、命名空间、package,还有可选静态类型检查等等。部分特性被建议往后延,比如尾调用、迭代器生成器、类型自省等。现在看起来 ES4 10年设计非常波折,激进的加入静态类型,不兼容老标准,把标准当研究而忽略了标准实际上是需要形成共识的,而不是要有风险的。在 TC39 成员达成共识后,ES4 还剔除了 package 和命名空间等特性,由于 Decimal 的设计还不成熟也没能加入。由于 ES4 很多特性无法通过,而没法通过标准,因此同步设计了10年多的 ES 3.1 最终改名为 ES5,也就是 ECMA-262 第 5 版。ES5 主要特性包括严格模式,对象元操作,比如setter、getter、create等,另外添加了些实用的内置函数,比如 JSON 相关解析和字符串互转函数,数组增加了高阶函数等等。ES5 的测试套件有微软 Pratap Lakshman 的,这里可以下载看到,谷歌有 Sputnik,有5000多个测试,基于他们,TC39 最后统一维护著名的 Test262 测试套件。
ES5 之后 TC39 开始了 Harmony 项目,Harmony 开始的提案包括类、const、lambda、词法作用域、类型等。从 Brenda Eich 的 《Harmony Of My Dreams》这篇文章可以 js 之父对于 Harmony 的期望,例如文章中提到的 # 语法,用来隐藏 return 和 this 词法作用域绑定,最终被 ES2015 的箭头函数替代,但 # 用来表示不可变数据结构没有被支持,模块和迭代器均获得了支持。Harmony 设计了 Promise 的基础 Realm 规范抽象、内部方法规范 MOP、Proxy 对象、WeakMap、箭头函数、完整的 Unicode 支持、属性 Symbol 值、尾调用、类型数组等特性。对于类的设计,TC39 将使用 lambda 函数、类似 Scheme 的词法捕获技术、构造函数、原型继承对象、实例对象、扩展对象字面量语法来满足类所需要的多次实例化特性。模块的设计思路是通过 module 和 import 两种方式导入模块,import 可以用模块声明和字符串字面量的方式导入模块。模块导入背后是模块加载器的设计,设计的加载流程是,先处理加载标识的规范,再处理预处理,处理模块间的依赖,关联上导入和导出,最后再进行依赖模块的初始化工作。整个加载过程可以看这个 js 实现的原型,后来这个加载器没有被加入规范,而由浏览器去实现。CommonJS 作者 Kevin Dangoor 的文章《CommonJS: the First Year》写下做 CommonJS 的初衷和目标,标志着 js 开始在服务端领域活跃起来。CommonJS 的思路就是将函数当作模块,和其他模块交互是通过导出局部变量作为属性提供值,但是属性能被动态改变和生成,所以对于模块使用者,这是不稳定的。Ryan Dahl 2009 开发的 Node.js (介绍参看作者jsconf演讲)就是用 CommonJS 的模块加载器。Node.js 链接了 POSIX API,网络和文件操作,有个自己的 Event Loop,有些基础的 C 模块,还包含了 V8 引擎。
2010 年开始出现其他语言源码转 js 源码这种转译器的风潮,最有代表的是 CoffeeScript,CoffeeScript 某种程度上是对 js 开发提供了更优雅更先进的开发语言辅助。从 CoffeeScript 一些特性在开发者的反馈,能够更好的帮助 TC39 对 js 特性是否进入标准提供参考。后来还有以优化性能为目的的 Emscripten 和 asm.js 翻译成高效 js 代码的转译器。转义器对于 Harmony 甚至是后面的 ES2015 来说有着更重要的意义。当时的用户没有主动进行软件升级的习惯,特别是由系统绑定的浏览器。适配 IE6的痛苦,相信老一辈的前端开发者会有很深的体会。大量浏览器低版本的存在对于新的标准推广造成了很大的阻碍,因此使用新标准编写代码转移成可兼容低版本浏览器的代码能够解决兼容问题。在 Harmony 项目开发过程中除了 Mozilla 使用 SpiderMonkey 引擎开发的 Narcissus 转译器外,还有直到目前还在使用的 Babel 和 TypeScript 语言的转译器。另外还有使用 rust 写的 js 编译器 swc,主打速度,打算来替代 babel。
2015年,ECMAScript 2015发布。ECMAScript 2015 之后,由于各个浏览器都开始更快的迭代更新, TC39 开始配合更新的节奏,开始每年更新标准,以年作为标准的版本号。
ES2016 增加了 async/await 异步语法特性,纵观 js 的异步历程,从最开始的 Callback方式到 Promise/then,js 解决了回调地狱的问题,但缺少能够暂停函数和恢复执行的方法,因此在 ES2015 加入了生成器,其实现核心思想就是协程,协程可以看作是运行中线程上的可暂停和恢复执行的任务,这些任务都是可通过程序控制的。在 ES2016 加入简洁的 async/await 语法来更好的使用协程。js 异步编程历程如下图: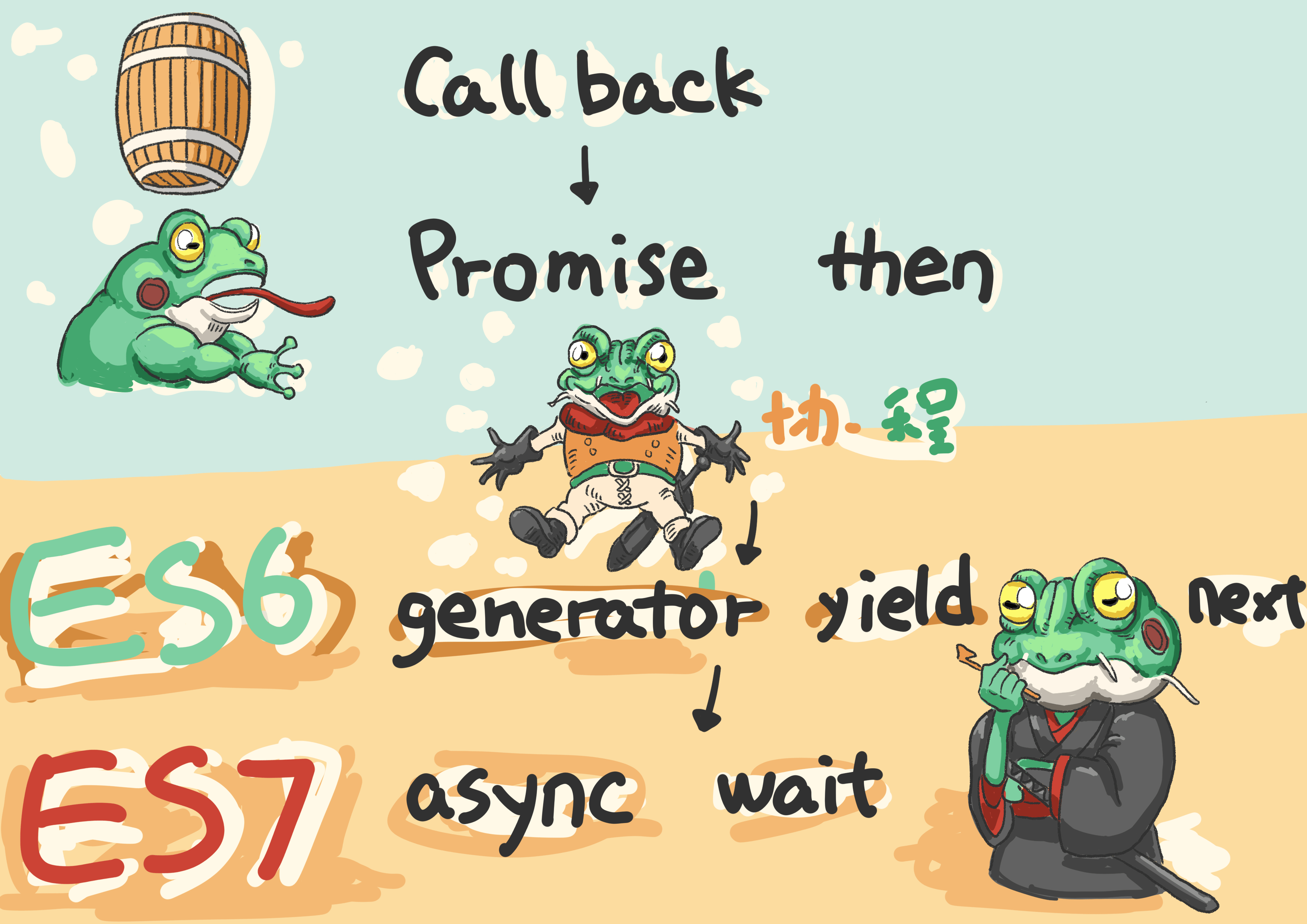
ECMAScript 2016 开始 js 进入了框架百家争鸣的时代。
js 框架方面,早期 js 的框架是以兼容和接口优雅为基准比较胜出的 PrototypeJS 和 jQuery。MVC 流行起来的框架是 Backbone,MVVM 时代是 AngularJS 为代表的数据双向绑定只用关注 Model 框架新星崛起。Vue 在 MVVM 基础上增加了用来替代 Options API 的 Composition API 比拟 React 的 Hooks。React(React 的创作者是 Jord Walke,在 facebook,不过现在已经离开了 facebook,创立了自己的公司)后来居上,以函数式编程概念拿下头牌,这也是因为 React 核心团队成员喜欢 OCaml 这样的函数式编程语言的原因。。React 的组件有阿里的 Ant Design 和 Fusion Design 可用。React 对于逻辑复用使用的是更优雅的 Hooks,接口少,以声明式方式供使用,很多开发者会将自己开发的逻辑抽出来做成 hooks,出现了很多基于 hooks 状态管理公用代码。对于状态的缓存维护由 React 的内核来维护,这能够解决一个组件树渲染没完成又开始另一个组件树并发渲染状态值管理问题,开发者能够专注写函数组件,和传统 class 组件的区别可以看 Dan Abramov 的这篇文章《How Are Function Components Different from Classes?》。js 框架的演进如下图: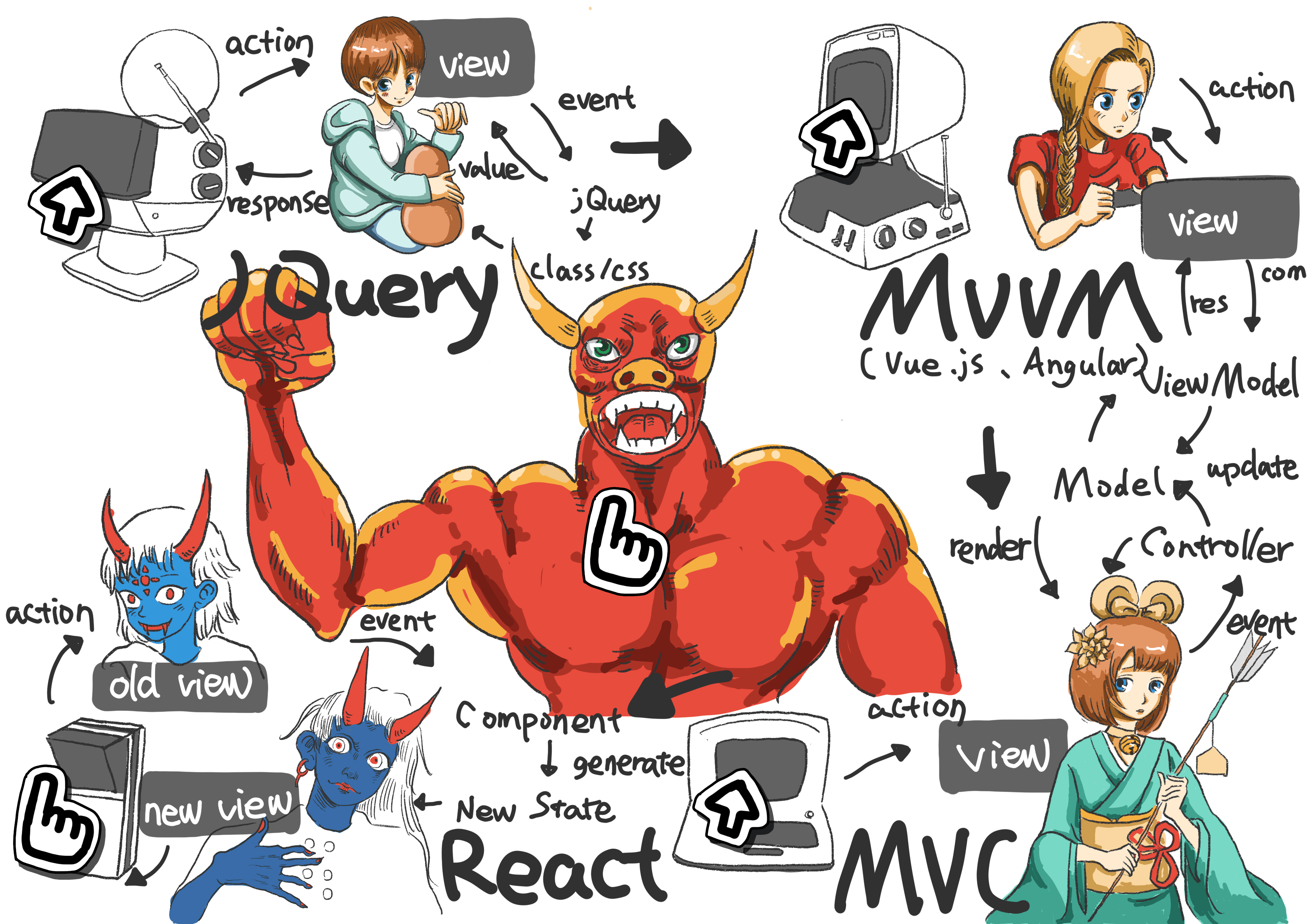
为了使 js 能够应用于更大的工程化中,出现了静态类型 js 框架。静态类型的 js 框架有微软的 TypeScript 和 Facebook 的 Flow。TypeScript 的作者是当年我大学时做项目使用的 IDE Delphi 的作者 Anders Hejlsberg,当时的 Delphi 开发体验非常棒,我用它做过不少项目,改善了大学生活品质。
对于 React 的开发,现需要了解脚手架 create-react-app,一行命令能够在 macOS 和 Windows 上不用配置直接创建 React 应用。然后是使用 JSX 模版语法创建组件,组件是独立可重用的代码,组件一般只需要处理单一事情,数据通过参数和上下文共享,上下文共享数据适用场景类似于 UI 主题所需的数据共享。为了确保属性可用,可以使用 defaultProps 来定义默认值,使用 propTypes 在测试时进行属性类型设置和检查。在组件里使用状态用的是 Hooks,最常见的 Hooks 是 setState 和 useEffect,项目复杂后,需要维护的状态就会很复杂,React 本身有个简单使用的状态管理库 React Query 数据请求的库,作用类似 Redux,但没有模版代码,更轻量和易用,还可用 Hooks。React Router 是声明式路由,通过 URL 可以渲染出不同的组件。react 跑在 QuickJS 上的方法可以参看 QuickJS 邮件列表里这封邮件。
React 框架对应移动端开发的是 React Native。
React Native 使用了类似客户端和服务器之间通讯的模式,通过 JSON 格式进行桥接数据传递。React Native 中有大量 js 不适合编写的功能和业务逻辑,比如线程性能相应方面要求高的媒体、IO、渲染、动画、大量计算等,还有系统平台相关功能特性的功能业务代码。
这样的代码以前都是使用的原生代码和 C++ 代码编写,C++ 代码通过静态编译方式集成到工程中,也能实现部分平台通用,但是 C++ 编写代码在并发情况下非常容易产生难查的内存安全和并发问题,对于一些比较大的工程,开启 Monkey 测试由于插桩导致内存会增大好几倍,从而无法正常启动,查问题更加困难。当然 Rust 也许是另一种选择,rust 语言层面对 FFI 有支持,使用 extern 就可以实现 rust 与其他编程语言的交互。rust 对内存安全和并发的问题都能够在编译时发现,而不用担心会在运行时发现,这样开发体验和效率都会提高很多,特别是在重构时不会担心引入未知内存和并发问题。使用 rust 编译 iOS 架构的产物也很简单,先安装 Rustup,然后在 rustup 里添加 iOS 相关架构,rust 的包管理工具是 cargo,类似于 cocoapods,cargo 的子命令 cargo-lipo 可以生成 iOS 库,创建一个 C 的桥接文件,再集成到工程中。对于 Android 平台,rust 有专门的 android-ndk-rs 库。rust 的 ffi 在多语言处理中需要一个中间的通信层处理数据,性能和安全性都不高,可以使用 flatbuffers 。关于序列化方案性能比较可以参看 JSON vs Protocol Buffers vs FlatBuffers 这篇文章。
React Native 本身也在往前走。以前 React Native 有三个线程,分别是执行 js 代码的 JS Thread,负责原生渲染和调用原生能力的 UI Thread,模拟虚拟 DOM 将 Flexbox 布局转原生布局的 Shadow Thread。三个线程工作方式是 JS Thread 会先对 React 代码进行序列化,通过 Bridge 发给 Shadow Thread,Shadow Thread 会进行反序列化,形成虚拟 DOM 交由 Yogo 转成原生布局,Shadow Thread 再通过 Bridge 传给 UI Thread,UI Thread 获取消息先反序列化,再按布局信息进行绘制,可以看出三个线程交互复杂,而且消息队列都是异步,使得事件难保处理,序列化都是用的 JSON 性能和 Protocol Buffers 还有 FlatBuffers 相比差很多。新架构会从线程模型做改进,高优先级线程会直接同步调用 js,低优先级更新 UI 的任务不在主线程工作。同时新架构的核心 JSI 方案简化 js 和原生调用,改造成更轻量更高效的调用方式,用来替换 Bridge。JSI 使得以前的三个线程通信不用都通过 Bridge 这种依赖消息序列化异步通信方式,而是直接同步通信,消除异步通信会出现的拥塞问题,具体使用例子可以看这篇文章《React Native JSI Challenge》。另外 React Native 新架构的 JSI 是一个轻量的 C++桥接框架,通信对接的 js 引擎比如 JSC、Hermes、V8、QuickJS、JerryScript 可以很方便的替换。关于 JSI 的详情和进展可以参考其提案地址。
2019 年出现的 Svelte。Svelte 的特点是构建出的代码小,使用时可以直接使用构建出带有少量仅会用到逻辑的运行时的组件,不需要专门的框架代码作为运行时使用,不会浪费。Svelte 没有 diff 和 patch 操作,也能够减少代码,减少内存占用,性能会有提升。当然 Svelte 的优点在项目大了后可能不会像小项目那么明显。
CSS 框架有 Bootstrap、Bulma、Tailwind CSS,其中认可度最高的是 Tailwind CSS,近年来 Bootstrap 持续降低,Tailwind CSS 和 Bootstrap 最大的不同就是 Tailwind CSS 没有必要的内置组件,因此非常轻量,还提供了 utility class 集合和等价于 Less、Sass 样式声明的 DSL。浏览器对 CSS 样式和 DOM 结合进行渲染的原理可以参看我以前《深入剖析 WebKit》这篇文章。
在浏览器之外领域最成功的框架要数 Node.js 了。
Ryan Dahl 基于 V8 开发了 Node.js,提供标准库让 js 能够建立 HTTP 服务端应用。比如下面的 js 代码:
const http = require('http');
const hostname = '127.0.0.1';
const port = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('hi');
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});上面代码运行后会起了个服务应用,访问后会输出 hi。Node.js 会涉及到一些系统级的开发,比如 I/O、网络、内存等。
Node.js 作者 Ryan Dahl 后来弄了 Deno,针对 Node.js 做了改进。基于 Node.js 开发应用服务的框架还有 Next.js,Next.js 是一个 React 框架,包括了各种服务应用的功能,比如 SSR、路由和打包构建,Netflix 也在用 Next.js。最近前端流行全栈无服务器 Web 应用框架,包含 React、GraphQL、Prisma、Babel、Webpack 的 Redwood 框架表现特别突出,能够给开发的人提供开发 Web 应用程序的完整体验。
Node.js 后的热点就是开发工具,工程构建,最近就是 FaaS 开发。工程开发工具有依赖包管理的 npm 和 yarn,webpack、Snowpack、Vite、esbuild 和 rollup 用来打包。其中 esbuild 的构建速度最快。
测试框架有 Karma、Mocha、Jest,React 测试库 Enzyme。其中 Jest 非常简单易用,可进行快照测试,可用于 React、Typescript 和 Babel 里,Jest 目前无疑是测试框架中最火的。另外还有个 Testing Library 可用来进行 DOM 元素级别测试框架,接口易用,值得关注。
最近比较热门的是低代码,低代码做的比较好的有 iMove 等,他们通过拖拽可视化操作方式编辑业务事件逻辑。这里有份低代码的 awesome,收录了各厂和一些开源的低代码资源。
2020 年 Stack Overflow 开发者调查显示超过半数的开发者会使用 js,这得益于多年来不断更新累积的实用框架和库,还有生态社区的繁荣,还有由各大知名公司大量语言大师专门为 js 组成的技术委员会 TC39,不断打磨 js。
js 背景说完了,接下来咱们来聊聊 QuickJS 的作者吧。
作者
QuickJS 作者 Fabrice Bellard 是一个传奇人物,速度最快的TCC,还有功能强大,使用最广的视频处理库 FFmpeg 和 Android 模拟器 QEMU 都是出自他手。
一个人在一个项目或者一个方向上取得很大成果就很厉害了,但是 Fabrice Bellard 却在C语言、数据压缩、数值方法、信号处理、媒体格式、解析器方面弄了很多的实用明星项目,涉及编译、虚拟机、操作系统、图形学、数学等领域。还能后续维护和管足文档,比如 QuickJS 就会配套的对新 ECMAScript 特性、运行时新 API进行支持更新。各项都在性能、可移植核灵活性上做到极致,非常牛了。我觉得 Fabrice Bellard 和 John D. Carmack II 一样,属于一人可抵一个军团的天才,关于 John D. Carmack II 的介绍可以参看《DOOM启世录》这本书。下面是他项目的介绍:
- 1989:LZEXE 高中时候写的 DOS 上很有名的可执行压缩程序。那时 Fabrice Bellar 使用 Amstrad PC1512 编程,由于 Amstrad PC1512磁盘空间非常有限,于是他使用8086汇编重写了 LZSS 压缩算法,并优化了代码结构,新的压缩程序就是 LZEXE,LZEXE 解压速度非常快,充分显示了他超高的编程天赋。
- 1996:Harissa Java 虚拟机。
- 1997: Pi 计算世界纪录保持者。Fabrice Bellard 的计算圆周率的公式 Bellard 公式,是 BBP 公式的变体,计算中使用优化的查德诺夫斯基方程算法计算,复杂度从O(n3)降到了O(n2)。用 BBP 公式来验证结果。Bellard 公式比 Bailey-Borwein-Plouffe 公式快43%,在圆周率竞赛中取胜成为最快的计算圆周率算法,创造了Pi 计算世界纪录,直到2010年8月被余智恒和近藤茂打破,他们完成了五万亿位的 Pi 计算,使用的是可以充分利用超过4核多线程达到12核24超线程的分布式大型服务器级机器计算的 y-cruncher 来完成的计算。不过 Fabrice Bellard 使用的机器配置要低很多,使用了116天提案算出了2700亿位。
- 1999:Linmodem
- 2000:FFmpeg 主要是做音视频编解码和转换,在苹果没有开放硬件解码接口时候,在 iOS 上各种视频 App 都会用 FFmpeg 来解码视频,OpenGL ES 渲染。常见的视频特效、贴纸都用到了 FFmpeg。如今苹果开放了 Metal 硬件解码接口,AVFoundation 可以直接使用硬件解码,这样就可以不用 FFmpeg 了,不过 FFmpeg 现在依然应用在各专业领域,比如滤镜,性能效率依然强劲。FFmpeg 就像一篇博士论文,并且比其他论文要好很多。FFmpeg 可以作为库在应用中使用,也可以直接使用里面的工具。FFmpeg 由音视频编解码库 libavcodec 模块和负责流到输出互转过程的 Libavformat 模块组成,两模块提供解析和不同格式转换的能力,并且灵活易扩展,很多媒体工具和播放器都集成了他们。音视频数据不同格式有不同算法,编码就是写数据,解码就是读数据,编码解码由 libavcodec 模块负责。一个媒体数据会有多个流,比如视频流和音频流,多个流混合单输出叫 multiplexing,demultiplexing 是将单输出返回成多个流。multiplexing 和 demultiplexing 依靠的就是 Libavformat 模块。
- 2000:计算当时已知最大素数26972593-1
- 2001:TinyCC(Tiny C Compiler) 是、是GNU/Linux环境下最小的 ANSI C 语言编译器,目前编译速度是最快的。
- 2002:TinyGL 来自他在1998年 VReng 虚拟现实引擎分布式3D 应用,是一个非常快速、紧凑的OpenGL子集。TinyGL 比 Mesa(后被 VMWare 收购) 还要快要小,占用更少的资源。
- 2002:QEmacs,Bellard 为他的 QEmacs 写了个包括 HTML/XML/CSS2/DocBook 渲染引擎,如果配合 QuickJS 组装成一个浏览器一点问题也没有。Emacs 处理大文件很拿手,一个文件也能多开独立窗口,我觉得 QuickJS 5万行的核心代码是 Bellard 在自己的 QEmacs 里写的,因为 QEmacs 有个显著的特性是使用高度优化的内部表示法和对文件进行 mmaping,这样带来的好处是上百兆的文件编辑起来也不会慢。
- 2003:QEMU 在一台物理机器上管理数百个不同计算环境。QEMU 中 Fabrice Bellard 声明了两百多个版权声明,占了近1/3。QEMU 不是一次翻译一条指令,会将多个指令翻译后一次记到 chunk 里,如果这多个指令会执行多次,那么这个翻译过程就会被省掉,从而提高执行速度。VirtualBox、Linux Kernel-based 虚拟机(KVM)、Android 模拟器都是基于 QEMU。
- 2004:TinyCC Boot Loader 可在15秒内从代码编译到启动 Linux 系统。
- 2005:DVB-T computer-hosted transmitter 用普通 PC 外加 VGA 卡,产生VHF信号,充当模拟数字电视系统。
- 2011:JSLinux 用 Javascript 开发的 PC 模拟器,可以在浏览器里运行 Linux。
- 2012:LTEENB 是 PC 软件实现4G LTE/5G NR基站。能跑在一个普通4核 CPU 的 PC 上。据说是 Fabrice Bellard 一个人10个月做出来的,有人调侃说10个月自己可能协议都读不完。目前 LTEENB 用在他创办的 Amarisoft 公司里。
- 2014:BPG 基于HEVC的新图像格式,使用 JavaScript 解码器。相比较JPEG,BPG 有着更高的压缩算法,相同质量体积少半。
- 2017:TinyEMU 被开发出来,TinyEMU可以模拟128位精简指令集 RISC-V(基于 RISC 开源指令集架构) 和 x86 CPU 指令集的小型模拟器,另外 TinyEMU 还有 js 版,可以运行 Linux 和 Windows 2000。
- 2019:QuickJS 本篇主角 JavaScript 引擎。
更详细的介绍可以看 Fabrice Bellard 的无样式个人网站 以及网站上列出他的各个项目代码。
Decimal
QuickJS 在2020-01-05版本加入–bignum flag 用来开启 Decimal 科学计算,依靠他以前写的 LibBF 来处理 BigInt、BigFloat 和 BigDecimal 数字。LibBF可以处理任意精度浮点数的库,使用渐进最优算法,基本算术运算接近线性运行时间。使用的 IEEE 754语义,操作都是按 IEEE 754标准来进行四舍五入。基本加减乘除和平方根算术运算都具有接近线性的运行时间,乘法使用 SIMD 优化的 Number Theoretic Transform 来运算,SIMD(Single instruction, multiple data)是单指令多数据的意思,表示某时刻一个指令能够并行计算,适合任务包括调音量和调图形对比度等多媒体操作。能够支持sin、cos、tan这样的函数。
TC39这些年来一直在考虑加入高精度的小数类型 Decimal。
这些都是什么数字呢?
Int 的最大值是2的31次方减1,十进制就是2147483647,共31位,如果需要更大位数就需要用于科学计算的 Decimal。Decimal128是128位的高精度精确小数类型。
为什么要使用 Decimal 这种类型呢?
decimal 分数通常不能用二进制浮点精确表示,当建立十进制字符串表示量相互作用模型时,二进制浮点精度效果较差,所以涉及财务计算都不用二进制浮点数字,还有些小数不能用二进制表示,尾数部分会一直循环,所以会截断,这样精度就会有影响,比如0.1 + 0.2 == 0.3就是 false,0.2 + 0.2 == 0.4就是 true。出现这个情况的原因是二进制唯一的质因数是2,因此以2作为质因数表示分母的分数没有问题,而以5或10作为分母的分数是重复的小数,0.1的是分母为10的分数1/10,0.2是分母为5的分数1/5,这些重复小数进行运算然后转换为十进制时就会出现问题。这里有个网站0.30000000000000004.com专门收集了各种语言 0.1 + 0.2 的结果,也包含了 C、C++、Kotlin、Objective-C、Swift 和 JavaScript,同时也列出了如何使用语言支持方法来得到 0.3 的准确结果,比如 swift 已经有了 Decimal 函数,通过 Decimal(0.1) + Decimal(0.2) 就能够得到 0.3。The Floating-Point Guide - What Every Programmer Should Know About Floating-Point Arithmetic这个网站包含了 Decimal 方方面面,还有各种语言的处理范例。
Decimal 函数的实现在 swift 源码 stdlib/public/Darwin/Foundation/Decimal.swift 路径下,Java BigDecimal的实现在这里,js 也有个人使用 js 实现的更高精度的浮点运算库,比如 Michael M 的 GitHub 上就有 bignumber.js、decimal.js 和 big.js。QuickJS 采用的方式就是使用数字加m字面量,表现起来就是 0.1m + 0.2m,结果是0.3m。浮点运算中使用很多的数字进行相加,会产生渐进的累加误差,特别是在财务计算这种对精度要求高的应用上,这些误差就会成为大事故。先前做包大小优化时,模块很多,发现四舍五入位数少取一位时偏差还蛮大。因此提高浮点表示的精度,就可以减少中间计算造成的累积舍入误差。
当需要更高精度时,浮点运算可以用可变长度的比如指数来实现,大小根据需要来,这就是任意精度浮点运算。更高精度就需要浮点硬件,叫浮点扩展,比如 double-double arithmetric,用在 C 的 long double 类型。就算精度再高吧,有些有理数比如1/3,也没法全用二进制浮点数表示,如果要精确表现这些有理数,需要有理算术软件包,软件包对每个整数使用 bignumber 运算。在计算机的代数系统(比如Maple)里,可以评估无理数比如 π 直接处理底层数学,而不需要给每个中间计算使用近似值。
再看看对应的标准和各编程语言的实现情况。
那什么是IEEE 754-2008标准?为什么要有这个标准?
以前很早的时候大概在七八十年代,计算机制造商的浮点标准比如字大小、表示方法还有四舍五入等都不一样,不同系统浮点的兼容就是个很大的问题,因此当时英特尔和摩托罗拉都提出了浮点标准的诉求。
85年IEEE 754-2008 decimal 浮点标准出来,IBM大型机进行了支持。标准在计算机硬件和编程语言中应用非常广,其基本格式有单精度,双精度和扩展精度,单精度在 C 里是 float 类型,7位小数。双精度在 C 里是 double 类型,占8个字节,64位双精度的范围是2 × 10的负308次方到2 × 10的308次方。扩展精度在 C99和 C11 标准的附件IEC 60559 浮点运算里定义了 long double 类型。四精度,34位小数。decimal32、decimal64和 decimal128都是用于执行十进制进位。
IEEE 754-2008标准还定义了32位、64位和128位 decimal 浮点表示法。规定了一些特殊值的表示方法,比如正无穷大 +∞ ,负无穷大 -∞,不是一个数字表示为 NaNs 等。定义了浮点单元(FPU),也可以叫数学协处理器,专门用来执行浮点运算。
IBM在1998年在大型机里引入了 IEEE 兼容的二进制浮点运算,05年加了 IEEE 兼容的decimal 浮点类型。
除了IEEE 754-2008标准外,还有其他浮点格式标准吗?
现在对机器学习模型训练而言,范围比精度更有用,因此有了 Bfloat16标准,Bfloat16标准和 IEEE 754半精度格式的内存量一样,而指数要更多,IEEE 754是5位,Bfloat16是8位。很多机器学习硬件加速器都提供了支持Bfloat16支持,Nvidia 甚至还支持了 TensorFloat-32 格式标准,指数位数更多,达到10位。
如今 TC39正在努力将 Decimal 加到标准中,BigInt 提案已接受。TC39提案用 BigDecimal/Decimal128 语法是类似 1.23m 这样。Swift 已经有了支持,对应的是 Decimal。python也有,文档。数据库MongoDB的说明。C 和 C++语言对于32、64和128位 IEEE 754 decimal 类型还是一个提案,只是GCC编译器实现了一个,Clang不支持decimal floating point types,所以 QuickJS 专门实现了 BigInt 和 BigDecimal 的处理。BigInt 可以使 JavaScript 有任意大小的整数。QuickJS BigInt 性能上这里有个 js 程序 pi_bigint.js 算10万位的 pi,相同机器上 V8 是2.3s,QuickJS 是0.26s。BigDecimal 相对于 BigInt 多了小数位,用做高精度小数计算。BigDecimal 使用十进制而不是二进制 BigInt 表示非小数部分,然后用 scale 来表示小数位置。这样的表示就不会有精度问题,使用 BigDecimal 计算是在 BigInt 之间进行运算,scale进行小数点位置更新。Fabrice Bellard用BigDecimal写了这段代码来计算pi的位数,代码在这里。
QuickJS
QuickJS 只有210KB,体积小,启动快,解释执行速度快,支持最新 ECMAScript 标准(ECMA-262)。
ECMAScript 标准最大的变化是发生在 ES2015。类、箭头函数、静态类型数组、let关键字、maps、sets、promise等特性都是在 ES2015(ES6)增加的,ECMAScript 2016 主要增加了 await/async 关键字,ECMAScript 2017 主要增加了 rest/spread 运算符,ECMAScript 2020 主要增加了 BigInt。CMAScript 标准通读比较枯燥,最好在碰到坑时查阅。最新的 ECMAScript 标准在这里 ecma-262。QuickJS包含了 ecma-262 标准测试套件 Test262,将 test262 测试套件安装到 QuickJS test262 目录下,QuickJS 运行测试套件的程序源文件是 run-test262.c,test262.conf 包含各种测试的选项,test262_error.txt 是记录当前显示错误信息的列表。到今年 Test262里面有已包含了三万多个单独测试 ECMAScript 规范的测试,而 QuickJS 几乎全部通过了测试,和 V8差不多,比 JavaScriptCore 强。Test262 是 ECMAScript 测试套件,在 Test262 Report 网站上可以看到各个 js 引擎对 ECMAScript 标准支持情况,最新情况如下: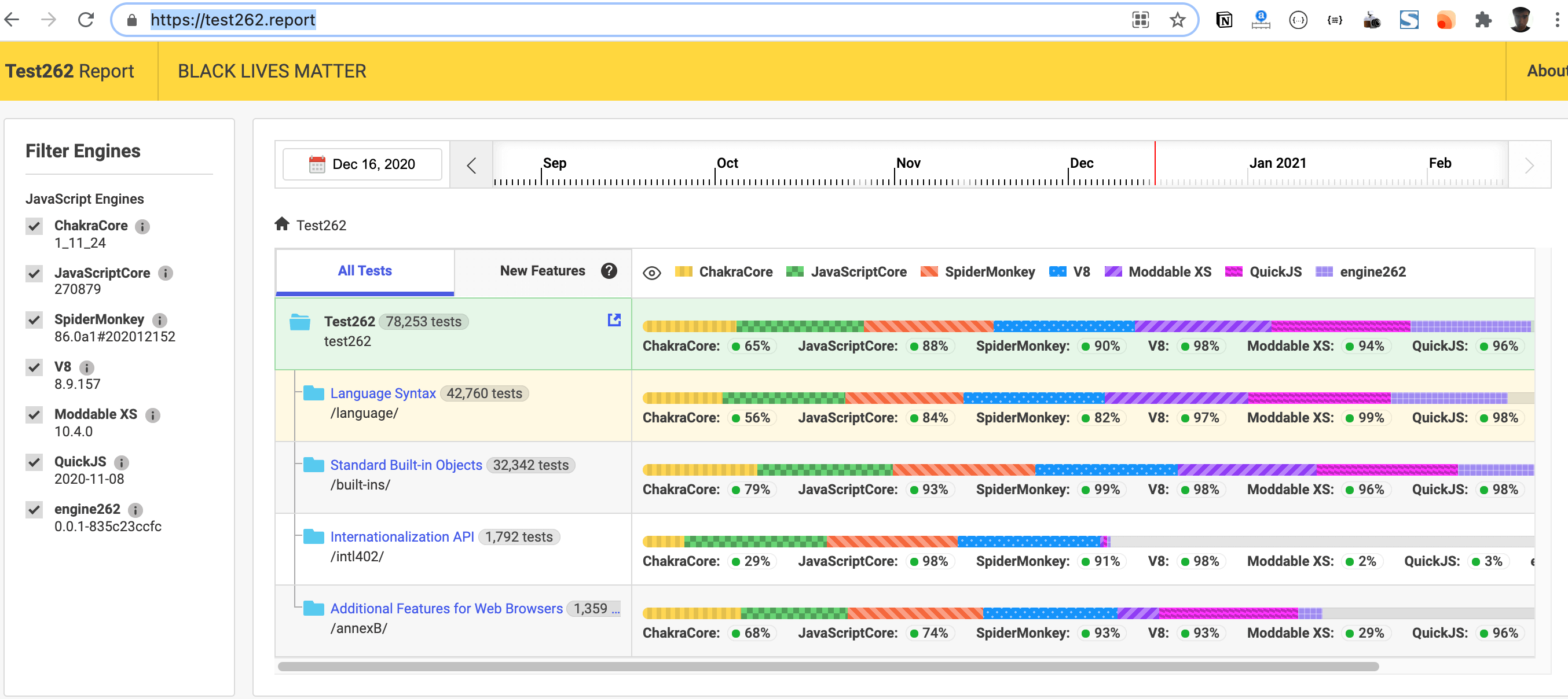
如上图所示,在语法、内置对象上 QuickJS 和 V8 都不相上下,附加特性上做的最好。
QuickJS 发布以来功能的更新都会发布在 QuickJS 的 changelog 里 上,20年重要的更新就是 TC39 BigDecimal 提案的支持还有更新了下 TC39的 Operator overloading 提案,更新的commit在这里,并修改了运算符重载语义使之更接近于TC39的提案。os和std模块做了更新和新增,包括 os.realpath、os.getcwd、os.mkdir、os.stat、os.lstat、os.readlink、os.readdir、os.utimes、os.exec、os.chdir、std.popen、std.loadFile、std.strerror、std.FILE.prototype.tello、std.parseExtJSON、std.setenv、std.unsetenv、std.getenviron。加了官方 Github 镜像。
下面我们通过安装 QuickJS 来小试下吧。
安装
QuickJS 的编译和咱们通过 Xcode 工程配置编译的方式不同,使用的是 makefile 来配置编译和安装的,和一些开源 C/C++ 工程编译使用 cmake 方式也有些不同,以前我们写些简单 c/c++ 的 demo 后,会简单的通过 clang 命令加参数进行编译和链接,但如果需要编译和链接的文件多了,编译配置复杂了,每次手工编写就太过复杂,因此就会用到 makefile 或者 cmake 来帮助减少复杂的操作提高效率。那什么是 makefile? 和 cmake 有什么关系呢?
我先介绍下什么是 makefile 吧。
makefile
makefile 是在目录下叫 Makefile 文件,由 make 这个命令工具进行解释执行。把源代码编译生成的中间目标文件 .o 文件,这个阶段只检测语法,如果源文件比较多,Object File 也就会多,再明确的把这些 Object File 指出来,链接合成一个执行文件就会比较繁琐,期间还会检查寻找函数是否有实现。为了能够提高编译速度,需要对没有编译过的或者更新了的源文件进行编译,其他的直接链接中间目标文件。而且当头文件更改了,需要重新编译引用了更改的头文件的文件。上面所说的过程只需要 make 命令和编写的 makefile 就能完成。
简单说,makefile 就是一个纯手动的 IDE,通过手动编写编译规则和依赖来配合 make 命令来提高编译工作效率。make 会先读入所有 include 的 makefile,将各文件中的变量做初始化,分析语法规则,创建依赖关系链,依据此关系链来定所需要生成的文件。
那么 makefile 的语法规则是怎样的呢?
makefile 的语法规则如下:
target ... : prerequisites ...
command
...
...其中的 target 可以是一个目标文件,也可以是一个可执行的文件,还可以是一个label。prerequisites 表示是 target 所依赖的文件或者是 target。prerequisites 的文件或 target 只要有一个更新了,对应的后面的 command 就会执行。command 就是这个 target 要执行的 shell 命令。
举个例子,我们先写个 main.c
#include <stdio.h>
#include "foo.h"
int main() {
printf("Hi! \n");
sayHey();
return 0;
}再写个 foo.c
#include "foo.h"
void sayHey() {
printf("Hey! \n");
}再写个 makefile
hi: main.o foo.o
cc -o hi main.o foo.o
main.o: main.c foo.h
cc -c main.c
foo.o: foo.c foo.h
cc -c foo.c
clean:
rm hi main.o foo.o在该目录下直接输 make 就能生成 hi 可执行文件,如果想要清掉生成的可执行文件和中间目标文件,只要执行 make clean 就可以了。
上面代码中冒号后的 .c 和 .h 文件就是表示依赖的 prerequisites。你会发现.o 文件的字符串重复了两次,如果是这种重复多次的应该如何简化呢,类似 C 语言中的变量,实际上在 makefile 里是可以有类似变量的语法,在文件开始使用 = 号来定义就行。写法如下:
objects = main.o foo.o使用这个变量的语法是 $(objects),使用变量语法后 makefile 就变成下面的样子:
objects = main.o foo.o
hi: $(objects)
cc -o hi $(objects)
main.o: main.c foo.h
cc -c main.c
foo.o: foo.c foo.h
cc -c foo.c
clean:
rm hi $(objects)makefile 具有自动推导的能力,比如 target 如果是一个 .o 文件,那么 makefile 就会自动将 .c 加入 prerequisites,而不用手动写,并且 cc -c xxx.c 也会被推导出,利用了自动推导的 makefile 如下:
objects = main.o foo.o
hi: $(objects)
cc -o hi $(objects)
main.o: foo.h
foo.o:
clean:
rm hi $(objects)make 中通配符和 shell 一样,~/js 表示是 $HOME 目录下的 js 目录,*.c 表示所有后缀是c的文件,比如 QuickJS 的 makefile 里为了能够随时保持纯净源码环境会使用 make clean 清理中间目标文件和生成文件,其中 makefile 的 clean 部分代码如下:
clean:
rm -f repl.c qjscalc.c out.c
rm -f *.a *.o *.d *~ unicode_gen regexp_test $(PROGS)
rm -f hello.c test_fib.c
rm -f examples/*.so tests/*.so
rm -rf $(OBJDIR)/ *.dSYM/ qjs-debug
rm -rf run-test262-debug run-test262-32上面的 repl.c、qjscalc.c 和 out.c 是生成的 QuickJS 字节码文件,*.a、*.o、*.d 表示所有后缀是a、o、d的文件。
如果要简化到编译并链接所有的 .c 和 .o 文件,可以按照下面的写法来写:
objects := $(patsubst %.c,%.o,$(wildcard *.c))
foo : $(objects)
cc -o foo $(objects)上面代码中的 patsubst 是模式字符串替换函数,%表示任意长度字符串,$加括号表示要执行 makefile 的函数,wildcard 的作用是扩展通配符,因为在变量定义和函数引用时,通配符会失效,因此这里 wildcard 的作用是获取目录下所有后缀是 .c 的文件。patsubst的语法如下:
$(patsubst <pattern>,<replacement>,<text>)根据此语法,上例里,就是将目录下所有 .c 后缀文件返回成同名 .o 的文件。在 patsubst 和 wildcard 在 QuickJS 的 makefile 里广泛使用,比如下面这段:
ifdef CONFIG_LTO
libquickjs.a: $(patsubst %.o, %.nolto.o, $(QJS_LIB_OBJS))
$(AR) rcs $@ $^
endif # CONFIG_LTO上面这段表示在配置打开 lto 后,会把 QJS_LIB_OBJS 这个变量定义的那些中间目标 .o 文件后缀缓存 .nolto.o 后缀。
QuickJS 的 makefile 中使用的函数除了patsubst 和 wildcard 还有 shell。shell 的作用就是可以直接调用系统的 shell 函数,比如 QuickJS 里的 $(shell uname -s),如果在 macOS 上运行会返回 Darwin,使用此方法可以判断当前用户使用的操作系统,从而进行不同的后续操作。比如 QuickJS 的 makefile 是这么做的:
ifeq ($(shell uname -s),Darwin)
CONFIG_DARWIN=y
endif上面代码可以看出,通过判断 shell 函数返回值来确定是否是 Darwin内核,将结果记录在变量 CONFIG_DARWIN 变量中。通过这个结果后续配置编译器为 clang。
ifdef CONFIG_DARWIN
# use clang instead of gcc
CONFIG_CLANG=y
CONFIG_DEFAULT_AR=y
endif在编写 makefile 时有些 prerequisites 和 target 会变,这样在命令中就不能写具体的文件名,在 makefile 里有种自动产生变量的规则,叫做自动化变量可以解决这样的问题,自动化变量还能解决 makefile 冗余问题,因为自动化变量用简短的语法替代重复编写 target 和 prerequisites,自动化变量有$@、$%、$<、$?、$+等,比如$@表示的是target,$^表示 prerequisites,GNU make 里在自动化变量里加入 D 或者 F 会变成变种自动化变量,能够代表更多意思,比如$(@F)表示在路径中取出文件名部分。自动化变量在 QuickJS 的 makefile 里使用很多。比如下面的代码:
$(OBJDIR)/%.o: %.c | $(OBJDIR)
$(CC) $(CFLAGS_OPT) -c -o $@ $<上面这段代码的作用是当.o文件依赖的编译中间产物或 c 源文件有更新时,会重新编译生成.o文件 $@ 表示的是 $(OBJDIR)/%.o,$< 表示的是 %.c | $(OBJDIR),简化了代码,$@ 就像数组那样会依次取出 target,然后执行。
依赖关系里会有.h 头文件,你一定奇怪在 QuickJS 的 makefile 里那些头文件为什么就没有出现在 prerequisites 中了,这是为什么呢?
这是因为有办法让 makefile 自动生成依赖关系。如果没有这办法自动生成依赖关系的话,在大型工程中,你就需要对每个 c 文件包含了那些头文件了解清楚,并在 makefile 里写好,当修改 c 文件时还需要手动的维护 makefile,因此这种工作不光重复而且一不小心还会错。
那有办法能解决重复易错的问题么?
编译器,比如 clang 有个选项 -MMD -MF 可以生成依赖关系,生成为同名的 .d 文件,.d 文件里有相应 .c 的所依赖的文件。因此可以在 makefile 里利用编译器这个特性,使用变种自动化变量$(@F)来设置编译配置,自动设置同名文件名的.d文件。在 QuickJS 中是这么配置编译标识的:
ifdef CONFIG_CLANG
HOST_CC=clang
CC=$(CROSS_PREFIX)clang
CFLAGS=-g -Wall -MMD -MF $(OBJDIR)/$(@F).d
CFLAGS += -Wextra
CFLAGS += -Wno-sign-compare
CFLAGS += -Wno-missing-field-initializers
CFLAGS += -Wundef -Wuninitialized
CFLAGS += -Wunused -Wno-unused-parameter
CFLAGS += -Wwrite-strings
CFLAGS += -Wchar-subscripts -funsigned-char
CFLAGS += -MMD -MF $(OBJDIR)/$(@F).d上面代码中的$(@F).d 表示会根据 target 的文件名生成对应的包含依赖关系的 .d 文件。
生成完 .d 文件后,需要用 include 命令把这些规则加到 makefile 里,看下 QuickJS 的做法:
-include $(wildcard $(OBJDIR)/*.d)makefile 还有些隐含的规则,比如把源文件编译成中间目标文件这一步可以省略不写,make 会自动的推导生成中间目标文件,对应命令是 $(CC) –c $(CPPFLAGS) $(CFLAGS),链接目标文件是通过运行编译器的ld来生成,也可以省略,对应的命令是$(CC) $(LDFLAGS)
ifdef CONFIG_DEFAULT_AR
AR=$(CROSS_PREFIX)ar
else
ifdef CONFIG_LTO
AR=$(CROSS_PREFIX)llvm-ar
else
AR=$(CROSS_PREFIX)ar
endif
endif上面 CROSS_PREFIX 变量实际上已经没用了,以前是因为要兼容在 Linux 下运行 Windows 所需要添加 mingw32 的前缀,目前这段变量定义已经被注释掉了。 隐含规则命令参数有编译器参数 CFLAGS 和链接器参数 LDFLAGS 等,这些变量可以根据条件判断或者平台区分,配置不同参数。
cmake
由于 GNU 的 make 和其他工具,比如微软的 nmake 还有 BSD 的 pmake 的 makefile 语法规则标准有不同,因此如果想为多个平台和工具编写可编译的 makefile 需要写多份 makefile 文件。
为了应对这样重复繁琐的工作,cmake 出现了。
我们可以编写 CMakeList.txt 这样的文件来定制编译流程,cmake 会将其转换成平台和工具相应的 makefile 文件和对应的工程文件(比如 Xcode 工程或Visual Studio工程)。比如你所熟悉的 LLVM 就是用的 cmake,源码各个目录下都有对应的 CMakeList.txt 文件。具体可以参看官方教程。
使用 qjsc -e 生成的 C 代码,通过编写如下的 CMakeLists.txt 配置:
cmake_minimum_required(VERSION 3.10)
project(runtime)
add_executable(runtime
# 如果有多个 C 文件,在这里加
src/main.c)
# 头文件和库文件
include_directories(/usr/local/include)
add_library(quickjs STATIC IMPORTED)
set_target_properties(quickjs
PROPERTIES IMPORTED_LOCATION
"/usr/local/lib/quickjs/libquickjs.a")
# 链接到 runtime
target_link_libraries(runtime
quickjs)按照上面代码编写,可以编译出可执行的文件了。
github 上有个 QuickJS 工程的 cmake 脚本,可以用来下载编译 QuickJS 库。
Xcode 来编译安装和调试 QuickJS 源码
由于 QuickJS 使用的是 makefile 管理,而 makefile 不能直接转成 Xcode 的工程文件,因此需要使用 Xcode 的 External Build System,创建工程 QuickJSXcode 后,给工程添加 QuickJS 源码文件,直接导入到工程即可,使用 ⌘ + B 构建工程,在 Product/Scheme/Edit Scheme 里选择 Run/Info,在 Executable 里选择刚才构建生成的 qjs 可执行文件。如下图: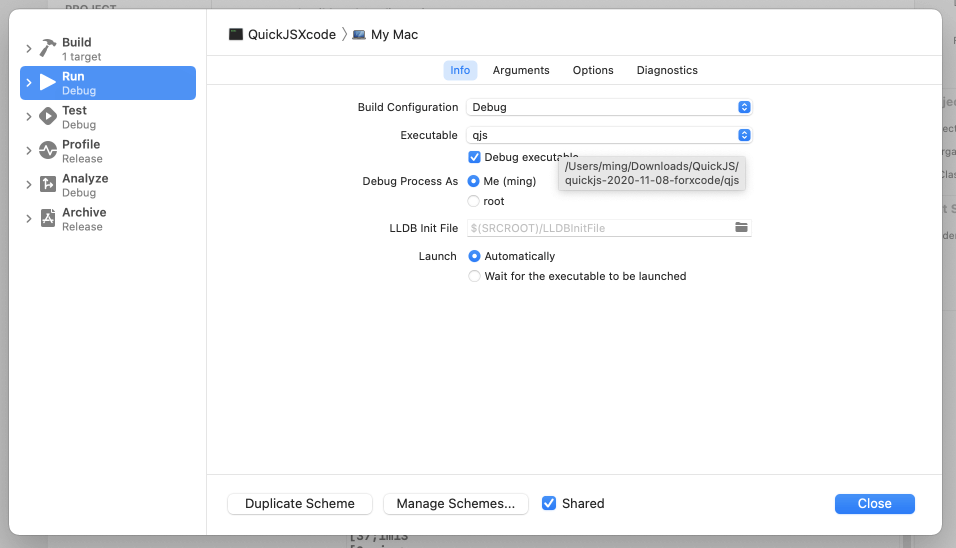
然后添加命令行工具 Target 辅助,在 Target 的 Dependencies 里添加 QuickJSXcode,在 Link Binary With Libraries 里添加编译出来的 libquickjs.a。最后在 Build Settings 的 Search Paths 里,将 QuickJS 代码路径添加到 Header Search Paths 和 Library Search Paths 里。完成后现在就可以使用 Xcode 进行 QuickJS 源码断点调试、自动补全和跳转了。如下图所示:
通过断点调试,更加方便阅读理解源码。可调试工程我放到了Github上,在这里。
QuickJS 在 VSCode 的调试的话,先 fork 一份 Koushik Dutta 的 QuickJS 修改版本,代码在这,VSCode 扩展的 github 地址,VSCode 扩展市场链接,对 QuickJS 修改的详细 Koushik Dutta 在邮件里有说明,邮件地址在这,Fabrice Bellard 看了也回邮件表示以后会增加调试接口。
使用方法
按照官方手册写的方式使用 makefile 安装后,命令行工具会被安装到 /usr/local/bin 目录下,此目录下会有 JS 解释器 qjs,有编译器 qjsc(QuickJS compiler) 编译 js 文件为可执行文件(QuickJS引擎 + js 文件打包,qjs 解释执行目标 js 文件),还有一个可以对任意长度数字计算的 qjscalc。编译的库会放到 /usr/local/lib/quickjs/ 目录下,有静态库 libquickjs.a,可以生成更小和速度更快的库 libquickjs.lto.a,lto(Link-Time-Optimization)需要在编译时加上 -flto 标识。
qjsc 还可以把 js 文件编译成 QuickJS 虚拟机的字节码,比如编写下面的一段 javascript 代码,保存为 helloworld.js
let myString1 = "Hello";
let myString2 = "World";
console.log(myString1 + " " + myString2 + "!");使用
qjsc -o hello helloworld.js就能够输出一个可执行文件 hello 可执行文件,运行后输出 hello world !。把参数改成-e 可以输出.c文件。
qjsc -e -o helloworld.c helloworld.js文件内容如下:
/* File generated automatically by the QuickJS compiler. */
#include "quickjs-libc.h"
const uint32_t qjsc_helloworld_size = 173;
const uint8_t qjsc_helloworld[173] = {
0x02, 0x09, 0x12, 0x6d, 0x79, 0x53, 0x74, 0x72,
0x69, 0x6e, 0x67, 0x31, 0x12, 0x6d, 0x79, 0x53,
0x74, 0x72, 0x69, 0x6e, 0x67, 0x32, 0x0a, 0x48,
0x65, 0x6c, 0x6c, 0x6f, 0x0a, 0x57, 0x6f, 0x72,
0x6c, 0x64, 0x0e, 0x63, 0x6f, 0x6e, 0x73, 0x6f,
0x6c, 0x65, 0x06, 0x6c, 0x6f, 0x67, 0x02, 0x20,
0x02, 0x21, 0x1a, 0x68, 0x65, 0x6c, 0x6c, 0x6f,
0x77, 0x6f, 0x72, 0x6c, 0x64, 0x2e, 0x6a, 0x73,
0x0e, 0x00, 0x06, 0x00, 0xa0, 0x01, 0x00, 0x01,
0x00, 0x04, 0x00, 0x00, 0x52, 0x01, 0xa2, 0x01,
0x00, 0x00, 0x00, 0x3f, 0xe1, 0x00, 0x00, 0x00,
0x80, 0x3f, 0xe2, 0x00, 0x00, 0x00, 0x80, 0x3e,
0xe1, 0x00, 0x00, 0x00, 0x82, 0x3e, 0xe2, 0x00,
0x00, 0x00, 0x82, 0x04, 0xe3, 0x00, 0x00, 0x00,
0x3a, 0xe1, 0x00, 0x00, 0x00, 0x04, 0xe4, 0x00,
0x00, 0x00, 0x3a, 0xe2, 0x00, 0x00, 0x00, 0x38,
0xe5, 0x00, 0x00, 0x00, 0x42, 0xe6, 0x00, 0x00,
0x00, 0x38, 0xe1, 0x00, 0x00, 0x00, 0x04, 0xe7,
0x00, 0x00, 0x00, 0x9d, 0x38, 0xe2, 0x00, 0x00,
0x00, 0x9d, 0x04, 0xe8, 0x00, 0x00, 0x00, 0x9d,
0x24, 0x01, 0x00, 0xcd, 0x28, 0xd2, 0x03, 0x01,
0x04, 0x3d, 0x3f, 0x35, 0x36,
};
static JSContext *JS_NewCustomContext(JSRuntime *rt)
{
JSContext *ctx = JS_NewContextRaw(rt);
if (!ctx)
return NULL;
JS_AddIntrinsicBaseObjects(ctx);
JS_AddIntrinsicDate(ctx);
JS_AddIntrinsicEval(ctx);
JS_AddIntrinsicStringNormalize(ctx);
JS_AddIntrinsicRegExp(ctx);
JS_AddIntrinsicJSON(ctx);
JS_AddIntrinsicProxy(ctx);
JS_AddIntrinsicMapSet(ctx);
JS_AddIntrinsicTypedArrays(ctx);
JS_AddIntrinsicPromise(ctx);
JS_AddIntrinsicBigInt(ctx);
return ctx;
}
int main(int argc, char **argv)
{
JSRuntime *rt;
JSContext *ctx;
rt = JS_NewRuntime();
js_std_set_worker_new_context_func(JS_NewCustomContext);
js_std_init_handlers(rt);
JS_SetModuleLoaderFunc(rt, NULL, js_module_loader, NULL);
ctx = JS_NewCustomContext(rt);
js_std_add_helpers(ctx, argc, argv);
js_std_eval_binary(ctx, qjsc_helloworld, qjsc_helloworld_size, 0);
js_std_loop(ctx);
JS_FreeContext(ctx);
JS_FreeRuntime(rt);
return 0;
}上面代码中,长度173的数组 qjsc_helloworld 记录的就是 quickjs 编译生成的字节码。js_std_loop 就是 Event Loop 处理的函数,是调用用户 js 回调的主循环,js_std_loop 函数实现代码很简洁,如下:
/* main loop which calls the user JS callbacks */
void js_std_loop(JSContext *ctx)
{
JSContext *ctx1;
int err;
for(;;) {
/* execute the pending jobs */
for(;;) {
err = JS_ExecutePendingJob(JS_GetRuntime(ctx), &ctx1);
if (err <= 0) {
if (err < 0) {
js_std_dump_error(ctx1);
}
break;
}
}
if (!os_poll_func || os_poll_func(ctx))
break;
}
}上面代码中的 os_poll_func 就是 js_os_poll 函数的调用,js_os_poll 函数在 quickjs-libc.c 里定义,会在主线程检查有没有需要执行的任务,没有的话会在后台等待事件执行。
简单说QuickJS集成使用过程是先将 QuickJS 源码编译成静态或动态库。makefile 会把头文件、库文件和可执行文件 copy 到标准目录下。然后 C 源码调用 QuickJS 提供的 API 头文件。最后编译生成可执行文件。
那么 js 和原生 c 的交互如何做呢?
调用原生函数
在 QuickJS 的 js 代码里可以通过 import 导入一个 c 的库,调用库里的函数。比如 QuickJS 中的 fib.c 文件,查看其函数 js_fib 就是对 js 里调用的 fib 函数的实现,使用的是 JS_CFUNC_DEF 宏来做 js 方法和对应 c 函数映射。映射代码如下:
static const JSCFunctionListEntry js_fib_funcs[] = {
JS_CFUNC_DEF("fib", 1, js_fib ),
};在 js 中使用起来也很简单,代码如下:
import { fib } from "./fib.so";
var f = fib(10);quickjs-libc 内置了些 std 和 os 原生函数可以直接供 js 使用,比如 std.out.printf 函数,先看在 js_std_file_proto_funcs 里的映射代码:
JS_CFUNC_DEF("printf", 1, js_std_printf ),可以看到对应的是 js_std_printf 函数,JS_CFUNC_DEF 宏的第二个参数为1表示 out。在 js 里使用的代码如下:
import * as std from 'std'
const hi = 'hi'
std.out.printf('%s', hi)怎么新建一个自己的库呢?
QuickJS 里的 fib 就是个例子,通过生成的 test_fib.c 可以看到下面的代码:
extern JSModuleDef *js_init_module_fib(JSContext *ctx, const char *name);
js_init_module_fib(ctx, "examples/fib.so");上面代码可以看到,可以声明一个 js_init_module_fib 函数并指定库的路径,创建一个 c 模块。在库的源文件 fib.c 里看实现 js_init_module_fib 函数的代码如下:
#ifdef JS_SHARED_LIBRARY
#define JS_INIT_MODULE js_init_module
#else
#define JS_INIT_MODULE js_init_module_fib
#endif
JSModuleDef *JS_INIT_MODULE(JSContext *ctx, const char *module_name)
{
JSModuleDef *m;
m = JS_NewCModule(ctx, module_name, js_fib_init);
if (!m)
return NULL;
JS_AddModuleExportList(ctx, m, js_fib_funcs, countof(js_fib_funcs));
return m;
}从上面代码可以看到,创建模块使用的是 JS_NewCModule 函数,接着通过 JS_AddModuleExportList 将模块的函数加到模块导出列表里。JS_SetModuleLoaderFunc 会设置读取库的函数为 js_module_loader,js_module_loader 会判断路径后缀,如果是.so 会调用 js_module_loader_so 函数。js_module_loader_so 会使用 dlopen 和 dlsym 来调用 so 库。
QuickJS 对调用 c 网络的使用可以参看 minnet-quickjs 的 minnet.c 封装接口实现。
js 调用 iOS 的 Objective-C 的方法可以参看 QuickJS iOS Bridge 这个工程,使用示例可以参看这段调用 Objective-C 网络请求的代码。
另外在 QuickJS 的邮件列表中看到些同学对 QuickJS 做了写扩展工作,将 QuickJS 的能力进行了增强。比如将 QuickJS 移植到 Fuchsia 操作系统上,在这里可以看到。qjs-ffi 对 QuickJS 增加 ffi 的支持。Eduard Suica 开发了 jib.js 可将 QuickJS 作为 js 解释器 的 js 运行时环境,兼容 Node.js,支持 socket、管道、文件和控制台。
接下来,我们深入 QuickJS 内部,看看 QuickJS 的源代码结构以及说说源码的原理。
源码文件介绍
我先对 QuickJS 源码文件做个介绍,主要文件如下:
- quickjs.c 和 quickjs.h:QuickJS 的核心代码,其他文件基本都会依赖于它。
- quickjs-lib.c 和 quickjs-lib.h:调用 QuickJS 接口 API,供 C 程序使用。
- quickjs-atom.h:定义了js的关键字原子字符串。
- quickjs-opcode.h:定义了字节码操作符
文件夹:
- examples/:一些 js 代码的示例,包含了和 c 交互的 js 代码
- tests/:测试 QuickJS 核心功能用的
- doc/:QuickJS 官方使用说明文档
一些可执行程序相关的文件:
- qjsc.c:编译完生成可执行文件 qjsc,是 QuickJS 的 Javascript 编译器。
- qjs.c:可交互解释执行的程序 qjs,是 QuickJS 的解释器。qjs 具有栈虚机内核,通过读取 js 文件解释执行,函数调用链是 main->eval_file->eval_buf->JS_EvalFunction->JS_EvalFunctionInternal->JS_CallFree->JS_CallInternal
- repl.js:js写的REPL程序。
- qjscalc.js:一个计算器程序。
其中 qjsc.c 会根据参数输入,挨个调用 compile_file 函数进行编译。参数说明如下:
ming@mingdeMacBook-Pro ~ % qjsc -h
QuickJS Compiler version 2020-11-08
usage: qjsc [options] [files]
options are:
-c 只输出字节码 C 文件,默认是输出可执行文件
-e 输出带 main 函数的字节码 C 文件
-o output 设置输出文件名,默认是 a.out 或者 out.c
-N cname 设置输出 c 文件的字节码数组的变量名
-m 编译成 JavaScript 模块
-D module_name 编译动态加载模块或 worker,也就是用了 import 或 os.Worker 的情况
-M module_name[,cname] 给外部 C 模块添加初始化代码
-x big endian 和 little endian 翻转,用于交叉编译
-p prefix 设置 C 变量名的前缀
-S n 设置最大栈大小,默认是 262144
-flto 编译成可执行文件使用 clang 的链接优化
-fbignum big number 支持的开启
-fno-[date|eval|string-normalize|regexp|json|proxy|map|typedarray|promise|module-loader|bigint]
让一些语言特性不可用,从而能够让生成的代码更小编译的过程是先使用 js_load_file 读取 js 文件内容,使用 JS_Eval 函数生成 JSValue 的对象,JSValue 是基本的值或指针地址,比如函数、数组、字符串都是值,然后使用 output_object_code 函数把对象的字节码写到文件里,也就是 dump 成二进制。生成可执行文件使用的函数是 output_executable。
qjs 的 Options -e 表示执行表达式,-i 表示进入交互模式,-I 表示加载文件,-d 会统计内存使用情况。
另外还有一些辅助函数 cutils.c、cutils.h。unicode 相关函数文件 libunicode.c、libunicode.h、libunicode-table.h。正则表达式支持相关文件 libregexp.c、libregexp.h、libregexp-opcode.h。链表 list.h。Decimal 任意精度科学计算 libBF libbf.c、libbf.h。
QuickJS 架构
QuickJS 的结构图如下:
如上图所示,其中最上层是 qjs 和 qjsc,qjs 包含了命令行参数处理,引擎环境创建,加载模块和 js 文件读取解释执行。qjsc 可以编译 js 文件成字节码文件,生成的字节码可以直接被解释执行,性能上看是省掉了 js 文件解析的消耗。
中间层是核心,JSRuntime 是 js 运行时,可以看做是 js 虚拟机环境,多个 JSRuntime 之间是隔离的,他们之间不能相互调用和通信。JSContext 是虚机里的上下文环境,一个 JSRuntime 里可以有多个 JSContext,每个上下文有自己的全局和系统对象,不同 JSContext 之间可以相互访问和共享对象。JS_Eval 和 JS_Parse 会把 js 文件编译为字节码。JS_Call 是用来解释执行字节码的。JS_OPCode 是用来标识执行指令对应的操作符。JSClass 包含标准的 js 的对象,是运行时创建的类,对象类型使用 JSClassID 来标记,使用 JS_NewClassID 和 JS_NewClass 函数注册,使用 JS_NewObjectClass 来创建对象。JSOpCode 是字节码的结构体,通过 quickjs-opcode.h 里的字节码的定义可以看到,QuickJS 对于每个字节码的大小都会精确控制,目的是不浪费内存使用,比如8位以下用不到1个字节和其他信息一起放在那1个字节里,8位用2个字节,整数在第2个字节里,16位用后2个字节。Unicode 是 QuickJS 自己做的库 libunicode.c,libunicode 有 Unicode 规范化和脚本通用类别查询,包含所有 Unicode 二进制属性,libunicode 还可以单独出来用在其他工程中。中间层还包含支持科学计算 BigInt 和 BigFloat 的 libbf 库,正则表达式引擎 libregexp。扩展模块 Std Module 和 OS Module,提供标准能力和系统能力,比如文件操作和时间操作等。
底层是基础,JS_RunGC 使用引用计数来管理对象的释放。JS_Exception 是会把 JSValue 返回的异常对象存在 JSContext 里,通过 JS_GetException 函数取出异常对象。内存管理控制 js 运行时全局内存分配上限使用的是 JS_SetMemoryLimit 函数,自定义分配内存用的是 JS_NewRuntime2 函数,堆栈的大小使用的是 JS_SetMaxStackSize 函数来设置。
总的来说 QuickJS 的运行方式如下图:
QuickJS 核心代码流程
quickjs.c 有5万多行代码。分析 QuickJS 代码可以从他解析执行 JS 代码的过程一步一步的分析。调用 QuickJS 执行一段 JS 代码的代码如下:
JSRuntime *rt = JS_NewRuntime();
JSContext *ctx = JS_NewContext(rt);
js_std_add_helpers(ctx, 0, NULL);
const char *scripts = "console.log('hello quickjs')";
JS_Eval(ctx, scripts, strlen(scripts), "main", 0);上面代码中 rt 和 ctx 是先构造一个 JS 运行时和上下文环境,js_std_add_helpers 是调用 C 的 std 方法帮助在控制台输出调试信息。
新建 Runtime
JS_NewRuntime 函数会新建一个 JSRuntime rt,Runtime的结构体 JSRuntime 包含了内存分配函数和状态,原子大小 atom_size 和原子结构数组指针 atom_array,记录类的数组 class_array,用于 GC 的一些链表 head,栈头 stack_top,栈空间大小(bytes)stack_size,当前栈帧 current_stack_frame,避免重复出现内存超出错误的 in_out_of_memory 布尔值,中断处理 interrupt_handler,module 读取函数 module_loader_func,用于分配、释放和克隆 SharedArrayBuffers 的 sab_funcs,Shape 的哈希表 shape_hash,创建一般函数对象外,还有种避开繁琐字节码处理更快创建函数对象的方法,也就是 Shape,创建 Shape 的调用链是 JS_NewCFunctionData -> JS_NewObjectProtoClass -> js_new_shape。创建 shape 的函数是 js_new_shape2,创建对象调用的函数是 JS_NewObjectFromShape。
创建的对象是 JSObject 结构体,JSObject 是 js 的对象,JSObject 的字段会使用 union,结构体和 union 的区别是结构体的字段之间会有自己的内存,而 union 里的字段会使用相同的内存,union 内存就是里面占用最多内存字段的内存。union 使用的内存覆盖方式,只能有一个字段的值,每次有新字段赋值都会覆盖先前的字段值。JSObject 里第一个 union 是用到引用计数的,__gc_ref_count 用来计数,__gc_mark 用来描述当前 GC 的信息,值为 JSGCObjectTypeEnum 枚举。extensible 是表示对象能否扩展。is_exotic 记录对象是否是 exotic 对象,es 规范里定义只要不是普通的对象都是 exotic 对象,比如数组创建的实例就是 exotic 对象。fast_array 为 true 用于JS_CLASS_ARRAY、JS_CLASS_ARGUMENTS和类型化数组这样只会用到 get 和 put 基本操作的数组。如果对象是构造函数 is_constructor 为 true。当 is_uncatchable_error 字段为 true 时表示对象的错误不可捕获。class_id 对应的是 JS_CLASS 打头的枚举值,这些枚举值定义了类的类型。原型和属性的名字还有 flag 记在 shape 字段,存属性的数组记录在 prop 字段。
first_weak_ref 指向第一次使用这个对象做键的 WeakMap 地址。在 js 中 WeakMap 的键必须要是对象,Map 的键可以是对象也可以是其他类型,当 Map 的键是对象时会多一次对对象引用的计数,而 WeakMap 则不会,WeakMap没法获取所有键和所有值。键使用对象主要是为了给实例存储一些额外的数据,如果使用 Map 的话释放对象时还需要考虑 Map 对应键和值的删除,维护起来不方便,而使用 WeakMap,当对象在其他地方释放完后对应的 WeakMap 键值就会被自动清除掉。
JS_ClASS 开头定义的类对象使用的是 union,因为一个实例对象只可能属于一种类型。其中 JS_CLASS_BOUND_FUNCTION 类型对应的结构体是 JSBoundFunction,JS_CLASS_BOUND_FUNCTION 类型是使用 bind() 方法创建的函数,创建的函数的 this 被指定是 bind() 的第一个参数,bind 的其他参数会给新创建的函数使用。JS_CLASS_C_FUNCTION_DATA 这种类型的对象是 QuickJS 的扩展函数,对应结构体是 JSCFunctionDataRecord。JS_CLASS_FOR_IN_ITERATOR 类型对象是 for…in 创建的迭代器函数,对应的结构体是 JSForInIterator。
JS_CLASS_ARRAY_BUFFER 表示当前对象是 ArrayBuffer 对象,ArrayBuffer 是用来访问二进制数据,比如加快数组操作,还有媒体和网络 Socket 的二进制数据,ArrayBuffer 对应 swift 里的 byte array,swift 的字符串类型是基于 Unicode scalar 值构建的,一个 Unicode scalar 是一个21位数字,用来代表一个字符或修饰符,比如 U+1F600 对应的修饰符是 😀,U+004D 对应的字符是 M。因此 Unicode scalar 是可以由 byte array 来构建的。byte array 和字符之间也可以相互转换,如下面的 swift 代码:
// 字符转 byte array
let str = "starming"
let byteArray: [UInt8] = str.utf8.map{ UInt8($0) }
// byte array 转字符
let byteArray:[UInt8] = [115, 116, 97, 114, 109, 105, 110, 103]
let str = String(data: Data(bytes: byteArray, count: 8), encoding: .utf8)上面代码中,将 starming 字符串转换成了 [115, 116, 97, 114, 109, 105, 110, 103] byte array,逆向过来也没有问题。
typed_array 字段包含如下类型:
JS_CLASS_UINT8C_ARRAY, /* u.array (typed_array) */
JS_CLASS_INT8_ARRAY, /* u.array (typed_array) */
JS_CLASS_UINT8_ARRAY, /* u.array (typed_array) */
JS_CLASS_INT16_ARRAY, /* u.array (typed_array) */
JS_CLASS_UINT16_ARRAY, /* u.array (typed_array) */
JS_CLASS_INT32_ARRAY, /* u.array (typed_array) */
JS_CLASS_UINT32_ARRAY, /* u.array (typed_array) */
#ifdef CONFIG_BIGNUM
JS_CLASS_BIG_INT64_ARRAY, /* u.array (typed_array) */
JS_CLASS_BIG_UINT64_ARRAY, /* u.array (typed_array) */
#endif
JS_CLASS_FLOAT32_ARRAY, /* u.array (typed_array) */
JS_CLASS_FLOAT64_ARRAY, /* u.array (typed_array) */
JS_CLASS_DATAVIEW, /* u.typed_array */typed_array 也就是类型化数组,其结构体是 JSTypedArray。类型化数组把实现分为 ArrayBuffer 对象缓冲,使用视图读写缓冲对象中的内容,视图会将数据转换成有类型的数组。
map_state 字段的结构体是 JSMapState,用来存放以下对象类型的状态:
JS_CLASS_MAP, /* u.map_state */
JS_CLASS_SET, /* u.map_state */
JS_CLASS_WEAKMAP, /* u.map_state */
JS_CLASS_WEAKSET, /* u.map_state */上面对象类型的状态,状态包括是否是 weak 的Map、Map 记录链接头、记录数量、链接头哈希表、哈希大小、调整哈希表大小的次数。
Map 的迭代器类型是 JS_CLASS_MAP_ITERATOR 和 JS_CLASS_SET_ITERATOR,对应的结构体是 JSMapIteratorData。数组迭代器的类型是 JS_CLASS_ARRAY_ITERATOR 和 JS_CLASS_STRING_ITERATOR,对应结构体是 JSArrayIteratorData。正则表达式迭代器的类型是 JS_CLASS_REGEXP_STRING_ITERATOR,对应结构体是 JSRegExpStringIteratorData。function 后带一个星号这样表示的函数是生成器函数,类型是 JS_CLASS_GENERATOR,结构体是 JSGeneratorData,生成器函数会返回一个 generator 对象。生成器函数用于 coroutine,函数内通过 yield 语句可以将函数执行暂停,让其他函数可以执行,再次执行可以从暂停处继续执行。
最后就是 big number 的数值运算,包括 bigint_ops、bigfloat_ops、bigdecimal_ops。
JS_NewRuntime 函数对 JSRuntime 和 JSMallocState 初始化使用的是 memset 函数,这个函数一般是对比较大些的结构体进行初始化,因为是直接操作内存,所以很快。JS_NewRuntime 函数使用的 JSMallocFunctions 结构体来记录 JSMallocState 分配内存状态。 JSRuntime 里用 context_list 记录所有的上下文,gc_obj_list 记录分配的 GC 对象,在调用 JS_FreeValueRT 函数时如果 JSValue 的 tag 是字节码,同时不在 GC 清理周期内时,会将 GC 对象加到 gc_zero_ref_count_list 里。
接着 JS_NewRuntime 函数会调用 JS_InitAtoms 函数去初始化 Atom,包括那些 js 的关键字和symbol等。QuickJS 使用 include quickjs-atom.h 文件方式导入的 atom,代码如下:
enum {
__JS_ATOM_NULL = JS_ATOM_NULL,
#define DEF(name, str) JS_ATOM_ ## name,
#include "quickjs-atom.h"
#undef DEF
JS_ATOM_END,
};上面代码中的 JS_ATOM_END 作为枚举的最后一个值,同时能够表示 atom 的数量,atom 还会记录在 js_atom_init[] 里。代码如下:
static const char js_atom_init[] =
#define DEF(name, str) str "\0"
#include "quickjs-atom.h"
#undef DEF
;定义枚举的作用就是能够在编译时确定 atom 的数量,比在运行时通过计算数组数量性能消耗少。在 JS_InitAtoms 函数里通过 JS_ATOM_END 将遍历 js_atom_init 函数初始化每个 atom,js_atom_init 函数里会先使用 js_alloc_string_rt 为字符串分配内存将字符串拷贝到空间内,最后调用 __JS_NewAtom 函数新建 atom。
JS_NewRuntime 函数最后会用 init_class_range 函数创建对象、数组和函数类,每个类新建用的是 JS_NewClass1 函数,这里会完成 JSClass 结构体的初始化,重置上下文类原型数组和类数组。通过 JSClassCall 和 JSClassExoticMethods 来设置 JSClass。JSClassCall 会调用 js_call_c_function、js_c_function_data_call、js_call_bound_function、js_generator_function_call。JSClassExoticMethods exotic 是外来行为的指针,没有可以为 NULL,JS_NewRuntime 函数会设置 js_arguments_exotic_methods、js_string_exotic_methods、js_module_ns_exotic_methods 三个行为。
新建上下文
JS_NewContext 函数会通过 JS_NewContextRaw 初始化一个上下文,并将上下文 JSContext 的 rt 字段,也就是 JSRuntime 结构体字段指向入参 rt。JSContext 结构体里面包含了 GC 对象的 header,JSRuntime,对象数量和大小,shape的数组,全局对象 global_obj 和全局变量包括全局 let/const 的定义。跟 big number 相关的 bf_ctx,rt->bf_ctx 是指针,共享所有上下文。fp_env 是全局 FP 环境。通过 bignum_ext 来控制是否开启数学模式,all_operator_overload 来控制是否开启 operator overloading。当计数器为0后,JSRuntime.interrupt_handler 就会被调用。loaded_modules 是 JSModuleDef.link 的列表。compile_regexp 函数如果返回的 JSValue是 NULL 表示输入正则表达式的模式不被支持。eval_internal 函数如果返回 NULL 表示输入的字符串或者文件 eval 没法执行。
使用 JS_AddIntrinsicBasicObjects 函数对上下文初始化内置构造函数的原型对象。JS_AddIntrinsicBaseObjects 函数会往全局对象 ctx->global_obj 里添加标准库的对象 Object、函数 Function、错误 Error、迭代器原型、数组 Array、Number、布尔值 Boolean、字符串 String、Math、ES6反射、ES6 symbol、ES6 Generator等,然后定义全局属性和初始化参数。JS_AddIntrinsicDate 函数会添加 Date,JS_AddIntrinsicEval 会设置内部 eval 函数为 __JS_EvalInternal。JS_AddIntrinsicStringNormalize 函数会设置属性 normalize。
JS_AddIntrinsicRegExp 函数会添加 正则表达式库 RegExp。JS_AddIntrinsicJSON 函数会在全局对象中添加 JSON 标准库。JS_AddIntrinsicProxy 函数用来添加为 js 提供元编程能力的 Proxy,用来进行目标对象拦截、运算符重载、对象模拟等。
JS_AddIntrinsicMapSet 函数会添加 Map。JS_AddIntrinsicTypedArrays 会添加由 Lars T. Hansen 设计的 SharedArrayBuffer 和 Atomics,也就是共享内存和原子特性,该提案在这 17年被 TC39 合并到 ecma262 规范中,共享内存可以让多线程并发读写数据,使用原子控制并发,协调有竞争关系线程,其目的就是让 web worker 间共享数据协调更快更简单避免幽灵漏洞。
JS_AddIntrinsicPromise 函数会添加 Promise、AsyncFunction 和 AsyncGeneratorFunction
如果开启了 big number JS_NewContext 函数会调用 JS_AddIntrinsicBigInt 添加 BigInt 来支持科学计算。
JS_Eval
JS_Eval 方法就是执行 JS 脚本的入口方法。JS_Eval 里调用情况如下:
JS_Eval -> JS_EvalThis -> JS_EvalInternal -> eval_internal(__JS_EvalInternal)实际起作用的是 __JS_EvalInternal 函数,内部会先声明整个脚本解析涉及的内容,比如 JSParseState s、函数对象和返回值 fun_obj、栈帧 sf、变量指针 var_refs、函数字节码 b、函数 fd、模块 m 等。通过函数 js_parse_init 来设置初始化 JSParseState。有上下文 ctx、文件名 filename、根据输入 input 字符串长度设置缓存大小和初始化 token 等。
js_parse_init 函数执行完后会过滤 Shebang,Shebang 一般是会在类 Unix 脚本的第一行,规则是开头两个字符是#!,作用是告诉系统希望用什么解释器执行脚本,比如#!/bin/bash 表示希望用 bash 来执行脚本。在 QuickJS 里显然 Shebang 起不了什么用,因此通过 skip_shebang 函数过滤掉。
eval_type 获取 eval 的类型,eval 的 type 有四种,JS_EVAL_TYPE_GLOBAL 00 表示默认全局代码,JS_EVAL_TYPE_MODULE 01 表示模块代码,JS_EVAL_TYPE_DIRECT 10 表示在 internal 直接调用,JS_EVAL_TYPE_INDIRECT 11 表示在 internal 非直接调用。eval 的 flag有四种,JS_EVAL_FLAG_STRICT 10xx 表强行 strict 模式,JS_EVAL_FLAG_STRIP 100xx 表强行 strip 模式,JS_EVAL_FLAG_COMPILE_ONLY 1000xx 表示仅编译但不运行,返回是一个有 JS_TAG_FUNCTION_BYTECODE 或 JS_TAG_MODULE tag 的对象,通过 JS_EvalFunction() 函数执行。JS_EVAL_FLAG_BACKTRACE_BARRIER 10000xx 表示在 Error 回溯中不需要之前的堆栈帧。
__JS_EvalInternal 函数使用 js_new_function_def 函数创建一个顶层的函数定义节点,其第二个参数为父函数设置为 NULL,后面再解析出来的函数都会成为他的子函数,js_new_function_def 会返回一个初始化的 JSFunctionDef。JSFunctionDef 的字段 parent_scope_level 是当前函数在父层作用域的层级。parent_cpool_idx 是当前函数在父层的常量池子里索引。child_list 是子函数列表。is_eval 如果为 true 表示当前函数代码是 eval 函数调用的。is_global_var 表示当前函数是否不是局部的,比如是全局的,在 module 中或非 strict。
has_home_object 表示当前函数是否是 home object。每个函数都有一个 slot 用来存函数的 home object,这个 slot 可以通过[[HomeObject]]访问到,home object 就是函数的初始定义。slot 只有在函数定义为 class 或 object literals 才会被设置,其他情况会返回 undefined。如下的函数定义:
let ol = { foo () {} }
class c { foo () {} }
function f () {}上面的 f 函数会直接返回 undefined,c 是 class,ol 是 object literals,当 super 方法被调用时会查看当前函数的[[HomeObject]],从而获取原型,通过原型调用到 super 方法。
has_prototype 是指当前函数是否有 prototype,class 都有 prototype。has_parameter_expressions 指是否有参数表达式,如果有就会创建参数作用域。has_use_strict 表示是否是强制模式。has_eval_call 表示函数里是否有调用 eval 函数。
has_arguments_binding 指函数是否有参数绑定,如果有就是箭头函数。箭头函数是使用 => 定义函数,如下面代码:
// 带参数
var foo = v => v
// 对应如下非箭头函数
var foo = function(v) { return v }
// 无参数
var foo = () => 0
// 对应如下非箭头函数
var foo = function() { return 0 }箭头函数内的 this 是指定义时的对象,而不是运行时的对象,使 this 从动态变成静态。不能使用 new 命令,不可以用 arguments 对象,使用 rest 参数代替,不可以使用 yield。
箭头函数的意图主要是可以让表达更简洁,如下代码:
// 不用箭头函数
var sortedGroup = group.sort(function(a, b) {
return a - b;
});
// 使用箭头函数
var sortedGroup = group.sort((a, b) => a - b);箭头符号前面的小括号内是参数,代码整体看起来简洁了很多。
36年图灵开发的有计算功能的数学模型叫图灵机,而同期 Alan Church 开发的模型叫 λ 演算,λ 就是 lambda,Lisp 就是用 lambda 来表示函数,至今函数表达式也叫 lambda。因此 λ 演算算得上最早的编程语言。《ES6 In Depth:Arrow functions》博客里提到 fixed point 函数如下:
fix = λf.(λx.f(λv.x(x)(v)))(λx.f(λv.x(x)(v)))上面的 fix 函数可以使用箭头函数,代码如下:
var fix = f => (x => f(v => x(x)(v)))
(x => f(v => x(x)(v)));上面代码看起来更加简洁和清晰。
使用函数式编程设计为 js 提供了类似 each、map、reduce、filter 等使用功能的著名underscorejs ,就是重度使用了箭头函数,以简化 underscorejs 的使用接口。
完整的箭头函数定义参看 ecma262 Arrow Function Definitions 部分。
has_this_binding 指函数里是否可以用 new.target。new_target_allowed 指 new.target 的返回是指向构造方法,因此如果没有 new.target 表示只是普通的函数。super_call_allowed 指函数是否可调用 super 函数,构造函数里调用父类构造器。super_allowed 表示函数是否可以用 super 或 super[],类的 method 可以调,普通的函数不能调。arguments_allowed 表示当前函数是否可以使用 arguments,箭头函数不能使用 arguments。arguments和剩余变量区别在剩余变量是个数组,arguments需要通过 Array.prototype.slice.call 函数转成真正的数组。is_derived_class_constructor 表示当前函数是否为派生函数,继承自其他类的类叫派生类。in_function_body 是看函数是否是在函数的 body 里定义的,如果是 false 表示函数可能是在参数里定义。func_name 是函数名,如果没有函数名 func_name 为 JS_ATOM_NULL。vars 是函数里定义的变量列表。var_size 是给变量列表分配的空间大小。var_count 是变量的数量。args 是函数参数的列表。arg_size 是给参数列表分配的空间大小。arg_count 是参数的个数。defined_arg_count 表示函数期望的参数数,也就是实际传递给函数的参数,比如有默认值的参数就不会计算在内。arguments_var_idx 是 arguments 变量在函数变量列表里的索引。func_var_idx 是当前函数在函数变量列表里的索引。eval_ret_idx 是当前函数返回值在函数变量列表里的索引。this_var_idx 指 this 在函数变量列表里的索引。new_target_var_idx 是包含 new.target 的变量在函数变量列表里的索引。this_active_func_var_idx 是包含 this.active_func 变量在函数变量列表里的索引。home_object_var_idx 是 home object 变量在函数变量列表里的索引,使用这个索引可以取到父函数。scope_level 是当前函数作用域层级,也就是 fd->scopes 的索引。scope_first 是第一个作用域。scope_size 是为函数多个作用域分配的大小。scope_count 指一共有多少个作用域。scopes 指当前函数所有作用域的数组。body_scope 是函数 body 的作用域。byte_code 是函数的字节码。last_opcode_pos 是最后一个字节码操作符。last_opcode_line_num 是最后一个字节码操作符所在行数。cpool 是定义常量的池子,比如字符串、数字、对象、数组等。closure_var_count 是闭包的数量。closure_var_size 是闭包的大小。closure_var 闭包都放在这个数组里。filename 指函数所在的文件的文件名。line_num 是函数的行数。pc2line 表示代码行号。source 是函数源码。source_len 是源文件大小。module 也会当作函数一样处理。
创建顶级函数定义
js_new_function_def 会通过运行 JS_NewAtom 函数,来返回一个文件名 JSAtom。JS_NewAtom 函数调用链如下:
JS_NewAtom -> JSNewAtomLen -> JS_NewAtomStr -> __JS_NewAtomJSAtom 是 uint32_t 类型整数,用来记录关键字等字符串,作用是提高字符串内存占用和使用的效率。JSAtom 的类型有 JS_ATOM_TYPE_STRING、JS_ATOM_TYPE_GLOBAL_SYMBOL、JS_ATOM_TYPE_SYMBOL、JS_ATOM_TYPE_PRIVATE。JS_NewRuntime 函数执行时会把 quickjs-atom.h 里定义的 JS 关键字比如 if、new、try等,保留字比如 class、enum、import 等,标识符 name、get、string 等加到内存中,解析中加的会按需使用。字符串转 JSAtom 是通过 __JS_NewAtom 函数来做的,__JS_NewAtom 函数会先尝试看已注册的 atom 里是否已经有对应的字符串,没有就根据定义的规则算出字符串的 hash 值 i,然后把字符串指针加到 JSAtomStruct 类型的 atom_array 里。
如果已经有相同的 atom 在 atom_array 里,goto 到 done label里,C 语言中的 goto 语句是一种把控制无条件转移到同函数内label处的语句。我觉得使用 goto 主要是为了减少多个 return 的情况,特别是逻辑多,最后需要进行统一处理时,代码上看起来会更顺,按顺序读,可读性会好。__JS_NewAtom 函数出现异常就会 goto 到 fail label中,将 i 设置为 JS_ATOM_NULL 类型。done label会执行 js_free_string 函数,调用的是 JS_FreeAtomStruct 函数,目的是从 atom_array 里移出 atom,过程是先从链表中移出 atom 然后在 atom_array 里将其标记为空闲,这样新加的 atom 就可以放置到这个位置。
字符串存储的结构是 JSString,ascii 会存放在 JSString 的 union 中 str8 中。在 JS_NewAtomLen 函数里会先将字符串通过 JS_NewStringLen 转成 JSValue,然后通过宏 JS_VALUE_GET_STRING 将其转成 JSString。
最后 __JS_NewAtom 函数会对 atom_array 做些边界处理。
js_new_function_def 函数执行完创建了顶级函数定义后,会做个判断,如果创建失败会直接使用 goto 语法跳转到
fail1 label处,fail1 label会释放所有 JSModuleDef。
如果没有失败 __JS_EvalInternal 函数会先将 JSParseState 的当前函数设置为 js_new_function_def 创建的函数 fd。然后对 fd 进行字段的设置。使用 push_scope 生成一个作用域,后面解析的内容会放到这个作用域内。接下来就开始执行解析函数 js_parse_program,入参是 JSParseState 类型的 s,s 记录着 fd,用来作为解析内容的输入。
js 解析和生成字节码
js_parse_program 函数会先调用 next_token 获取一个 token 到传入的 JSParseState 里。接着通过 js_parse_directives 来解析 use strict 指令。如果在模块头部加上了 use strict 指令,表示 ES 模块需要使用严格模式。严格模式会对一些语法做限制,具体可以参看 ecma262 里 The Strict Mode of ECMAScript 说明。然后 js_parse_program 函数会一直调用 js_parse_source_element 函数直到返回的 token 是 TOK_EOF(文件结束符)为止。
对于一个 JS 脚本里的代码,可以分为四个种类,一种是表达式声明,使用 js_parse_statement_or_decl 函数解析,解析类似 if、while 这样语句。一种是函数声明,使用js_parse_function_decl 函数解析,另外两种是 export,使用 js_parse_export 解析模块导出 和 import,使用 js_parse_import 解析模块导入。js_parse_source_element 函数根据每个 token 的种类选择不同的函数进行解析。
js_parse_export 函数和 js_parse_import 函数解析模块的两个主要功能,其中 export 主要是负责定义模块对外部的接口,import 主要是负责接受外部模块的接口以供调用。JS 的一个模块如果想让其他模块使用其内部的变量、函数和类就需要使用 export 命令,比如在某个js文件中定义可被其他模块访问的数据的代码如下:
export var aExportVar = 0;
var anotherExportVar = 1;
export {anotherExportVar};
export function foo() {};上面代码中 aExportVar、anotherExportVar 变量和 foo 函数 都能被其他模块读取。如果想重命名导出,可以使用 as 关键字,比如 export {a as b}。如果想都导出可以用 export * from “mod”,在 js_parse_export 函数解析中,对于类、函数、大括号、from、var、let、const、as等涉及 export 的关键字均有处理,解析规则参看 ecma262 的 Exports 部分,关于 default 这种 export 和 import 的复合写法提案 export default from,在 QuickJS 里也得到了支持,在 js_parse_export 函数的 TOK_DEFAULT 条件处理里可以看到。解析的 export 数据会通过 add_export_entry 返回一个 JSExportEntry 并放到 JSModuleDef 的 export_entries 数组中记录。
import 会将模块 export 定义输出的接口加载到自己的模块中,规则可参看 TC39 的 Import,为了支持 import 函数能够支持动态加载,TC39 merge 了 Dynamic import 这个提案,Dynamic Import 配合 webpack 的代码分割实现异步懒加载,对于页面加载性能是个很好的方案。js_parse_import 函数会将 import 模块通过 add_import 函数将 import 数据转成 JSImportEntry 添加到 JSModuleDef 的 import_entries 数组中。
接下来看下第三种,函数定义解析函数 js_parse_function_decl。js_parse_function_decl 内是执行的 js_parse_function_decl2 函数。js_parse_function_decl2 函数会依据 JSParseFunctionEnum 枚举值 func_type 进行不同的解析和字节码生成,生成的字节码的函数是前缀为 emit 的函数,字节码会存在 JSParseState 的当前函数 cur_func 的 byte_code 字段中。func_type 有 statement、var、expr、arrow、getter、setter、method、类的构造函数、派生类的构造函数。其中 statement、var、expr、arrow 类型都是匿名函数。
创建一个新的函数,将 s->cur_func 作为其父函数,通过 s->cur_func = fd; 将 JSParseState 的当前函数设置为新创建的 JSFunctionDef,以此能够生成函数定义树结构。然后开始解析参数,参数通过 add_arg 函数添加到 fd 的 args 数组中。小括号内的参数通过 js_parse_expect(s, ‘(‘) 函数起始,在 while (s->token.val != ‘)’) 闭包内解析。小括号内如有中括号和大括号,也就是有数组和对象的情况就使用 js_parse_destructuring_element 函数进行解析,由于对象和数组会出现在各种 js 的语法中,所以将其处理包装成了一个通用的递归函数 js_parse_destructuring_element 用来简化写法。
设置完参数变量作用域后,就开始函数 body 的解析。如果是箭头函数,QuickJS 会特殊处理,并在处理完直接 goto 到 done label。js_parse_function_decl2 函数对于箭头函数会用两个函数先做检查,一个是检查函数名函数 js_parse_function_check_names,如果有函数名就直接 goto 到 fail label。另一个检查函数是 js_parse_assign_expr 赋值表达式解析函数,比如 = 或 += 这样的符号,如果箭头函数后面是赋值表达式,那么也会直接 goto 到 fail。如箭头函数规则符合,会使用 emit_op 生成 OP_return 字节码操作符,并用将源码保存在 fd->source 里。
不是箭头函数就在大括号内执行递归函数 js_parse_source_element 解析表达式和子函数,形成完整的函数定义树结构。递归调用代码如下:
while (s->token.val != '}') {
if (js_parse_source_element(s))
goto fail;
}完成后也会保存源码到 JSFunctionDef 的 source 字段里。eat } 符号后 js_parse_function_decl2 函数会 goto 到 fail。无论是 done label还是 fail label都会将 cur_func 设置为父函数,回到父函数里继续解析后面的代码。
最后第四种,js_parse_statement_or_decl 声明和表达式解析函数。
js_parse_statement_or_decl 函数主要依据 token 的值类型来分别调用对应的解析函数。token 的值是大括号时会调用 js_parse_block 解析。return 会看下一个 token 的值,如果不是 ;、},那么就会调用 js_parse_expr 函数。throw 也会调用 js_parse_expr,如果没有表达式就添加 OP_throw 字节码操作符。
let、const、var 都会调用 js_parse_var 函数解析。js_parse_var 处理等号右侧使用的是 js_parse_assign_expr2 函数来解析赋值表达式,其中会使用 js_parse_cond_expr 来解析问号和冒号这样的条件运算符,解析 ?: 表达式,?: 运算符是三元运算符,条件为真执行 ? 后面表达式,为假执行 : 后面表达式,规则参看 Condition Operator,冒号部分使用的是 Coalesce 表达式解析函数 js_parse_coalesce_expr,解析 ?? 表达式,?? 运算符是非空运算符,如果第一个参数不是 null 或 undefined,那么就会返回第一个参数,不然就返回第二个参数。与或使用 js_parse_logical_and_or 函数解析 && 或 || 这样表达式,二元表达式使用 js_parse_expr_binary 函数,解析 * + == 等表达式, 一元使用 js_parse_unary 函数,比如 + ! 等。如果赋值是字符串、数字等最小单元就使用 js_parse_postfix_expr 函数。
if 会在开始和结束分别调用作用域的进栈 push_scope 和出栈 pop_scops 函数,if 内会递归调用 js_parse_statement_or_decl 函数。while 会用 new_label 函数创建条件和退出的 label,使用 push_break_entry 加到 BlockEnv 结构体中记录。while 解析完会调用 pop_break_entry 函数将 fd->top_break 设置为 BlockEnv 的前一个 break。while 内也是递归调用 js_parse_statement_or_decl 函数。相比较于 while,for 会多调用 js_parse_for_in_of 去解析 for/in 或者 for/of。break 和 continue 都会直接 goto 到 fail。
switch、try、with 主要是 BlockEnv 设置不同,其他部分都是按照正常声明和表达式方式解析。如果是 class 的话,会调用 js_parse_class 函数来解析 class。es 标准里的 empty statement 和 debugger statement 虽然只是简单的 goto 到 fail,但也都有处理。js_parse_statement_or_decl 函数处理详细标准可以参看 ecma262 的 Statements and Declarations。
__JS_EvalInternal 函数执行完解析函数 js_parse_program 后开始调用 js_create_function 函数来创建函数对象和所有包含的子函数。
js_create_function 创建函数对象及包含的子函数
js_create_function 函数会从 JSFunctionDef 中创建一个函数对象和子函数,然后释放 JSFunctionDef。开始会重新计算作用域的关联,通过四步将作用域和变量关联起来,方便在作用域和父作用域中查找变量。第一步遍历函数定义里的作用域,设置链表头。第二步遍历变量列表,将变量对应作用域层级链表头放到变量的 scope_next 里,并将变量所在列表索引放到变量对应作用域层级链表头里。第三步再遍历作用域,将没有变量的作用域指向父作用域的链表。第四步将当前作用域和父作用域变量链表连起来。通过 fd->has_eval_call 来看是否有调用 eval,如果有,通过 add_eval_variables 来添加 eval 变量。如果函数里有 eval 调用,add_eval_variables 函数会将 eval 里的闭合变量按照作用域排序。add_eval_variables 函数会为 eval 定义一个给参数作用域用的额外的变量对象,还有需定义可能会使用的 arguments,还在参数作用域加个 arguments binding,另外,eval 可以使用 enclosing 函数的所有变量,因此需要都加到闭包里。
pass 1
js_create_function 函数还会使用 add_module_variables 函数添加模块闭包中的全局变量。import 其他模块的全局会通过 js_parse_import 函数作为闭包变量添加进来,add_module_variables 函数是添加 module 里的全局变量,将模块的全局变量通过 add_closure_var 函数加到当前函数定义里,并处理类型是 JS_EXPORT_TYPE_LOCAL 的 exports 的变量。add_module_variables 函数会先添加通过 js_parse_import 函数导入作为闭包变量的全局变量,添加闭包变量调用的是 add_closure_var 函数。遍历 fd->child_list 递归使用 js_create_function 函数创建所有子函数,将创建的子函数对象保存在 fd->cpool 里,cpool 是一个 JSValue 结构体,JSValue 是最基本的单位,这个结构体会有一个 tag 来标示 JSValue 的类型,值是保存在 JSValueUnion 里,值可以是整型和浮点,也可以是一个对象的指针,指针指向的对象是由引用计数来进行管理的,引用计数结构体是 JSRefCountHeader。这里 JSValue 的值是个数组。
如果打开了 DUMP_BYTECODE(将 #define DUMP_BYTECODE (1) 这段注释打开),js_create_function 函数会先进行第一次 dump_byte_code 函数调用,dump_byte_code 函数入参 tab 是字节码,函数主要通过 get 前缀的函数,比如 get_u32 和 get_u16 来取字节码的值,并打印出来。
前面 js_create_function 函数 dump 的字节码可以称为 pass 1,如果只 dump 这个阶段字节码,将 DUMP_BYTECODE 设置为4,dump pass 2 阶段字节码需要调用 resolve_variables 函数。
pass 2(resolve_variables)
解析当前函数的字节码的操作符,op 就是当前的操作符。add_scope_var 函数用来添加变量,add_scope_var 函数会调用 add_var 函数将变量添加到函数定义 JSFunctionDef 的 vars 字段里,add_var 调用完,add_scope_var 函数会继续设置变量定义结构体 JSVarDef 的 scope_level、scope_next 和 scope_first,其中 scope 的作用是在进入新作用域时能找到最临近的变量。QuickJS 在解析时会生成使用变量的字节码,比如 OP_scope_get_var 字节码操作符。
resolve_variables 函数会在需要的时候将全局变量访问转换成局部变量或闭包变量。resolve_variables 函数会先做运行时检查,然后遍历所有字节码,字节码操作符是 OP_eval 和 OP_apply_eval 时将作用域索引转换成调整后的变量索引。当字节码是 OP_scope_get_var_undef、OP_scope_get_var、OP_scope_put_var、OP_scope_delete_var、OP_scope_get_ref、OP_scope_put_var_init、OP_scope_make_ref 时都会调用 resolve_scope_var 函数,在作用域里查找变量,对字节码操作符进行优化。对应 QuickJS 代码如下:
case OP_scope_get_var_undef:
case OP_scope_get_var:
case OP_scope_put_var:
case OP_scope_delete_var:
case OP_scope_get_ref:
case OP_scope_put_var_init:
var_name = get_u32(bc_buf + pos + 1);
scope = get_u16(bc_buf + pos + 5);
pos_next = resolve_scope_var(ctx, s, var_name, scope, op, &bc_out,
NULL, NULL, pos_next);
JS_FreeAtom(ctx, var_name);
break;resolve_variables 函数就是使用前面添加的变量。resolve_variables 函数先遍历当前函数定义的作用域,如果找到对应的符号就生成对应优化的字节码操作符,没有找到会看函数内是否存在 eval 的调用,依然没有会到父作用域查找,还没有的话,就会在全局作用域查找,任何环节找到的处理方式是一致的。
resolve_scope_var 函数会确定作用域里的变量类别,看是本地变量、全局变量、参数、伪变量。做法是先通过 is_pseudo_var 布尔值来判断是否解决伪变量问题,伪变量就是类似 new.target 和 this 这样的关键字,接下来就是处理作用域局部变量,如果是,生成取局部变量的字节码操作符 OP_get_loc。检查 eval 对象和在参数作用域内的 eval 对象,然后再在更上的作用域进行检查,如果不是当前作用域的变量,生成取自由变量的字节码操作符 OP_get_var_ref ,找出相应的闭包变量,并添加到闭包变量列表里,这样做的原因由自由变量定义来定的,自由变量是不在所使用的声明作用域中进行的声明。resolve_scope_var 函数会将全局变量生成对应的取全局变量的字节码操作符 OP_get_var。由 label_done 来确定是否字节码更新,如果更新 JSFunctionDef 的 label_slots 的 pos2 需要重新更新伪 bc-size。
resolve_variables 函数在遍历到字节码操作符是 OP_scope_get_private_field 时会调用 resolve_scope_private_field 函数,private field 是 js 类里私有变量和方法的定义,目前还在提案的第三个阶段,也就完成前最后一个阶段,这个阶段表示方案已确定,设计上的问题已解决,包括兼容性等问题。private field 是 ES2020 草案提出的,提案相关信息在 Class field declarations for JavaScript 这里,详细方案设计在 Public and private instance fields proposal 这里。QuickJS 在处理 token 阶段在 next_token 函数里碰到 # 字符会调 parse_ident 函数取出定义的变量名出来寄存到 token.u.ident.atom 里,类型设置为 TOK_PRIVATE_NAME,通过 add_private_class_field 函数将变量添加到当前作用域变量列表里。resolve_variables 函数使用 resolve_scope_private_field 函数处理 private field,函数内调用 resolve_scope_private_field1 函数查作用域链的上层来检查是否可处理 private field,如果不行直接返回 -1,可以的话会生成取 private field 的字节码操作符 OP_get_private_field。
当开启 OPTIMIZE 宏定义时,碰到函数结束相关字节码操作符比如 OP_tail_call、OP_tail_call_method、OP_return、OP_return_undef、OP_throw、OP_throw_error、OP_ret 等时 resolve_variables 会调用 skip_dead_code 去掉无用的代码。
OP_label 字节码操作符对应是 js 的 label 语句,label 语句的 ecma262 部分是 Labelled Statements,js 的 label 不像 c 语言有 goto,因此都是配合 break 和 continue 一起使用。
进入作用域的字节码操作符是 OP_enter_scope。会检查进入的作用域中的函数和变量列表,如果变量类型是 JS_VAR_FUNCTION_DECL 或 JS_VAR_NEW_FUNCTION_DECL 会优化生成字节码操作符 OP_put_loc,如果是其他类型就生成 OP_set_loc_uninitialized。在进入作用域时,先处理 js 的 Hoisting,也就是变量提升,变量提升是指在编译阶段会在内存中将变量和函数声明放到执行其他代码前,如果包含了新作用域情况就会复杂些,需要特殊处理,这样说比较抽象。我举个例子,代码 A:
var say = "hi!";
(function() {
console.log(say);
})()按照变量提升规范定义,上面代码会输出 hi,和你想的一样吧。如果换成下面的代码 B:
var say = "hi!";
(function() {
console.log(say);
var say = "see u again!"
})()你先想想上面的代码会输出什么。QuickJS 处理 Hoisting 使用的是 instantiate_hoisted_definitions 函数,instantiate_hoisted_definitions 函数 会先将函数参数和变量加到 Hoisting 里,闭包里会包含所有 enclosing 变量,如果外部有变量环境,在外部为变量创建一个属性,对应的 QuickJS 的 instantiate_hoisted_definitions 函数处理代码如下:
for(i = 0; i < s->global_var_count; i++) {
JSGlobalVar *hf = &s->global_vars[i];
int has_closure = 0;
BOOL force_init = hf->force_init;
for(idx = 0; idx < s->closure_var_count; idx++) {
JSClosureVar *cv = &s->closure_var[idx];
if (cv->var_name == hf->var_name) {
has_closure = 2;
force_init = FALSE;
break;
}
if (cv->var_name == JS_ATOM__var_ ||
cv->var_name == JS_ATOM__arg_var_) {
dbuf_putc(bc, OP_get_var_ref);
dbuf_put_u16(bc, idx);
has_closure = 1;
force_init = TRUE;
break;
}
}
if (!has_closure) {
// 局部和全局不冲突的处理
... // 省略处理
}
if (hf->cpool_idx >= 0 || force_init) {
// 冲突但可初始化的处理
...
}从上面代码可以看出,闭包内定义变量和外部变量相同时,会设置 has_closure 为2,同时设置 force_init 为 FALSE。根据之后代码可以看出这样设置后就不会进行初始化处理,从而能看出闭包内变量是不会初始化的。因此上面举例的代码 B 输出的结果是 undefined。
接下来,如果是函数变量,则先创建闭包,字节码操作符是 OP_fclosure,然后将闭包设置为字节码操作符 OP_put_loc 局部变量。其他情况对该作用域中的变量进行未初始化声明,对应字节码操作符是 OP_set_loc_uninitialized。退出作用域时生成关闭局部变量的 OP_close_loc 字节码操作符。resolve_variables 函数最后会将 DynBuf bc_out 放到 JSFunctionDef 的 byte_code 字段里。
执行完 resolve_variables 后,将 DUMP_BYTECODE 设置为2,可以看到 resolve_variables 函数执行完后的字节码。下一步是执行 resolve_labels 函数。这个阶段是 pass 3
pass3(resolve_labels)
resolve_labels 主要是做 peephole 优化和处理 goto 和 labels。peephole 是指的小指令集,在 QuickJS 里就是 js_parse_program 函数执行后生成的字节码,peephole 顾名思义就是优化 QuickJS 的字节码。对 peephole 优化常用技术有冗余指令删除,包括没用的存和取指令还有不会执行的指令。然后是合并操作,多个操作如果可以用一个操作替代,就进行替换。利用 Algebraic 规则简化和重排指令相关优化。最后就是使用一些特殊的指令来优化。比如 Java 字节码的 aload 指令如果重复执行,可以替换成 dup 指令。另外,如果编译器在调用子程序之前将寄存器保存在堆栈上,返回时进行恢复,多次调用子程序就会产生多余的堆栈,如果后面的调用 不依赖之前的寄存器,多余的 POP/PUSH 都可以删除。再比如汇编里的多次 sh 指令加 ldc1 多存一取可以通过 xor 异或指令减少访问存储操作,可以提升性能。当碰到跳转到跳转的指令时,可以做跳转指令优化,做法是直接跳到目标地址,还可以检查哪些分支不会被跳转也可以做指令删除优化。
下面例子是消除冗余的 load stores。比如下面的代码:
a = b + c;
d = a + e;转为下面的指令:
MOV b, R0 ; 把 b 拷到寄存器
ADD c, R0 ; 添加 c 到寄存器,寄存器现在是 b+c
MOV R0, a ; 把 R0 寄存器拷给 a
MOV a, R0 ; 将 a 拷到寄存器
ADD e, R0 ; Add e to the register, the register is now a+e [(b+c)+e] 将 e 添加到寄存器,现在寄存器是 a+e,a 是 b+c,因此此时寄存器是 b+c+e
MOV R0, d ; 把寄存器拷给 d上面的 MOV a, RO 是多余的,也就是说将 a 拷给寄存器是冗余步骤。
本质上 peephole 优化还是编译阶段的优化,只是处于一般编译后端的优化,由于 QuickJS 解析后是直接生成了字节码,并直接解释执行生成的字节码,所以很多编译的优化技术是用不上的,其他的优化包括有循环优化的诱导变量、强度降低、循环融合、循环反转、循环互换、循环不变的代码运动、循环嵌套优化、循环展开、循环拆分、循环解除切换、软件流水线、自动并行化等;数据流分析的常见的子表达消除、常量折叠、诱导变量识别和消除、死库消除、使用定义链、活变量分析、可用表达方式;SSA-based 的全局值编号,稀疏条件常数传播;Code generation 的寄存器分配、指令选择、指令调度、Rematerialization;函数的尾调用消除、消除中间数据结构的 Deforestation;全局有过程间优化。
静态分析的优化有别名分析、指针分析、形状分析、转义分析、阵列访问分析、依赖性分析、控制流分析、数据流分析等。其他的优化包括消除边界检查、编译时函数执行、消除死代码、内联扩展、跳线程、按配置优化等。peephole 优化属于 base block 级别的优化,llvm 会在 SSA 优化时做 module-scheduling 和 peephole 优化。
下面我们来看看 resolve_labels 函数是怎么做 peephole 优化的。
resolve_labels 函数先初始化伪变量,比如前面提到的 new.targe 和 this,还有 home_object、this.active_func 变量,其中 this 变量在派生类的构造函数中是没有初始化的。随后会初始化参数变量、当前函数引用、变量环境对象。这些都会生成 OP_special_object 字节码操作符,并根据不同变量类型生成对应的值,类型定义枚举是 OPSpecialObjectEnum。
接下来就是遍历字节码,针对不同字节码指令进行优化。
OP_line_num 是用于调试的行号,记在 line_num 整型变量里。使用 JSOpCode 结构体计算栈的大小,遍历指令集时,堆栈大小通过 oi->n_push - n_pop 获取。OP_label 操作符最终生成字节码的偏移量会被确定。OP_goto、OP_gosub、OP_if_true、OP_if_false 和 OP_label 一样会确定最终偏移量,通过 find_jump_target 函数找到目标 label,通过 update_label 函数移除 jump 指令。
遇到 OP_null,通过 code_match 函数来看前一个字节码操作符如果是 OP_strict_eq,那么就可以优化成 OP_is_null。对于 OP_push_i32,如果前字节码操作符是 OP_neg,会用 push_short_int 函数在 val 前加上 - 符号来精简指令。OP_push_i32、OP_push_atom_value 和 OP_drop 指令紧相邻的话可以都移出。
另外OP_to_propkey、OP_to_propkey2、OP_undefined、OP_insert2、OP_dup、OP_get_loc、OP_get_arg、OP_get_var_ref、OP_put_loc、OP_put_arg、OP_put_var_ref、OP_post_inc、OP_post_dec、OP_typeof 等字节码操作符进行优化,相同的处理通过 goto 跳到 label 标签的方式来处理。有shrink、has_label、has_goto、has_constant_test 等 label 来统一优化逻辑。主要是将长的操作数转成短操作数,合并指令,还有将操作数移到操作符里把长的字节码指令转换成短指令。
resolve_labels 函数最后还会遍历一遍 s->jump_slots 做更多的跳转指令的优化。
resolve_labels 函数执行完后,pass 3 阶段 js_create_function 还需要调用 compute_stack_size 函数广度优先方式来计算堆栈大小。compute_stack_size 函数对会对栈有影响的指令使用 ss_check 检查字节码的buffer 是否有字节码缓冲区溢出、堆栈溢出或堆栈大小不一致问题,并在 s->stack_level_tab 里记录每个位置的栈大小,然后用 js_resize_array 更新 s->pc_stack 数组。
总的来说从脚本生成最终字节码有两个阶段,第一个阶段是脚本解析,这个阶段会先将生成的 token 使用解析各种语句和表达式的函数直接在解析时生成 pass 1字节码,然后生成函数定义树。第二阶段是优化阶段,主要是 resolve_variables 函数和 resolve_labels 函数。resolve_variables 会优化变量,比如全局变量、本地变量、自由变量、参数等,将作用域操作简化成对应定义变量种类字节码。resolve_labels 主要是对跳转相关的优化,比如通过确定最终跳转地址来优化中间跳转。
总的来看,js_create_function 函数整体依赖如下图:
如上图所示,在创建函数时,如果当前函数使用的变量是上一级函数的局部变量,就会将上一级函数的局部变量添加到上一级函数的闭包变量的列表里。
解释执行 JS_EvalFunctionInternal
__JS_EvalInternal 函数执行完 js_create_function,还会装载使用 js_resolve_module 函数处理当前模块所需所有模块。最后就是要开始解释执行函数对象 fun_obj 了。
函数对象字节码信息结构体是 JSFunctionBytecode,js 函数在运行时的数据结构是 JSFunctionBytecode,创建函数就是初始化 JSFunctionBytecode 结构体,并设置里面所需的字段,这个过程就是将扫描代码生成的临时 JSFunctionDef 对应到 JSFunctionBytecode 中,由 js_create_function 函数负责处理。JSFunctionBytecode 结构体里的 byte_code_buf 字段是函数对象自己字节码的指针,vardefs 里是函数的参数和局部变量;closure_var 是用于存放外部可见的闭包变量,closure_var 通过 add_closure_var 函数进行添加,add_closure_var 函数会把要用到的变量添加成闭包变量,通过 get_closure_var2 函数往上层级递归给每层级函数添加闭包变量,直到找到目标函数;stack_size 是指堆栈的大小,stack_size 主要作用是为初始化栈时能够减少内存占用;cpool 是函数内常量池。
QuickJS 解释执行的方式有五种,flag 定义了 JS_EVAL_FLAG_STRICT 表示按照 strict 模式执行,JS_EVAL_FLAG_STRIP 表示会按 strip 模式执行,JS_EVAL_FLAG_COMPILE_ONLY 指只生成函数对象,不解释执行,但返回的结果的结果是带有字节码或 JS_TAG_MODULE 的函数对象,这个函数对象也是可以使用 JS_EvalFunctionInternal 来解释执行的。JS_EVAL_FLAG_BACKTRACE_BARRIER 表示出现问题进行回溯时不需要之前堆栈帧。
QuickJS 解释执行的函数是 JS_EvalFunctionInternal,JS_EvalFunctionInteral 函数会用 JS_VALUE_GET_TAG 来看函数对象是带字节码的 JS_TAG_FUNCTION_BYTECODE 还是 JS_TAG_MODULE。
如果是 JS_VALUE_GET_TAG 是 JS_TAG_MODULE 表示当前函数对象是一个模块,因此需要按照模块的方式处理,JS_EvalFunctionInternal 函数会先调用 js_create_module_function 找出模块中导出的变量,js_create_module_function 函数调用链如下:
js_create_module_function -> js_create_module_bytecode_function -> js_create_module_var执行完 js_create_module_function,会调用 js_link_module 函数,js_link_module 函数会处理所有要导入的变量,将其保存在 JSModuleDef 的 req_module_entries 数组里供解释执行时使用。然后 js_link_module 还会检查间接的导入。最后将导出的变量保存在模块 JSExportEntry 的 export_entries 数组里,然后使用 JS_Call 函数执行导出的这些全局变量的初始化。
JS_EvalFunctionInteral 函数对于 tag 是 JS_TAG_FUNCTION_BYTECODE 的函数对象会调用 js_closure 和 JS_CallFree 两个函数进行字节码的解释执行。
js_closure 函数最终会生成函数闭包对象,这个对象会设置属性。js_closure 还会生成设置变量属性,比如来源和类型,并存在当前函数的 var_refs 里,变量处理使用的是 js_closure2 函数。js_closure 先使用 JS_NewObjectClass 将 func_obj 类型由 js_closure2 函数会遍历闭包变量,通过 get_var_ref 函数来看闭包变量来自哪一层上下文,最后存在当前函数的 JSVarRef 里,JSVarRef 表变量引用。在 js_closure2 函数中,当发现自由变量的 is_local 为 false 也就是变量来自外层,就会直接从 js_closure2 函数传入的上层的参数 cur_var_refs 里取出变量,存在 var_refs 里,当 JS_CallInternal 执行时当遇到 OP_get_var_ref 字节码操作符时函数闭包会直接通过索引从 var_refs 里取出变量并通过 JS_DupValue 将引用加1,同时把引用加到栈顶。OP_put_var_ref 使用 set_value 函数将栈顶值更新到 var_refs 对应索引位置,并 pop 栈顶值。js_function_set_properties 函数设置属性。
创建了闭包环境,接下来执行 JS_Call 函数,JS_Call 函数会逐个执行字节码的指令。JS_Call 会调用 JS_CallInternal 函数,QuickJS 的字节码执行架构是基于栈指令的,JavaScriptCore 是基于寄存器解释执行的,关于 JavaScriptCore 的详细介绍可以参看我以前的文章《深入剖析 JavaScriptCore》。JSStackFrame 是模拟栈,在一个运行时只会有一个模拟栈在使用,generator 通过保存一个还在运行中没结束的栈来达到挂起的目的。
JS_CallInternal 会对字节码的每条指令都进行解释执行。会先为变量、存放数据的栈还有参数等进行内存的分配。然后再对每条字节码指令一个一个进行解释执行,指令类型有 push 开头的入栈指令。goto、if 打头的跳转指令。call 开头的调用指令。交换类的指令有 swap、nip、dup、perm、drop 等。用于计算的指令有加减乘除、一元计算、逻辑计算等。处理指令时生成 JSValue 用的是 JS_MKVAL 和 JS_MKPTR 这两个宏。新建字符串类型用的是 JS_NewString,对象是 JS_NewObject,数组是 JS_NewArray等。类型转换使用的函数有 JS_toString 来转换成字符串类型,JS_ToNumeric 转换成数字,JS_ToObject 转换成对象等。
内存相关指令有 JS_DupValue 函数对 JSRefCountHeader 进行引用计数加1,JS_FreeValue 对引用计数减1,触发GC使用 js_trigger_gc 函数,添加一个 GC 对象使用 add_gc_object 函数,移出使用 remove_gc_object 函数。触发 GC 的时机是可以看哪里调用了 JS_NewObjectProtoClass 这个函数,JS_NewObjectProtoClass 函数会调用 JS_NewObjectFromShape 函数会触发 js_trigger_gc 函数,js_trigger_gc 函数会判断内存大小是否大于 malloc_gc_threshold,超过就会调用 JS_RunGC 函数。对应判断代码如下:
force_gc = ((rt->malloc_state.malloc_size + size) >
rt->malloc_gc_threshold);如果定义了 FORCE_GC_AT_MALLOC 这个宏,每次都会调用 JS_RunGC 函数。JS_RunGC 函数会调用三个函数,代码如下:
void JS_RunGC(JSRuntime *rt)
{
/* decrement the reference of the children of each object. mark =
1 after this pass. */
gc_decref(rt);
/* keep the GC objects with a non zero refcount and their childs */
gc_scan(rt);
/* free the GC objects in a cycle */
gc_free_cycles(rt);
}如上代码中,gc_decref 函数会遍历 gc_obj_list 减少每个对象的子对象的引用,减到0的会存到 temp_obj_list 里,gc_scan 函数会调用 gc_scan_incref_child 将子对象引用加1,保持 GC 对象计数和他们子对象。gc_free_cycles 函数在周期中释放 GC 对象,JS_GC_OBJ_TYPE_JS_OBJECT 和 JS_GC_OBJ_TYPE_FUNCTION_BYTECODE 类型的和 JSValue 相关的会释放,其他的会删除。
总的说来,GC 是通过 add_gc_object 函数调用开始的,调用了 add_gc_object 函数的函数都是会涉及到 GC,比如 JS_CallInternal、js_create_function、JS_NewObjectFromShape 等函数。其中 JS_DupValueRT 会对引用计数做加1操作。free_var_ref 和 JS_FreeValueRT 函数会对引用计数减1,当减到0时会调用 JS_FreeValueRT 释放移除引用对象。
下面详细讲解不同类型指令怎么解释执行的。
pc 指向当前正在执行的字节码地址。sp 指向堆栈,堆栈存着运行时的数据,通过 pc 指向的操作指令进行堆栈的入栈和出栈操作。
OP_push_i32 使用 JS_NewInt32 将当前字节码的值转成 JSInt32,sp++ 将值入栈。通过 quickjs-opcode.h 文件可以看到 OP_push_i32 相关定义:
DEF( push_i32, 5, 0, 1, i32)上面OPCode 定义中第一个参数 id 表示 OPCode 的名字,第二个 size 表示 OPCode 的字节大小,第三个 n_pop 表示出栈元素的数量,第四个参数 n_push 表示入栈元素的数量,第五个参数 f 表示字节码的类型。第二个参数可以看到 OP_push_i32 的大小是5字节,那么下个字节码需要 pc 指针增加4 加上通过栈操作得到的偏移值1加在一起是5,因此可以移到下一个指令。
对于8位以下整数,使用的是 OP_push 加位数的字节码,大小是1个字节。使用 JS_NewInt32 进行类型转换然后入栈。8位整数使用的是 OP_push_i8,8位整数放在第2个字节里,16位整数需要2个字节,所以对应的字节码是 OP_push_i16。OP_push_empty_string 会将 JS_ATOM_empty_string 这个 atom 使用 JS_AtomToString 转成 JSValue 入栈。OP_push_atom_value 会将 atom 的值转成对应字符串 JSValue 进行入栈。当遇到 OP_undefined、OP_null、OP_push_false、OP_push_true时将对应的特殊值定义,比如 JS_UNDEFINED 和 JS_NULL 入栈。
当字节码操作符是 OP_fclosure 或 OP_fclosure8 闭包时,会调用 js_closure 去创建闭包解释环境,解释执行包内指令。闭包就是函数和周边状态的引用合在一起的组合,内层可以访问外层作用域。比如下面这个例子:
function add(a) {
return function(b) {
return a + b;
}
}上面代码可以看出,add 函数内执行加法的函数能够访问到外层的入参变量 a,从而和返回函数的入参变量 b 进行加法运算,返回相加后的值。解析时,会生成 scope_get_var 和 scope_put_var,在执行 resolve_variable 函数时会将解析后的指令转换成局部变量 get_loc 和 put_loc,自由变量 get_var_ref 和 put_var_ref。获取局部和外层变量使用的是 get_closure_var 函数,get_closure_var 函数会将当前函数所要用的变量记录在函数定义对象 JSFunctionDef 的 closure_var 里。变量结构是 JSClosureVar,表示闭包变量信息,记录闭包里变量的各种信息,比如变量的索引、名字等,其字段 is_local 如果是 true 表示变量是局部变量,false 表示是上层变量。在执行 OP_fclosure 字节码操作符时,会根据 JSFunctionDef 的 closure_var 生成 var_refs,也就是自由变量的引用,获取这些自由变量的字节码操作符是 OP_get_var_ref,是通过 var_refs 里的索引获取。
字节码操作符操作 OP_push_this 分为普通处理和严格模式处理,普通处理是直接将this指向指针入栈,再对引用计数加1。严格模式对于 NULL 和未定义的 this 会将全局对象指针入栈,如果 this 是一个对象,就按照普通模式处理,其他类型会尝试使用 JS_ToObject 转成对象,如果有异常则会 goto 到 exception label。
OP_object 表示需要在运行时创建一个对象,也就是不在编译时创建,QuickJS 使用的是 JS_NewObject 函数(最终调用的是 JS_NewObjectProtoClass 函数),创建 JSShape 的 JSValue,文章前面也说了,shape 是一种避开繁琐字节码处理更快创建函数对象的方法。另外针对一些定义在 OPSpecialObjectEnum 枚举里特殊的对象创建的字节码操作符是 OP_special_object,参数和变量类型最终都会调用 JS_NewObjectProtoClass 函数创建 shape 对象,this 和 home_object 会返回对应的指针,import 会导入模块。
drop、nip 和 dup 开头的字节码是对 sp 堆栈里的顶层值进行删除和复制。insert 开头的字节码是加入对象指针,perm 是交换对象和值的栈层级。swap 开头的是交换值的栈层级,rot 是整体翻转。
call 开头的字节码操作符和 OP_eval 会递归调用 JS_CallInternal 函数进行对应位置的执行。OP_call_constructor 会调用 JS_CallConstructorInternal 函数执行构造函数指令,最终函数的指令也是通过 JS_CallInternal 解释执行。
创建数组,使用的是 OP_array_from,对应函数是 JS_NewArray,JS_NewArray 函数会执行 JS_NewObjectFromShape 函数,参数设置类型为 JS_CLASS_ARRAY,JS_NewObjectFromShape 会创建一个数组对象 Shape。
OP_apply 会调用 js_function_apply 函数,如果没有参数就会直接调用 JS_Call 解释执行,有参数的话使用 build_arg_list 函数获取参数列表,对于构造函数 js_function_apply 会使用 JS_CallConstructor2 函数执行,其他的直接使用 JS_Call 执行。
OP_eval 和 OP_apply_eval 会检查 eval 执行参数,如果没有会调用 JS_EvalObject 函数,JS_EvalObject 函数会依据 val 参数是否是字符串决定是直接返回 val 地址还是调用 JS_EvalInternal 解析字符串。
OP_regexp 会使用 js_regexp_constructor_internal 函数创建一个正则函数对象放到堆栈中。OP_get_super 会使用 JS_GetPrototype 函数来获取原型对象放到堆栈中。OP_import 是动态获取 import 内容,使用 js_new_promise_capability 函数检查是否是 promise,然后调用 JS_CallConstructor 函数执行。
对于全局变量存取字节码,是调用的 JS_GetGlobalVar 和 JS_SetGlobalVar 函数。全局变量和函数的定义使用的是 JS_DefineGlobalVar 和 JS_DefineGlobalFunction 函数。局部变量和参数 put 使用的是 JS_DupValue 函数入栈,set 使用的是 set_value 函数。对全局变量、局部变量和参数后加 check 的指令是在入栈或设置值前会用 JS_IsUninitialized 函数来判断他们是否是 JS_TAG_UNINITIALIZED,在他们之前加 make 表示在运行时添加对象,会先用 JS_NewObjectProto 创建含 JSShape 的 JSValue 入栈,在栈里再取出 JSObject 设置变量引用,再入栈变量的 atom。OP_close_loc 用的是 close_lexical_var 来取消局部变量的引用。
goto 这样的字节码指令在 quickjs-opcode.h 里定义的值类型都是 label,通过取出指令对应 label 的偏移量,让 pc 加上偏移量直接跳转到对应字节码。OP_if_true 有五个字节,因此 pc += 4 为下个指令指针地址。从 sp 栈里取出栈顶 op,使用 JS_VALUE_GET_TAG 取出 tag 值,判断小于 JS_TAG_UNDEFINED 就执行下个指令。这里 JS_TAG_UNDEFINED 和其他 tag 类型都定义在一个匿名枚举里,有引用计数的类型都是负数,比如 JS_TAG_BIG_INT -10、JS_TAG_STRING -7、JS_TAG_MODULE -3、JS_TAG_FUNCTION_BYTECODE -2、JS_TAG_OBJECT -1。整数、布尔值、NULL 类型也满足小于 JS_TAG_UNDEFINED 条件。OP_if_false 执行下条指令逻辑和 OP_if_true 相反。
for 遍历语法关键字相关字节码如下:
DEF( for_in_start, 1, 1, 1, none)
DEF( for_of_start, 1, 1, 3, none)
DEF(for_await_of_start, 1, 1, 3, none)
DEF( for_in_next, 1, 1, 3, none)
DEF( for_of_next, 2, 3, 5, u8)从上述字节码定义里可以看到,定义的字节码对应的是 JavaScript 的 for…in 和 for…of 语法。for…in 是用在对象的遍历,会遍历所有对象以字符串为键的枚举属性,也包括继承的属性。for…of 语句是在可迭代对象上创建迭代的循环,这样的对象有字符串、数组、参数、NodeList、TypedArray、Map、Set等。for…in 会通过 build_for_in_iterator 函数来处理,for…of 会用 JS_GetIterator 函数里的 JS_CreateAsyncFromSyncIterator 函数创建所需的迭代的循环。
获取属性的字节码操作符是 OP_get_field,JS_CallInternal 函数会调用的是 JS_GetProperty。OP_put_field 是设置类属性,JS_CallInternal 函数会调用 JS_SetPropertyInternal 函数。创建一个新属性使用的是 OP_define_field 字节码操作符。私有属性的获取、设置、定义字节码调用的函数分别是 JS_GetPrivateField、JS_SetPrivateField、JS_DefinePrivateField。属性获取会调用的是 find_own_property 函数,设置属性会在调用属性基础上多调用 set_value 函数对属性值进行设置,定义会多调用 add_property 函数,add_property 函数会先检查是否先前已经定义过,如果没有就会调用 add_shape_property 函数新建属性。删除属性会调用 delete_property 函数。
私有符号 private symbol 对应的字节码操作符是 OP_private_symbol,调用的是 JS_NewSymbolFromAtom 函数,参数 atom_type 为 JS_ATOM_TYPE_PRIVATE。private symbol 提案和 private field 的提案一样都在完成的最后一个阶段。以前实例的属性是可以被外部的代码修改,没法保护,一些库会用下划线字符作为前缀标记属性为私有,TypeScript 靠编译器来检查私有属性否会被外部修改。另一种方法就是内部使用闭包隐藏属性,把属性和外部代码的修改隔离开,缺点就是每个实例都要额外为私有的属性创建闭包。private symbol 语法能起到保护私有属性的作用,在标准和语法层面支持,而不依赖三方定制编译规则或额外加闭包保护。编写 private symbol 代码如下:
var s1 = Symbol('s');
var s2 = Symbol('s');
console.log("s1 是否等于 s1: " + (s1 === s2));上面代码执行的结果是 false,表示即使 Symbol 参数是相同字符串,返回的 symbol 都是唯一的。private symbol 字节码处理函数 JS_NewSymbolFromAtom 参数 atom_type 对应的是 JS_ATOM_TYPE_PRIVATE,JS_NewSymbolFromAtom 函数调用链是 JS_NewSymbolFromAtom -> JS_NewSymbol -> __JS_NewAtom, __JS_NewAtom 函数对于 atom_type 是 JS_ATOM_TYPE_PRIVATE 相关处理代码如下:
enum {
JS_ATOM_TYPE_STRING = 1,
JS_ATOM_TYPE_GLOBAL_SYMBOL,
JS_ATOM_TYPE_SYMBOL,
JS_ATOM_TYPE_PRIVATE,
};
...
if (atom_type < JS_ATOM_TYPE_SYMBOL) {
// 看看是否已经有相同的字符串
...
// 尝试定位已注册的 atom
len = str->len;
// 计算 hash 值
h = hash_string(str, atom_type);
h &= JS_ATOM_HASH_MASK;
// h1 的作用是用来保证 h 是在 hash_size 的范围里
h1 = h & (rt->atom_hash_size - 1);
i = rt->atom_hash[h1];
// 判断是否有相同的 atom 在 atom_array 里
while (i != 0) {
p = rt->atom_array[i];
if (p->hash == h &&
p->atom_type == atom_type &&
p->len == len &&
js_string_memcmp(p, str, len) == 0) {
if (!__JS_AtomIsConst(i))
p->header.ref_count++;
goto done;
}
i = p->hash_next;
}
} else {
// 处理 symbol 类型
h1 = 0;
if (atom_type == JS_ATOM_TYPE_SYMBOL) {
h = JS_ATOM_HASH_SYMBOL;
} else {
// private symbol 在后面的处理和 symbol 一样
h = JS_ATOM_HASH_PRIVATE;
atom_type = JS_ATOM_TYPE_SYMBOL;
}
}
...从上面 QuickJS 对于 private symbol 的处理可以看出,依据枚举定义小于 JS_ATOM_TYPE_SYMBOL 类型的是字符串和全局 symbol,他们会做去重处理,会检查先前是否有注册,如果有就会复用,对于 symbol 类型无论是 symbol 还是 private symbol 都会按照不复用,每个都使用新建的方式来处理。
设置对象操作符是 OP_set_name 和 OP_set_name_computed。其中 OP_set_name_computed 用来设置计算的属性名,计算的属性名语法是在 ECMAScript 2015 标准里开始支持的。该语法允许在[]中加入表达式,这个表达式会将计算结果作为属性名。比如下面 js 代码:
const num = 1
const o = {['k' + num]: 1}这样就可以直接使用 o.k1 来获取 k1 键对应的值1。计算的属性名也可以用模板字元,代码如下:
const num = 1
const o = {[`k${num}`]: 1}QuickJS 对对象设置和计算的属性名对象设置的函数分别是 JS_DefineObjectName 和 JS_DefineObjectNameComputed,他们都会通过 JS_isObject 函数检查是否是对象类型,js_object_has_name 函数判断是否是有键名对象,JS_DefinePropertyValue 函数设置属性值。不同的是计算的属性名会调用 js_get_function_name 来处理属性名计算问题。
定义方法字节码操作符是 OP_define_method,先从堆栈取出持有方法的对象,然后再调用 js_method_set_properties 函数设置方法为对象的属性,然后通过 JS_DefineProperty 来定义设置的属性。
定义类使用的是 js_op_define_class 函数,js_op_define_class 会先处理有父类和无父类的情况,调用 JS_NewObjectProtoClass 函数创建类对象,返回 JSValue,将这个值传入 js_closure2 获取类的详细信息,包括类对应的字节码、home_object、变量等。js_method_set_home_object 函数设置 home_object,使用 JS_DefinePropertyValue 来定义属性值,计算的属性用 JS_DefineObjectNameComputed 函数,构造函数属性必须是第一个,构造函数属性可以被计算的属性覆盖。
定义数组元素使用字节码操作符是 OP_define_array_el,调用 JS_DefinePropertyValueValue 函数,插入数组元素用的是 OP_append,调用 js_append_enumerate 函数。获取对象的属性和设置对象的属性函数分别是 JS_GetPropertyValue 和 JS_SetPropertyValue 函数。对象的属性其实在 js 语法中被包装成不同的概念,比如数组的属性其实就是数组的元素,因此下面这些字节码都会用到获取对象属性和设置对象属性的函数:
DEF( get_array_el, 1, 2, 1, none)
DEF( get_array_el2, 1, 2, 2, none) /* obj prop -> obj value */
DEF( put_array_el, 1, 3, 0, none)
DEF(get_super_value, 1, 3, 1, none) /* this obj prop -> value */
DEF(put_super_value, 1, 4, 0, none) /* this obj prop value -> */
DEF( get_ref_value, 1, 2, 3, none)
DEF( put_ref_value, 1, 3, 0, none)OP_add 是加指令字节码操作符,OP_add 会先从 sp 栈里取出待相加两个数,使用 JS_VALUE_IS_BOTH_INT 和 JS_VALUE_IS_BOTH_FLOAT 函数判断两个数是否类型一样,相同的话可以直接相加,整数的话先使用64位计算,然后用32位比较是否相同,不同的话 goto 到 add_slow label 中进行计算。int 和 float 外的比如 big int 等科学计算也 goto 到 add_slow 中计算,add_slow label 里实际调用的是 js_add_slow 函数。减、乘、除的字节码操作符对应的分别是 OP_sub、OP_mul、OP_div,其实现和加字节码操作符类似,不同的是他们的复杂计算都会 goto 到 binary_arith_slow label,调用的是 js_binary_arith_slow 函数。一元计算字节码操作符 OP_plus、OP_neg、OP_inc、OP_dec、OP_inc_loc、OP_dec_loc,他们的复杂计算会调用 js_unary_arith_slow 函数。逻辑计算 OP_shl、OP_sar、OP_and、OP_or、OP_xor,复杂计算会调用 js_binary_logic_slow 函数。
OP_to_object 字节码操作符会根据栈中定义对象类型来将一些非对象类型转为对象,调用的是 JS_ToObject 函数,内主要是调用 JS_NewObjectFromShape 函数来处理,类型 class_id 来区分不同的数据类型。OP_to_propkey 和 OP_to_propkey2 是将键值的类型转为键可支持的字节码操作符,其主要处理就是除了整型、字符串和 symbol 外类型通过 JS_ToStringInternal 函数转化为字符 JSValue 类型。